 그랩
그랩안녕하세요. 데이터 플랫폼 팀의 그랩입니다.
데이터 플랫폼팀은 “쏘카 내부의 데이터 이용자가 비즈니스에 임팩트를 낼 수 있도록 소프트웨어 엔지니어링에 기반하여 문제를 해결합니다”라는 미션을 기반으로 인프라, 데이터 파이프라인 개발, 운영, 모니터링, 데이터 애플리케이션 개발, MLOps 등의 업무를 맡고 있습니다. 팀 구성원들은 모두가 소프트웨어 엔지니어라는 사명감을 가지고 개발뿐만 아니라 Ops에 대한 이해와 책임감을 가지고 업무에 임하고 있습니다.
본 글은 “신사업 FMS 데이터 파이프라인 구축기”의 1편으로 쏘카의 신사업 FMS(Fleet Management System) 서비스의 PoC 데이터 파이프라인을 구축한 경험을 소개하려고 합니다. PoC 제품 출시까지 시간이 제한된 상황에서 간결하고 관리 비용을 최소화할 수 있는 방향으로 아키텍처를 설계하였습니다. 본 글에서는 IoT 데이터 파이프라인을 구성하는 주요 요소들과 기술 스택을 선택한 이유들도 함께 소개 드리겠습니다.
다음과 같은 분들이 읽으면 좋습니다.
- 실시간 데이터 파이프라인에 관심이 있는 소프트웨어 엔지니어
- AWS 기반의 데이터 엔지니어링 환경 구축에 관심이 있는 소프트웨어 엔지니어
- Kafka Connect를 활용한 메시지 소비에 관심이 있는 소프트웨어 엔지니어
- 쏘카의 데이터 엔지니어가 무슨 일을 하는지 궁금한 모든 이들
목차는 아래와 같습니다.
- FMS 데이터 파이프라인 소개
- 스트리밍 파이프라인 : IoT Core에서 Kafka로
- 스트리밍 파이프라인 : Kafka Sink Connector로 변형/적재하기
- 배치 처리 플랫폼 : 반정형 데이터가 분석/집계 되어 적재되기까지
- 마무리
분량 관계상 Kafka에 대한 기본적인 설명이나 주요 컴포넌트들의 상세한 구현 설명 및 코드는 생략하겠습니다. 글을 읽으시면서 궁금한 점에 대해 편하게 댓글 남겨주시면 확인 후 답변드리겠습니다.
1. FMS 데이터 파이프라인 소개
1.1. FMS 서비스 소개

FMS는 Fleet Management System의 약자로, IoT 단말기를 차량에 부착해 데이터 기반으로 차량을 관제하고 운행 정보들을 분석하여 차량의 관리 및 운영을 효율화하는 차량 관제 플랫폼입니다. FMS 서비스를 통해 고객사는 데이터 수집/분석된 차량들의 운영을 효율화하고 비용 절감, 안전 강화 등의 기대효과를 취할 수 있습니다. 2022년 6월부터 PoC 개발을 시작으로, 현재 주요 고객사들을 대상으로 PoC 서비스를 성공적으로 런칭하여 운영 중에 있습니다. 더 자세한 내용은 해당 기사를 참고해 주세요.
1.2. FMS 스트리밍/배치 파이프라인 소개
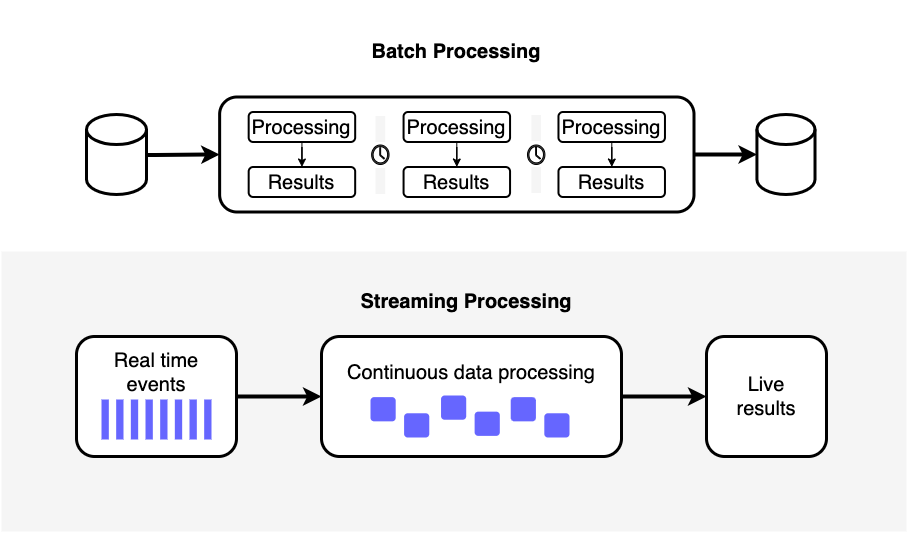 배치 파이프라인과 스트리밍 파이프라인
배치 파이프라인과 스트리밍 파이프라인
보통 비즈니스/분석 요구사항에 맞게 데이터 파이프라인을 구축하다 보면 배치와 스트리밍에 대한 고민을 자연스럽게 하게 됩니다.
배치는 특정 시간 범위의 데이터를 일괄로 처리하는 기술을 뜻합니다. 배치로 데이터를 처리하기 위해선 보통 배치 잡을 오케스트레이션을 해주는 툴과 대용량 데이터를 처리하기 위한 환경을 구성합니다.
스트리밍은 생성되는 데이터를 실시간으로 처리하는 기술을 뜻합니다. 실시간으로 생성되는 데이터(메시지)를 일시적으로 저장하는 데이터베이스로 메시지 큐를 많이 활용합니다. 이는 대표적으로 Kafka, Redis, RabbitMQ 등의 오픈소스와 클라우드 서비스인 Kinesis, SQS, PubSub 등이 있습니다.
FMS 프로젝트는 기본적으로 실시간 차량 관제와 같이 실시간 데이터에 대한 요구사항과 차량 운영을 위한 분석/집계된 배치 데이터의 요구사항이 모두 존재하였습니다. 따라서 스트리밍과 배치 파이프라인을 모두 구축해야 했습니다. 스트리밍 파이프라인은 MSK(Kafka)를 중심으로 Kafka Connect on EKS(Kubernetes)를 데이터 처리/적재 컴포넌트로 구성하였으며 차량 단말기의 메시지를 수신하기 위한 브로커로 IoT Core를 채택하였습니다. 배치 파이프라인은 MWAA(Airflow)와 데이터 레이크(S3 + Glue Catalog + Redshift Spectrum) 환경으로 구성하였습니다.
1.3. 주요 컴포넌트 소개
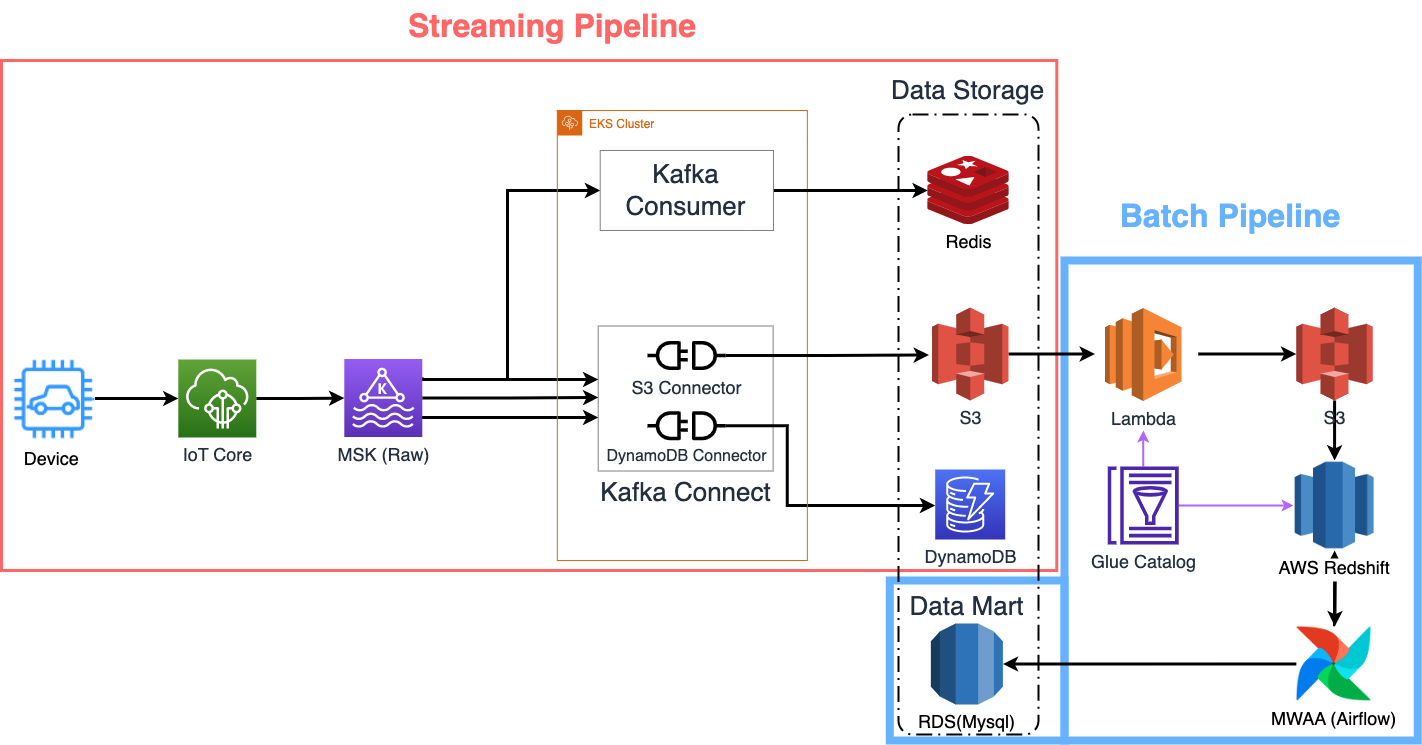 FMS 데이터 파이프라인 아키텍처 (배치/스트리밍)
FMS 데이터 파이프라인 아키텍처 (배치/스트리밍)
이번 챕터에서는 FMS 데이터 파이프라인을 구성하는 주요 컴포넌트들을 가볍게 소개 드리려고 합니다. FMS 데이터 파이프라인은 크게 스트리밍 파이프라인과 배치 파이프라인으로 나눠집니다.
참고: 본 글에서는 실시간 조회에 사용되는 Redis와 관련 서비스(Consumer, Backend API 등)은 따로 다루지 않습니다.
스트리밍 파이프라인
실시간 파이프라인을 구성하는 주요 컴포넌트는 다음과 같습니다.
IoT Core
AWS IoT Core는 IoT 단말기의 메시지를 송/수신하는 메시지 브로커로 내부는 MQTT 프로토콜로 구현되어 있습니다. Fully Managed Service로 인프라 관리가 필요 없고 보안이나 단말기 관리 등의 이점이 있어 현재 쏘카 서비스와 FMS 모두 IoT Core를 차량 데이터의 매개체로 사용하고 있습니다.
MSK(Managed Streaming for Kafka Service)
보통 실시간 데이터 파이프라인 아키텍처를 설계할 때 메시지 브로커인 Kafka를 많이 선택합니다. Kafka는 분산 스트리밍 플랫폼으로 실시간으로 들어오는 데이터를 확장성 있게 처리할 수 있어 많은 기업들이 메시지 브로커로 사용하고 있습니다.
AWS에서 제공하는 MSK(Managed Streaming for Kafka Service)는 Kafka를 완전 관리형으로 제공해 주고 보안, 모니터링 등을 폭넓게 지원해 줘서 사용자 측에서 관리 비용을 아끼고 애플리케이션 개발에 집중할 수 있습니다.
Kafka Connect
Kafka Topic에 저장된 메시지들을 데이터베이스/스토리지에 적재하기 위해서는 이를 처리하는 애플리케이션이 필요합니다. 일반적으로 각 프로그래밍 언어에서 이를 구현할 수 있도록 Consumer 라이브러리가 있습니다.
Kafka Connect는 Consumer를 메시지 추출(Source)과 적재(Sink)에 적절하게 추상화한 프레임워크입니다. 실제로 작업을 수행하는 Kafka Connector들을 Kafka Connect에 등록하여 관리하게 되는 구조라고 보시면 됩니다. 사용자는 이를 이용해 손쉽게 Kafka의 메시지를 추출/적재할 수 있습니다.
이 외에도 실시간 집계 및 준 실시간 데이터 조회 목적으로 데이터베이스로는 DynamoDB를, 데이터 레이크 목적으로는 S3을 사용하고 있습니다.
배치 파이프라인
다음은 배치 처리를 위한 컴포넌트입니다.
Lambda
Lambda는 AWS의 서버리스 컴퓨팅 플랫폼으로 API 서버 형태로 활용이 가능할 뿐만 아니라 AWS 리소스(S3, Kafka, Kinesis 등)의 이벤트 기반으로 동작시킬 수 있어 활용 범위가 굉장히 넓습니다.
현재 배치 분석 집계를 할 때 S3의 적재된 Raw 파일을 타입에 맞게 분리하여 Parquet로 변환하는 용도로 Lambda를 사용하고 있습니다.
Redshift
Redshift는 AWS의 데이터 웨어하우스 서비스입니다. 표준 SQL(ANSI)를 따르며 대용량 데이터 처리를 빠르게 처리할 수 있어 데이터 웨어하우스 솔루션으로 AWS Athena(Presto 기반)와 함께 많이 사용되고 있습니다.
저희는 Redshift 운영 비용을 낮추기 위해 Serverless를 사용하고 S3에 적재된 Parquet를 읽을 수 있도록 Redshift Spectrum 기능을 도입하였습니다.
Glue Data Catalog
Glue는 AWS의 완전 관리형 ETL 도구입니다. Glue는 크게 Data Catalog와 Data Integration and ETL로 나뉘는데, 이번에 저희가 주로 사용한 서비스는 Data Catalog입니다. Data Catalog는 비정형/반정형 데이터들을 SQL 형태로 조회할 수 있도록 메타 정보들(테이블, 파티션 등)을 저장하는 메타 스토어로 활용됩니다.
현재 S3에 Parquet로 데이터를 저장할 때 스키마를 추론하는 용도와 Redshift Spectrum에서 외부 테이블 형태로 사용할 때 Glue Catalog를 활용하고 있습니다.
Airflow
Airflow는 Airbnb에서 개발한 워크플로 관리 오픈소스로 현재 많은 기업에서 데이터 파이프라인을 자동화할 때 사용하는 툴입니다. 스케줄링, 재처리 기능, 외부와 연동해 주는 다양한 3rd Party 라이브러리, 직관적인 UI 등을 제공해 줘서 많은 기업들이 배치 처리를 할 때 사용하고 있습니다.
현재 RedshiftSQLOperator를 활용해서 데이터 마트 데이터 집계를 스케줄링하는 데 사용하고 있습니다.
1.4. 데이터가 흐르는 순서
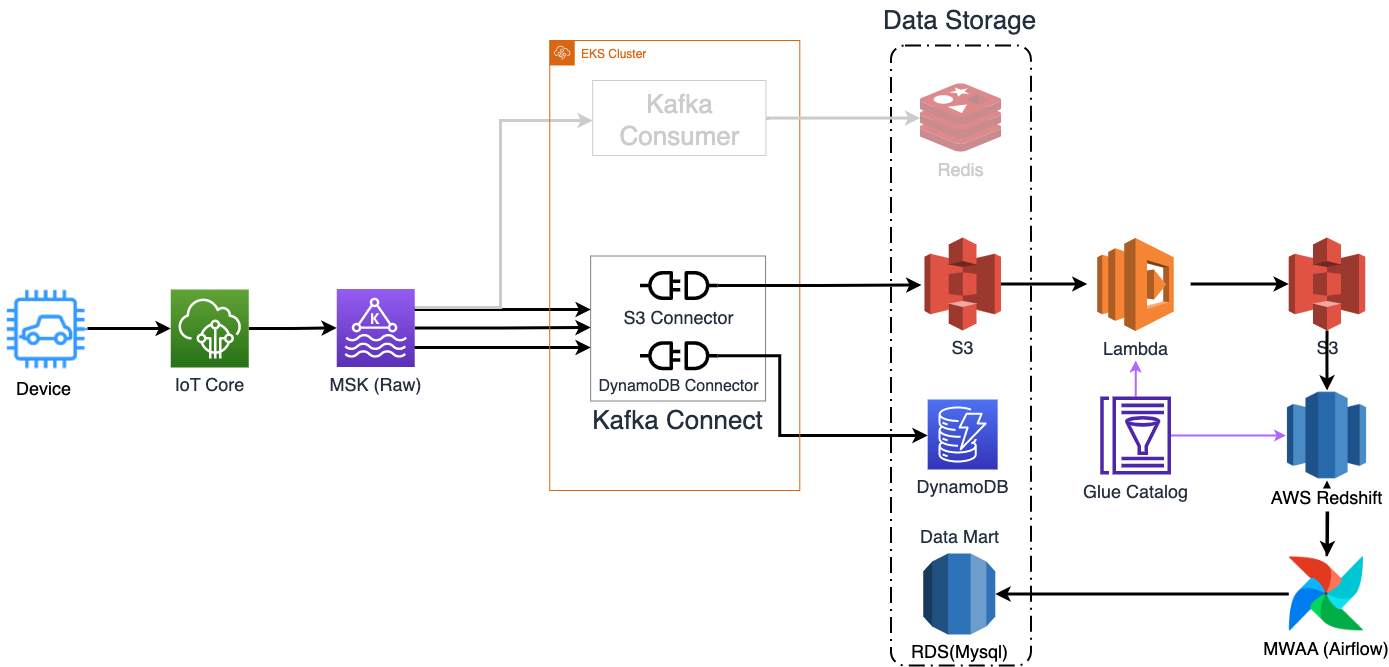 FMS 데이터 파이프라인 아키텍처
FMS 데이터 파이프라인 아키텍처
차량에서 최초로 수집되는 여러 상태 데이터들은 최종적으로 데이터베이스/스토리지에 적재됩니다. 결과적으로는 데이터가 아래와 같은 흐름을 거쳐 FMS 서비스에 필요한 형태로 저장됩니다.
- 차량에서 다양한 상태의 데이터를 수집합니다.
- 수집되는 데이터는 발송 주기에 맞춰 IoT Core로 전송합니다.
- IoT Core 메시지 브로커에 저장된 메시지는 라우팅 규칙에 따라 상위 주제별로 Kafka Topic으로 라우팅 됩니다.
- Kafka Topic의 각 파티션에 저장된 메시지는 Kafka Connect를 통해 데이터 싱크(DynamoDB, S3)로 적재됩니다. (Redis는 필터링을 하는 Kafka Consumer를 통해 적재됩니다)
- S3에 적재된 Json 포맷의 객체는 Lambda를 통해 분류/변형 후 S3에 적재됩니다 (Redshift, Athena 쿼리에 적합한 형태로 적재됩니다)
- Airflow로 스케줄링된 Redshift 쿼리를 통해 데이터를 집계하여 RDS(데이터 마트)에 저장됩니다.
2. 스트리밍 파이프라인 : IoT Core에서 Kafka로
2.1. 차량 IoT 데이터의 특징
FMS 서비스로 관리하는 차량들은 IoT 단말기 내에서 차량의 상태 정보를 수집한 뒤 서버(AWS IoT Core)로 전송합니다. 해당 메시지는 가공/적재 과정을 거쳐 서비스에서 활용됩니다.
쏘카의 차량에서 수집되는 상태 메시지는 다음과 같은 특징들이 있습니다.
보고하는 유형의 메세지와 제어 응답 유형의 메시지가 있습니다.
일반적으로 차량을 관제하기 위해선 차량 단말기에서 차량의 상태를 주기적으로 수집해서 보고하는 것이 필요합니다. 실제로 특정 프로토콜은 차량의 위치(위도, 경도)와 속도 같은 이동 정보를 주기적으로 보고하는 역할을 합니다. 이와는 다른 유형으로 제어 응답 메시지의 경우는, 서버에서 차량 단말기를 제어하기 위해 전송한 명령에 대해 단말기가 해당 명령을 수행하고 결과를 응답하는 용도로 사용합니다. 예를 들어 블랙박스에 녹화되고 있는 영상을 업로드하라는 명령이 있으면 단말기는 이를 수행한 후 결과를 메시지로 수집 서버에 전송합니다.
차량의 상태를 표현하기 위한 다양한 프로토콜이 존재해 스키마 설계에 신경을 써야 합니다.
FMS 서비스에서 차량 관제, 운전 효율화 등의 기능을 제공하기 위해선 다양한 수집 데이터를 필요로 합니다. 차량 운행 상태, 화물 차량의 온도 상태, 블랙박스 상태 등 각 역할 별로 프로토콜을 나눠서 수집해야 합니다. 실제로 현재 수집되는 수십여 개의 메시지 프로토콜은 특성과 목적에 맞게 분류되어 있습니다.
위처럼 메시지 프로토콜이 다양하다 보니 쏘카에서는 프로토콜별로 스키마를 설계할 때 프로젝트에 참여하는 주요 팀들과 함께 논의를 진행했습니다. 덕분에 스키마 간의 통일성과 규칙이 생겼으며 데이터를 처리하는 쪽에서는 예측 가능하게 소프트웨어 개발이 가능했습니다. 개인적으로 스키마 설계를 할 때 이해관계자들이 함께 참여하는 것이 정말 중요하다고 느껴졌습니다.
주기적으로 보고하는 유형은 보통 배치로 묶어서 전송하기에 적재할 때 다시 풀어줘야 합니다
단말기에서 수집하는 상태 정보들은 프로토콜 별로 설정된 Hz 수집 주기에 따라 수집됩니다. 이때 메시지를 수집 서버로 전송한다면 통신비나 클라우드 리소스(IoT Core, Kafka 등)의 비용이 더 비싸집니다. 따라서 비용 효율화를 위해 상태 정보를 배치 형태로 묶어서 전송 주기에 따라 전송됩니다. 그래서 주기 보고의 메시지는 아래와 같은 형태로 구성됩니다. 최종적으로 데이터베이스에서 레코드 별로 조회하기 위해선 배치 형태를 풀어줘야 합니다.
주기 보고 메시지 형태
{
"object": "vehicle",
"type": "kinematic",
"messaged_at": "2023-01-01T12:00:00+09:00",
"measurements": [
{
"timestamp_iso": "2023-01-01T11:59:00+09:00",
"speed": 30,
...
},
{
"timestamp_iso": "2022-01-01T11:59:01+09:00",
"speed": 30,
...
},
...
],
...
}
2.2. IoT Core에서 Kafka로
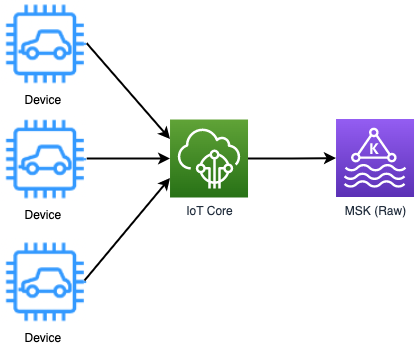
차량에서 수집된 데이터는 IoT Core의 메시지 라우팅 규칙에 따라 Kafka로 전송됩니다. 위 메시지에서 분류 목적으로 사용하고 있는 object 필드에 대응되는 각 Kafka topic으로 라우팅 됩니다.
여기서 한 가지 중요한 점은 하나의 topic에 여러 프로토콜의 메시지가 들어올 수 있다는 점입니다. 메시지 프로토콜에 1:1 대응되도록 topic을 만든다면 수많은 토픽을 관리해야 하며 관리에 대한 부담이 늘어나게 됩니다.
보통 Kafka를 운영하면 메시지 스키마에 대한 검증을 하기 위해 사용하는 Schema Registry를 사용하는 경우가 많습니다. 쏘카의 유즈케이스에서는 하나의 토픽에 여러 메시지가 들어오다 보니 Schema Registry를 도입하기가 쉽지 않았기에 우선 장애 없이 메시지를 적재하고 이후에 스키마를 검증하는 fail safe 방식으로 아키텍처를 설계하였습니다.
2.3. Kafka 관리
FMS 파이프라인에서는 MSK를 통해 Kafka를 운영하고 있습니다. 모니터링은 MSK의 향상된 파티션 수준 모니터링 설정으로 Kafka 운영에 필요한 주요 메트릭을 cloudwatch에서 확인하고 있습니다. 이를 통해 기본 메트릭뿐만 아니라 Consumer Group 별로 Lag 확인이 가능해서 모니터링하는데 큰 도움이 되고 있습니다.
토픽의 경우 메시지의 분류 필드인 object 별로 생성하여 관리하고 있으며, 실패한 메시지들을 저장하는 deadletter 전용 토픽이나 일부 유즈케이스에 사용되는 토픽 등이 있습니다. 주요 topic들은 partition과 replication factor를 설정해서 처리 성능과 가용성을 높게 유지하고 있습니다.
 UI For Apache Kafka
저장되는 메시지는 실시간으로 UI for Apache Kafka를 통해 확인하고 있습니다. UI for Apache Kafka는 직관적인 UI로 kafka 관리를 위한 많은 기능들을 제공해 줍니다. 특히 토픽에 쌓이는 메시지를 실시간으로 조회가 가능하며 여러 검색 방식을 지원해 줘서 초기에 Kafka 관리 툴로 사용하기에 적합합니다.
UI For Apache Kafka
저장되는 메시지는 실시간으로 UI for Apache Kafka를 통해 확인하고 있습니다. UI for Apache Kafka는 직관적인 UI로 kafka 관리를 위한 많은 기능들을 제공해 줍니다. 특히 토픽에 쌓이는 메시지를 실시간으로 조회가 가능하며 여러 검색 방식을 지원해 줘서 초기에 Kafka 관리 툴로 사용하기에 적합합니다.
3. 스트리밍 파이프라인 : Kafka Sink Connector로 변형/적재하기
Kafka 토픽에 저장된 메시지를 외부 데이터 싱크(DynamoDB, S3)로 적재하는 Kafka Sink Connector를 개발하게 된 배경과 구현 사항, 장단점 등에 대해 알아보도록 하겠습니다.
3.1. Kafka Connect란?
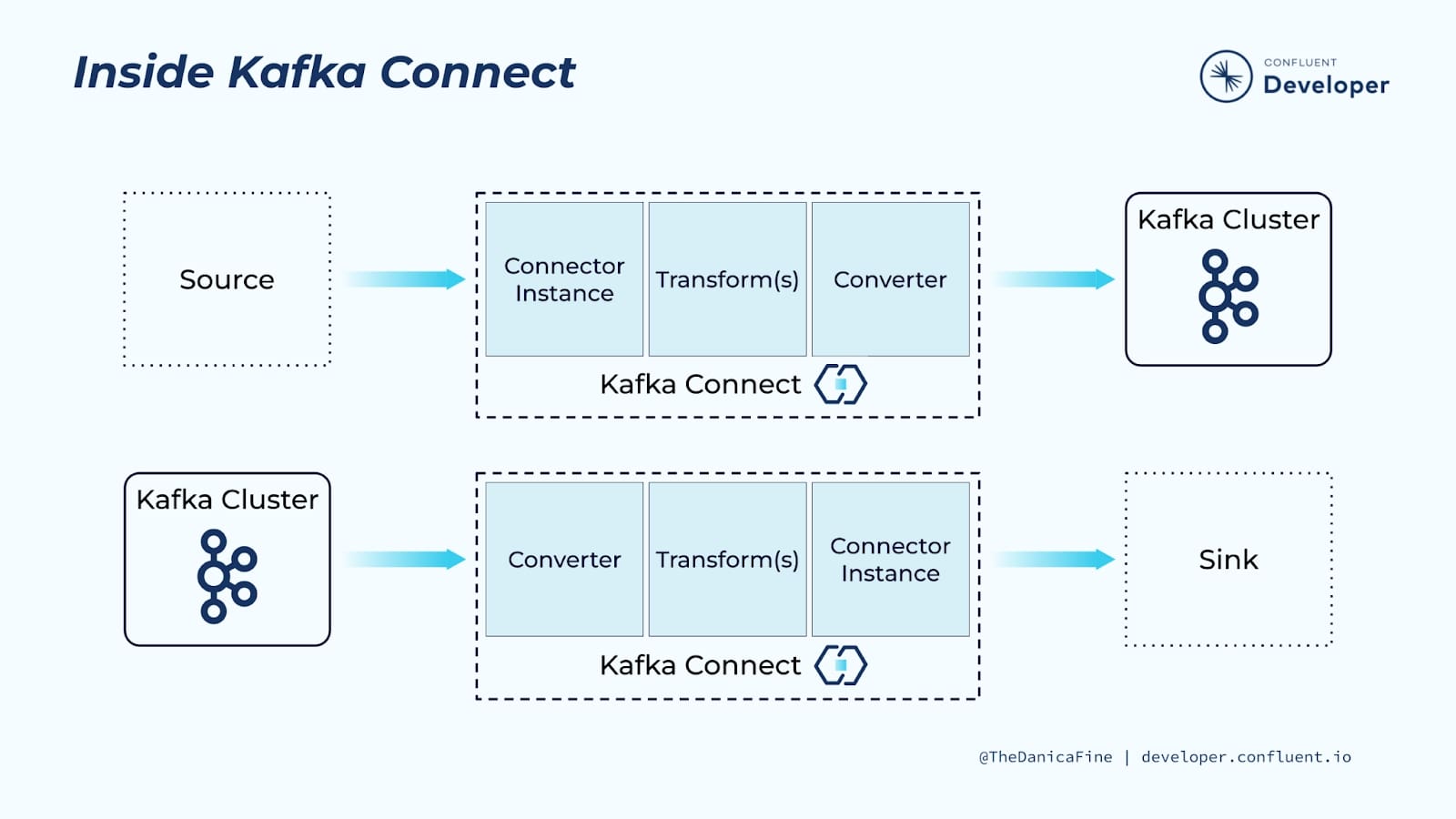
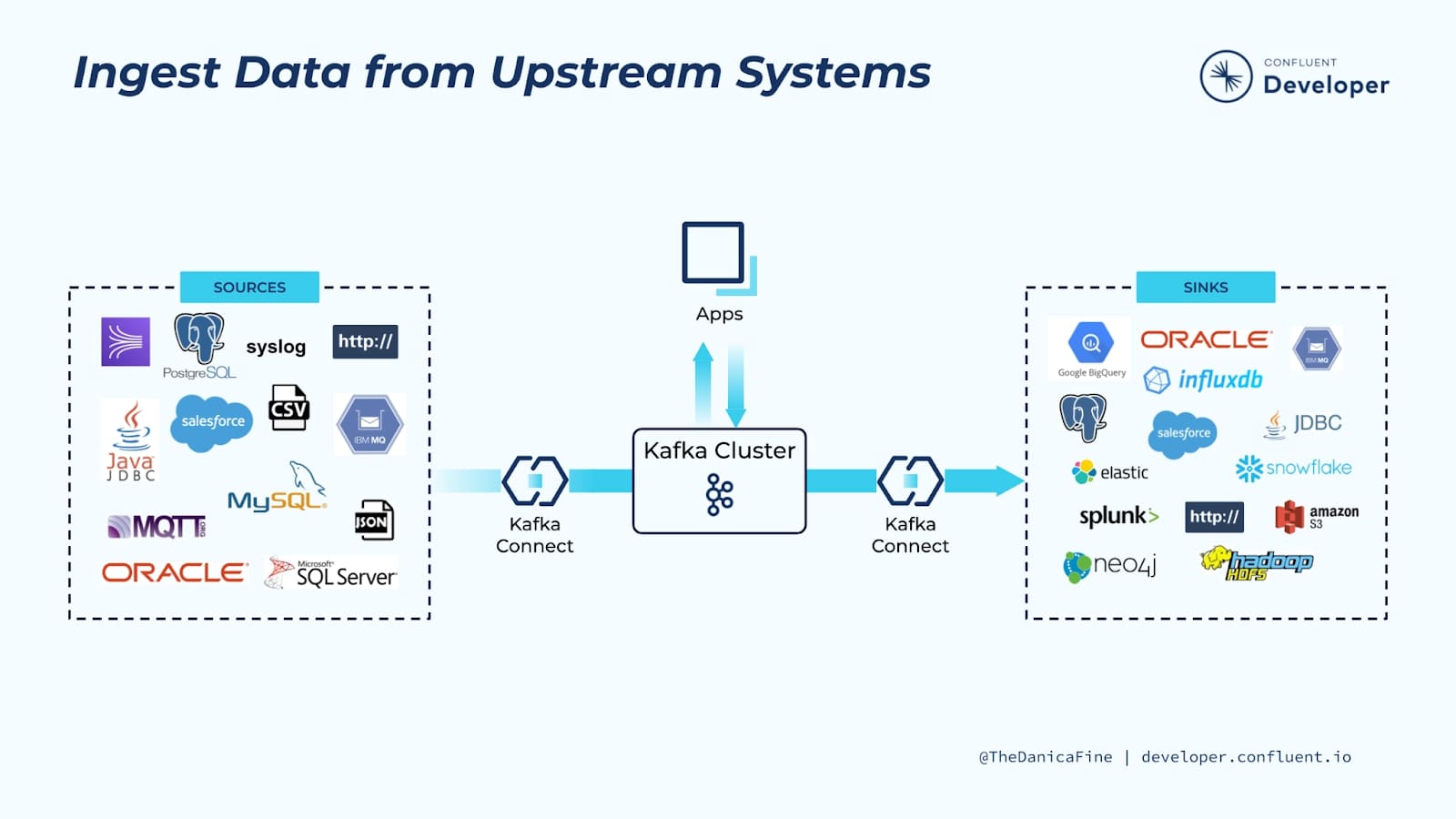 Kafka Connect의 역할 (출처: https://developer.confluent.io/learn-kafka/kafka-connect/intro)
Kafka Connect의 역할 (출처: https://developer.confluent.io/learn-kafka/kafka-connect/intro)
보통 Kafka 토픽의 메시지를 적재하기 위해선 크게 아래 2가지 방식을 활용합니다.
- 프로그래밍 언어 별 존재하는 Kafka SDK를 사용해서 Kafka Consumer를 구현하는 방법
- Kafka Connect를 활용하여 적재하는 방법
Kafka Consumer는 높은 자유도로 개발이 가능하며, 다양한 프로그래밍 언어(JVM 계열 언어, Python, Javascript 등)로 개발할 수 있도록 SDK를 지원합니다. 일반적으로 Kafka 토픽의 메시지를 처리할 때 광범위하게 사용됩니다.
Kafka Connect는 Consumer를 한 단계 추상화하여 제공하는 Confluent에서 개발한 프레임워크입니다. 데이터 소스에서 Kafka로 데이터를 옮기거나 Kafka에서 데이터 싱크로 적재하는 목적으로 주로 사용됩니다. 대중적인 데이터 소스/싱크에 대한 Connector(Mysql, MongoDB, S3, ElasticSearch 등)는 이미 오픈소스로 나와있어 손쉽게 사용이 가능합니다 (Confluent Hub에서 확인이 가능합니다) Kafka Connect에 대한 자세한 내용은 아래 토글을 눌러서 확인 부탁드립니다.
Kafka Connect의 장단점
- 다양한 데이터 소스, 싱크에 대한 오픈소스를 활용하면 손쉽게 데이터 이동이 가능합니다.
- 프레임워크의 가이드를 따라 Connector를 손쉽게 개발하여 사용할 수 있습니다.
- REST API를 통해 Kafka Connect의 운영이 가능합니다.
- Worker와 Task 개수 조정을 통해 손쉽게 스케일 아웃이 가능합니다.
-
Property 기반으로 Kafka Connector 설정을 할 수 있어 선언적인(declarative) 소프트웨어 운영이 가능해집니다. 아래는 S3 Sink Connector를 배포할 때 API에 요청하는 스크립트 예시입니다.
echo ' { "connector.class": "kr.socar.fms.connector.s3.S3SinkConnector", "topics": "OOO", "tasks.max": "1", "key.converter.schemas.enable": "false", "value.converter.schemas.enable": "false", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "key.converter": "org.apache.kafka.connect.json.JsonConverter", "flush.size": "60000", "rotate.interval.ms": "300000", "s3.part.size": "60000000", "partition.duration.ms": "3600000", "s3.region": "ap-northeast-2", ... } ' | curl -X PUT -d @- -s localhost:8083/connectors/vehicle-to-s3/config --header "content-Type:application/json"하지만 꼭 장점만 있는 것은 아닙니다.
- Kafka Connect 프레임워크의 동작 방식을 기본적으로 이해하고 있어야 합니다.
- Kafka Consumer에 비해 상대적으로 테스트하기나 디버깅하기가 불편합니다.
- Java로 개발되어 있어 JVM 계열 언어로만 개발이 가능합니다.
- 간단한 변형 후 적재가 아닌 비즈니스 요구사항이나 복잡한 처리가 포함된 작업을 구현할 경우 Kafka Consumer로 구현하는 것이 수월합니다.
Kafka Connect에 대한 더 자세한 설명은 공식 문서를 참고해 주세요.
Kafka Connect의 동작 방식
Kafka Connect는 Kafka와 외부 데이터 소스/싱크를 연결해 주는 프레임워크입니다. Kafka Connector는 Kafka Connect에서 실제로 동작하는 구현체이며 Kafka Connect에 의해 관리됩니다. Kafka Connect를 사용하기 위해선 Kafka Connector를 jar 형태로 Kafka Connect 내부(보통 Docker Image)에 포함시킨 후, Kafka Conenct를 실행한 후 제공되는 API로 Kafka Connector를 등록하는 과정을 거치게 됩니다.
Kafka Connector는 Source와 Sink 2가지 방식을 제공합니다. Source Connector는 데이터 소스에서 Kafka 토픽으로 메시지를 전달하고 Sink Connector는 Kafka 토픽에서 데이터 싱크로 메시지를 전달합니다. 실제로 Kafka Connector를 구현하기 위해서 Source, Sink에 따라 나누어진 인터페이스를 따르게 됩니다.
Kafka Connect를 관리하기 위해선 Worker와 Task의 개념을 알고 있어야 합니다. Task는 Kafka Connector의 논리적인 실행 단위이며 JVM으로 실행되는 Process라고 보시면 됩니다. 보통 하나의 Task는 Kafka 토픽의 한 개 이상의 파티션을 담당합니다 (보통 1개의 Task가 1개의 파티션을 맡도록 운영합니다).
Worker는 Task를 운영하는 물리적인 프로세스로 Task의 라이프 사이클을 담당합니다. 즉 하나의 Worker에는 여러 개의 Task를 실행하고 있으며, Worker끼리 서로 통신하면서 Task를 재할당해 주기도 합니다. FMS 프로젝트에서는 Kubernetes 환경에서 Kafka Connect를 운영하며 이때 Worker는 Pod이 됩니다.
Kafka Connect는 Standalone Mode와 Distributed Mode가 있는데, Standalone은 Worker를 1개, Distributed Mode는 Worker를 여러 개 사용할 수 있습니다. 주로 운영 환경에서 Kafka Connect는 Distributed Mode로 사용하며 여러 개의 Worker와 Task를 상황에 맞게 조정하며 변화되는 트래픽에 유연하게 대응합니다.
Kafka Connect의 동작 방식에 대한 더 자세한 내용은 공식 문서의 Kafka Connect Concepts 부분을 참고해 주세요.
3.2. 요구 사항 및 결정 이유
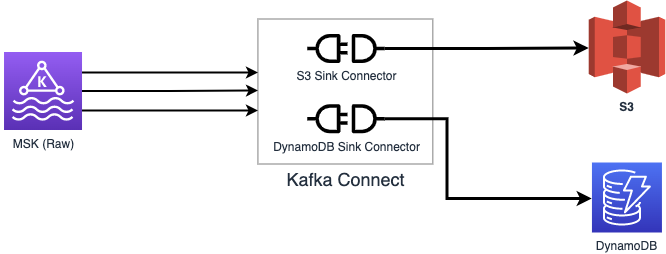
Kakfa 메시지 처리 방법을 선택할 때는 비즈니스 요구 사항을 고려하는 것이 중요합니다. Kafka 토픽의 메시지를 단순하게 적재하는 경우라면 오픈소스 Kafka Connector를 사용하는 게 낫습니다. 하지만 FMS 프로젝트에는 아래와 같은 요구사항들이 있어서 Kafka Connector를 직접 개발하여 하나의 Kafka Connect로 메시지 적재를 관리하자는 결정을 내렸습니다.
-
Kafka 토픽 별 메시지들이 S3와 DynamoDB에 적재되어야 합니다.
Kafka에서 S3로 데이터를 적재하는 S3 Sink Connector는 오픈소스로 존재하여 많은 곳에서 사용하고 있습니다. 하지만 DynamoDB의 경우 Sink Connector가 오픈소스로 존재하지 않아 직접 구현이 필요한 상황이었습니다 (Confluenent에서 제공하는 Sink Connector가 있지만 유료 라이선스입니다) 이미 제공되는 S3 Sink Connector를 사용하면서 DynamoDB도 Connector 형태로 개발한다면 하나의 플랫폼으로 빌드, 운영할 수 있게 되어 이점이 있을 것이라고 판단하였습니다. -
일부 요구사항에 맞게 가벼운 변형 작업이 필요합니다.
DynamoDB는 레코드를 추가할 때 Partition Key를 필수적으로 입력해야 합니다. FMS 프로젝트에서 DynamoDB 테이블은 비용/성능 효율화를 위해 Single Table Design 기법으로 디자인했고 이에 맞는 Partition Key가 적재되기 전에 메시지에 추가되어야 합니다. 이외에도 비용 절감을 위해 불필요한 칼럼을 삭제하는 것도 고려가 필요합니다.여기서 Kafka Connect에는 SMT(Single Message Transformation) 가 있어 Property 기반으로 손쉽게 메시지의 변형이 가능합니다. 물론 SMT 특성상 제약 사항이 존재하지만 필요하면 직접 Transfrom 을 구현하여 사용이 가능합니다.
-
스트리밍 환경에서 신뢰성과 확장성이 보장되어야 합니다.
스트리밍 환경에서는 메시지를 빠르게 처리 후 적재하는 것이 중요합니다. 따라서 Kafka의 메시지가 빠르게 쌓여도 Transformation & Load 레이어에서는 일관성 있게 처리할 수 있어야 합니다.
Kafka Connect는Distributed Mode를 통해 Worker 개수를 조정하여 Scale Out/In을 쉽게 할 수 있으며, Worker가 만약 실패하더라도 기존 Worker 들에 Task들을 리밸런싱 해줘서 안전하게 운영이 가능합니다.
결과적으로 DynamoDB Sink Connector를 직접 개발하였으며, S3 Sink Connector도 추가 요구사항을 위해 Class를 Override 하여 커스터마이징 하였습니다.
3.4. Kafka Connector 레포 구성 및 구현
Kafka Connector의 레포 구성 및 구현에 대해 알아보도록 하겠습니다.
...
.
├── ...
├── build.gradle.kts
├── Dockerfile
├── e2e
│ ├── Makefile
│ ├── docker-compose.e2e.yaml
│ ├── socar-fms-pipeline-docker
│ └── tests
└── subprojects
├── core
│ ├── main/...
│ | ├── converters
│ │ │ ├── SplitListConverter.kt
│ │ │ └── UpdateFieldsConverter.kt
│ │ └── transforms
│ │ ├── InsertFieldInStringTemplate.kt
│ │ └── SplitArrayField.kt
│ └── test/...
├── dynamodb
│ ├── main/...
│ │ ├── DynamoDbDao.kt
│ │ ├── DynamoDbSinkConnector.kt
│ │ ├── DynamoDbSinkConnectorConfig.kt
│ │ └── DynamoDbSinkTask.kt
│ └── test/...
└── s3
├── main/...
│ ├── S3SinkConnector.kt
│ ├── S3SinkConnectorConfig.kt
│ └── S3SinkTask.kt
└── test/...
Kafka Connector를 구현하는 레포지토리는 Kotlin으로 작성되었으며 위와 같이 구성되어 있습니다. S3, DyanmoDB Sink Connector가 멀티 모듈 형태로 구성되어 있으며 공통 기능(변형)을 하는 모듈을 별도로 의존하고 있습니다.
DynamoDB의 경우 유일하게 Confluent에서 제공하는 Connector가 존재했지만 유료 라이선스이기에 직접 구현하는 것을 선택했습니다. 직접 구현하기 위해선 connect-api 의존성을 추가해 줬습니다.
S3의 경우 Maven Repo에 올라와 있는 kafka-connect-s3를 상속받아 구현하였습니다.
implementation("io.confluent:kafka-connect-s3:10.0.11")
implementation("org.apache.kafka:connect-api:$kafkaVersion")
implementation("org.apache.kafka:connect-transforms:$kafkaConnectTransformVersion")
기본적으로 Sink Connector를 구현하기 위해선 SinkConnector, SinkTask, AbstractConfig 3가지 추상 클래스를 구현해야 합니다.
AbstractConfig는 Kafka Connector에 대한 설정 Config들을 작성합니다. 위에서 언급했듯이 Kafka Connector를 실행할 때 Property 기반으로 설정값을 입력하게 됩니다. 아래는 DynamoDB Sink Connector 설정값을 정의한 것으로 Table, Partition Key, Sort Key 등에 대한 입력이 있음을 확인할 수 있습니다.
class DynamoDbSinkConnectorConfig(config: Map<String, String>) : AbstractConfig(CONFIG, config) {
internal companion object {
const val DYNAMODB_TABLE = "dynamodb.table"
private const val DYNAMODB_TABLE_NAME_DOC = "DynamoDB Target Table"
const val DYNAMODB_TABLE_PARTITION_KEY = "dynamodb.partition.key"
private const val DYNAMODB_TABLE_PARTITION_KEY_DOC = "DynamoDB Partition Key"
const val DYNAMODB_TABLE_SORT_KEY = "dynamodb.sort.key"
private const val DYNAMODB_TABLE_SORT_KEY_DOC = "DynamoDB Sort Key"
const val CONVERTER_SPLIT_LIST_KEY = "converter.split.list.key"
private const val CONVERTER_SPLIT_LIST_KEY_DOC = "Key for splitting record to array of record"
const val CONVERTER_UPDATE_FIELDS_TEMPLATE = "converter.update.fields.template"
private const val CONVERTER_UPDATE_FIELDS_TEMPLATE_DOC = "fields template for update"
...
}
SinkConnector는 Task가 실행될 때 필요한 기능들을 작성합니다. Task가 실행, 중단될 때 동작이나 SinkTask, Config에 대한 정의를 합니다.
class DynamoDbSinkConnector : SinkConnector() {
private val logger = LoggerFactory.getLogger(DynamoDbSinkConnector::class.java)
private lateinit var sinkConfig: DynamoDbSinkConnectorConfig
...
override fun version(): String = ...
override fun start(props: MutableMap<String, String>) {...}
override fun stop() {...}
override fun taskClass(): Class<out Task> = DynamoDbSinkTask::class.java
override fun taskConfigs(maxTasks: Int): MutableList<MutableMap<String, String>> {...}
override fun config() = DynamoDbSinkConnectorConfig.CONFIG
}
SinkTask는 실제로 메시지를 처리하는 Task의 구현합니다. 메시지를 DynamoDB 적재하기 위해 필요한 의존성들을 초기화하여 사용하게 됩니다. 대표적으로 DynamoDB와 통신하는 역할을 하는 DynamoDBDao이나 변형을 담당하는 Converter 등이 있습니다(Converter의 역할은 아래에서 다룹니다). 그리고 실제 메시지를 처리하는 부분은 put 메서드에서 작성하게 됩니다.
open class DynamoDbSinkTask : SinkTask() {
private val logger = LoggerFactory.getLogger(DynamoDbSinkTask::class.java)
private var reporter: ErrantRecordReporter? = null
lateinit var config: DynamoDbSinkConnectorConfig
lateinit var dao: DynamoDbDao
lateinit var splitArrayConverter: SplitListConverter
lateinit var updateFieldsConverter: UpdateFieldsConverter
override fun version() = ...
override fun start(props: MutableMap<String, String>?) {...}
override fun stop(){...}
override fun put(records: MutableCollection<SinkRecord>?) {
// 메시지 변형
// 예외 메시지 방어 처리 및 DeadletterQueue 전송
...
// DynamoDb 적재
logger.info("dynamodb request item size : ${passed.size}")
val response = dao.batchWrite(passed).partition {
it.unprocessedItems.isEmpty()
}
...
}
}
위에서 Sink Connector를 직접 구현한 DynamoDB Connector의 구현부에 대해 알아보았습니다. S3 Sink Connector 같은 경우 기존 구현체(kafka-connect-s3)를 상속받아서 변형 작업만 일부 추가하였습니다.
open class S3SinkTask : ConfluentS3SinkTask() {
private val logger = LoggerFactory.getLogger(S3SinkTask::class.java)
private var reporter: ErrantRecordReporter? = null
lateinit var config: S3SinkConnectorConfig
lateinit var splitArrayConverter: SplitListConverter
lateinit var updateFieldsConverter: UpdateFieldsConverter
override fun version() = ...
override fun start(props: MutableMap<String, String>?) {...}
override fun stop(){...}
override fun put(records: MutableCollection<SinkRecord>?) {
// 변형 및 예외 방어 로직
...
super.put(newRecords)
}
}
직접 Kafka Connector를 개발하면서 공식 가이드를 참고하였고 구현 코드는 S3 Sink Connector의 구현체인 kafka-connect-storage-cloud 소스코드를 보면서 빠르게 코드 작성을 할 수 있었습니다. 직접 Kafka Connector를 구현하시는 분들께 도움이 되었으면 합니다.
3.5. Kafka Connector 변형(Transformation)
이번에는 Kafka Connector에서 구현한 변형 기능에 대해 알아보도록 하겠습니다. 위에서 언급한 것처럼 Kafka Connector는 Propery 기반으로 Configuration 설정을 할 수 있어 Connector Task를 선언적으로 관리할 수 있는 장점이 있습니다.
따라서 메시지 변형 관련 설정도 최대한 Property 기반으로 관리할 수 있도록 하였으며, 이를 위해서 비즈니스 로직은 최대한 제외하고 Property로 설정할 수 있도록 추상화하였습니다. 이를 통해 Kafka Connector가 새로 추가되는 토픽이나 다른 프로젝트에서 사용돼도 문제가 없도록 하였습니다.
DynamoDB는 레코드를 추가할 때 Partition Key를 필수적으로 입력해야 합니다. FMS 프로젝트에서 DynamoDB 테이블은 비용/성능 효율화를 위해 Single Table Design 기법으로 디자인했고 이에 맞는 Partition Key를 추가해 줘야 했습니다. Kafka Connect에는 SMT(Single Message Transformation) 가 있어 Property 기반으로 손쉽게 메시지의 변형이 가능합니다. 물론 SMT 특성상 제약 사항이 존재하지만 필요하면 직접 Transfrom 을 구현하여 사용이 가능합니다.
아래는 메시지를 템플릿 언어 기반으로 변경할 수 있도록 구현한 Transform입니다.
{
"transforms": "InsertFieldInStringTemplate",
"transforms.InsertFieldInStringTemplate.field": "pk",
"transforms.InsertFieldInStringTemplate.value": "${id}#${object}#${type}"
}
- as-is
{
"object": "vehicle",
"type": "kinematic",
"id": 350
}
- to-be
{
"object": "vehicle",
"type": "kinematic",
"id": 350,
"pk": "350#vehicle#kinematic"
}
또한 위에서 언급했듯이 FMS 프로젝트의 차량 IoT 데이터는 보통 배치로 묶여서 메시지들이 들어옵니다. 만약 클라이언트가 nested된 형태의 데이터를 쿼리 하는 경우 전처리를 진행해야 하는 불편함이 생기기에 적재하기 전에 데이터를 풀어서 적재해 주는 것이 좋습니다.
보통 메시지를 전처리하기 위해서 적재 전에 별도의 Consumer를 두곤 하지만, PoC 단계에서 관리 포인트를 높이고 싶지 않았습니다. 그래서 Kafka Connector에서 Property 기반으로 배치 메시지를 풀어줄 수 있도록 Converter를 구현하고 Property를 통해 조작이 가능하도록 했습니다(Kafka Connector의 Converter API와는 다릅니다).
{
"converter.split.list.key": "measurements"
}
배치 메시지를 풀어낼 필드를 입력하면 아래와 같이 해당 필드의 배열을 메시지를 쪼갭니다.
- as-is
{
"object": "vehicle",
"type": "kinematic",
"messaged_at": "2023-01-01T12:00:00+09:00",
"measurements": [
{
"timestamp_iso": "2023-01-01T11:59:00+09:00",
"speed": 30
},
{
"timestamp_iso": "2022-01-01T11:59:01+09:00",
"speed": 40
}
]
}
- to-be
[
{
"object": "vehicle",
"type": "kinematic",
"messaged_at": "2023-01-01T12:00:00+09:00",
"timestamp_iso": "2023-01-01T11:59:00+09:00",
"speed": 30
},
{
"object": "vehicle",
"type": "kinematic",
"messaged_at": "2023-01-01T12:00:00+09:00",
"timestamp_iso": "2023-01-01T11:59:01+09:00",
"speed": 45
}
]
3.6. Kafka Connect 배포 및 운영
이제 Kafka Connect 배포 및 운영에 대해 알아보도록 하겠습니다. FMS 프로젝트에서 Kafka Connect는 Kubernetes(AWS EKS)에서 프로비저닝하고 있습니다. 아래 Dockerfile에서 보시는 것처럼 Kubernetes에서 배포하기 위해 Kafka Connect 이미지가 필요합니다. 이에 DynamoDB, S3 Sink Connector를 jar로 빌드 한 후 Kafka Connect 이미지에 파일을 마운트 합니다. 만약 Connector가 추가되면 여기서 마운트를 시켜줍니다.
FROM openjdk:17-jdk-slim-buster AS builder
WORKDIR /usr/src/app
...
COPY subprojects subprojects
RUN ./gradlew :s3:uberjar && ./gradlew :dynamodb:uberjar
FROM confluentinc/cp-kafka-connect:$KAKFA_CONNECT_VERSION
ARG FMS_CONNECTOR_PATH="/usr/share/fms-connectors"
ENV CONNECT_PLUGIN_PATH $CONNECT_PLUGIN_PATH,$FMS_CONNECTOR_PATH
ENV JAVA_OPTS="-XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+ExitOnOutOfMemoryError -Xmx1024m -Xms1024m"
COPY --from=builder /usr/src/app/subprojects/dynamodb/build/libs $FMS_CONNECTOR_PATH
COPY --from=builder /usr/src/app/subprojects/s3/build/libs $FMS_CONNECTOR_PATH
CI 파이프라인에서는 Github Action을 사용합니다. Github Action에서는 main 브랜치의 Tag Push가 발생했을 때 각 Connector 별 유닛 테스트와 Kafka Connect의 E2E 테스트 (Docker Compose 기반)을 수행합니다. 만약 통과했을 시 AWS ECR로 이미지를 빌드 후 배포합니다.
Kubernetes 프로비저닝을 위해서는 Helm chart을 사용합니다. cp-kafka-connect 차트를 Clone 해서 사용하고 있으며 추후 strimizi로 환경을 옮길 계획입니다. Helm Chart의 배포는 ArgoCD를 사용하고 있습니다.
replicaCount: 3 # Worker 개수를 설정합니다 (k8s Deployment로 관리됩니다)
image: ...
imageTag: ...
imagePullPolicy: ...
heapOptions: "-Xms512M -Xmx1024M"
kafka:
bootstrapServers: ...
configurationOverrides: # Worker Configuration를 입력합니다.
plugin.path: "/usr/share/java,/usr/share/confluent-hub-components,/usr/share/fms-connectors"
key.converter: "org.apache.kafka.connect.storage.StringConverter"
value.converter: "org.apache.kafka.connect.storage.StringConverter"
key.converter.schemas.enable: "false"
value.converter.schemas.enable: "false"
...
...
Kafka Connect는 REST API를 통해 Kafka Connector 운영이 가능합니다. 따라서 Shell Script 파일을 실행해 API를 호출하게 되며 Kafka Connector는 여기서 Task 단위로 실행됩니다.
for obj in "vehicle" ... ; do # topic 별로 Kafka Connector를 배포합니다
echo '
{
"connector.class": "kr.socar.fms.connector.s3.S3SinkConnector",
"topics": "fms.'${obj}'.real.msk",
"tasks.max" : "1",
"converter.split.list.key": "measurements",
...
}
' | curl -X PUT -d @- -s localhost:8083/connectors/${obj}-to-s3/config --header "content-Type:application/json"
echo '
{
"connector.class" : "kr.socar.fms.connector.dynamodb.DynamoDbSinkConnector",
"topics": "fms.'${obj}'.real.msk",
"tasks.max" : "1",
"converter.split.list.key": "measurements",
...
...
}
' | curl -X PUT -d @- -s localhost:8083/connectors/${obj}-to-dynamodb/config --header "content-Type:application/json"
done
3.7. Kafka Connect 운영 시 고려할 점
Kafka Connector를 운영하면서 신경 썼던 지점들도 말씀드리겠습니다.
3.7.1. 메시지 중복 처리
실시간 데이터가 저장소에 저장될 때 데이터가 중복되거나 손실되지 않아야 합니다. 만약 특정 Offset의 메시지를 적재하는 과정에서 Kafka Connector가 문제가 생겨 리밸런싱이 발생한다면 메시지의 누락이나 중복이 발생할 수도 있습니다. 중복은 저장소에서 후처리를 할 수 있지만, 누락은 복구하기가 힘들어 더 조심해야 합니다.
이때 메시지를 처리하는 영역(Producer, Consumer)에서는 Message Delivery Semantics라고 해서 메시지를 전송하는 전략을 결정합니다. 대표적으로 At Least Once는 적어도 한 번 이상의 메시지를 다시 보내겠다는 의미로 메시지의 누락은 발생하지 않지만 중복이 발생할 수 있습니다. 반면 Exactly Once는 메시지를 정확히 한 번씩만 보내겠다는 의미로 누락과 중복이 발생하지 않습니다. 이는 다운타임이 있더라도 정확하게 처리했던 메시지의 Offset을 기억해서 동작함을 의미합니다.
S3 Sink Connector는 특정 조건에서 Exactly Once를 지원합니다(공식 문서의 S3 Object Uploads 부분 참고). DynamoDB Sink Connector의 경우 At Least Once 방식으로 구현을 했습니다. 이유는 DynamoDB의 경우 같은 메시지(Primiary Key가 같은 경우)는 Upsert 하기 때문에 중복 이슈는 발생하지 않을 것이라 판단하였습니다.
3.7.2. 에러 핸들링
Kafka Sink Connector는 실행될 때 앞단에서 메시지를 검증/전처리하는 Converter와 Transform이 위치합니다. 만약 메시지가 해당 Converter나 Transform 조건에 맞지 않는 경우 Error Message로 간주하게 됩니다. 이때 errors.tolerance를 적용해서 None(기본값)일 경우 Task를 실패시키고, all일 경우 메시지를 생략하고 다음 메시지를 처리하게 됩니다.
FMS 프로젝트에서는 all을 설정해 생략되는 메시지는 Deadletter Queue로 보내도록 해 모니터링 및 재처리가 가능하도록 하였습니다. Deadletter Queue로 사용될 Topic을 생성하고 운영하는 Task 들에서 문제가 발생한 메시지는 해당 Topic으로 보내도록 설정하였습니다.
{
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "fms.all.deadletter.msk",
"errors.deadletterqueue.topic.replication.factor": 1,
"errors.deadletterqueue.context.headers.enable": "true",
"errors.log.include.messages": "true"
}
만약 Connector Instance에서 메시지 처리에 실패하는 경우 에러로 인해 Task가 실패할 수 있습니다. 이 경우 모니터링한 후 다시 Task를 실행해 줘야 합니다.
만약 Kafka Connector를 직접 개발하시는 경우 Connector Instance에서 발생한 에러 메시지를 Deadletter Queue로 보내도록 돕는ErrantRecordReporter를 사용해 보시는 걸 추천드립니다.
Kafka Connector의 에러 핸들링에 대해 더 자세하게 알고 싶다면 여기를 확인해 보세요.
3.8. Kafka Connect 모니터링하기
Kafka Connect는 기본적으로 jmx를 통해 운영에 필요한 메트릭들을 제공합니다. FMS 프로젝트에서 모니터링 툴로 Prometheus와 Grafana를 사용하고 있으므로, prometheus에서 jmx의 메트릭을 수집할 수 있도록 돕는 jmx_exporter를 사용하여 prometheus와 연동하였습니다.
(Kafka Connect 메트릭과 관련해 더 자세한 내용은 여기를 확인해 보세요)
Kafka 토픽의 메시지가 잘 처리되고 있는지를 나타내는 Consumer Lag도 꼭 확인해야 할 메트릭 중 하나입니다. AWS MSK의 모니터링 설정을 통해 Cloud Watch에서 Consumer Lag을 확인할 수 있기에 Grafana Dashboard에서 Cloud Watch를 연동해 함께 확인하고 있습니다.
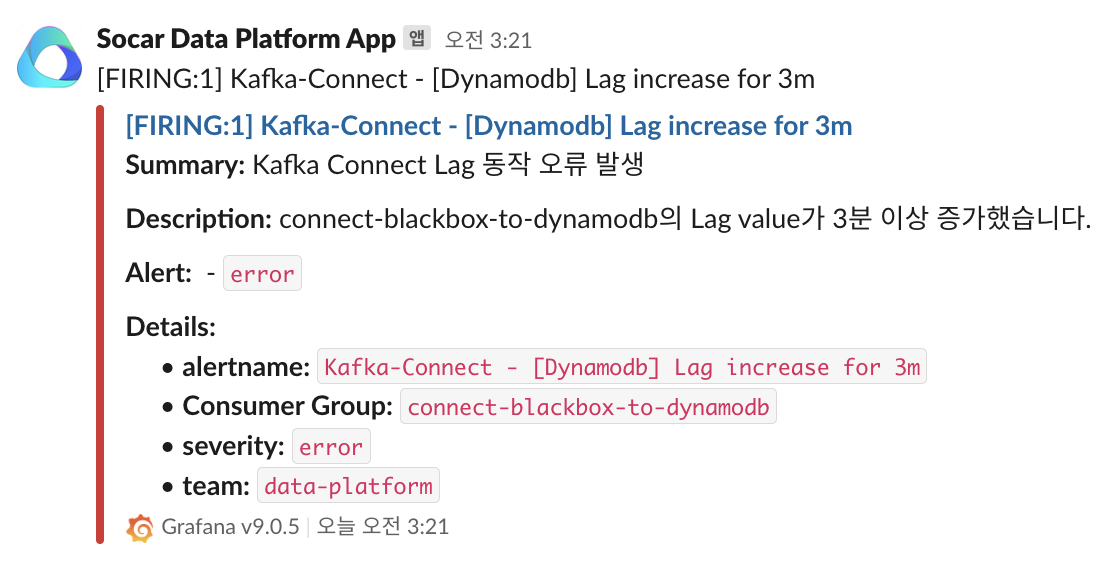 만약 모니터링 중 이상이 발생하는 경우
만약 모니터링 중 이상이 발생하는 경우 Grafana Alert를 사용해 슬랙 모니터링 채널로 메시지를 보내고 있습니다.
4. 배치 처리 플랫폼 : 반정형 데이터가 분석/집계되어 적재되기까지
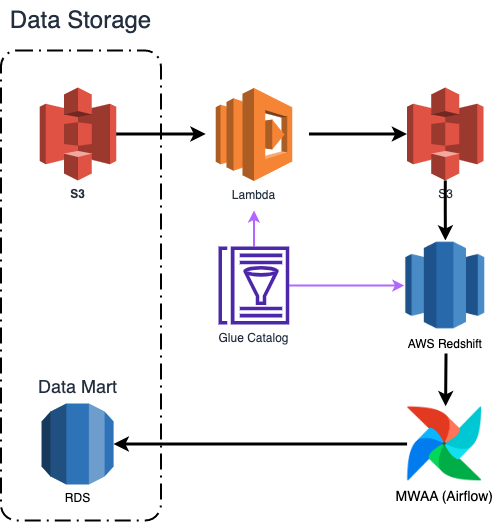
이번 장에서는 FMS 프로젝트에서 구축한 배치 처리 플랫폼에 대해 소개 드리겠습니다. 위에서 말씀드린 것처럼 차량의 이동 정보와 같은 실시간 조회의 경우 Redis를, 실시간 집계 및 준 실시간 데이터 조회에는 DynamoDB를 사용하였습니다. 배치로 처리되는 데이터는 본 플랫폼을 거쳐 데이터 마트(RDS)에 적재됩니다.
이번 장에서는 Lambda, Glue Catalog, Redshift를 중심으로 배치 처리 플랫폼을 설명드리겠습니다.
4.1. 요구사항 및 결정 사항
배치 처리 플랫폼 환경을 구축하기 위해 아래와 같은 요구사항들을 고려하였습니다.
분석가들이 쿼리를 작성할 수 있는 형태의 시스템이 필요합니다
고객사에게 운영 인사이트를 제공하기 위해 데이터 분석/집계 과정이 꼭 필요합니다. 데이터를 다루는 팀원들에게 익숙한 SQL 환경을 제공해 주는 것이 초기 비용 대비 생산성이 높다고 판단하였습니다. 따라서 Spark 같은 대용량 처리 엔진이 아닌 ANSI SQL에 호환되는 Athena나 Redshift로 선택지를 좁혔습니다. Athena는 AWS에서 제공하는 대화형 쿼리 서비스로 내부적으로 Presto 엔진을 사용하고 있습니다. 프로젝트 개발 초기에 Athena를 사용하다가 일부 윈도우 함수의 지원이 되지 않는 이슈가 확인되어, 윈도우 함수가 지원되고 퍼포먼스 측면에서도 이점이 있는 Redshift로 선택하였습니다.
S3에 적재된 데이터는 Redshift의 조회에 최적화되어야 합니다
또한 Column 기반 저장 포맷과 높은 압축률이 특징인 Parquet로 파일 포맷을 가져가는 것도 좋은 선택지입니다. Redshift Spectrum을 통해 S3에서 데이터를 조회할 때 탐색 시간과 비용을 줄이기 위해선 대표적으로 해야 하는 Practice들이 존재합니다 (더 자세한 내용은 여기를 확인해 주세요). 이 중에서 필수적으로 해야 할 것 중 하나는 쿼리의 풀 스캔을 막기 위해서 S3 객체들을 파티션에 따라 적재하는 것입니다(S3 Partititon 개념은 여기를 참고해 주세요)
S3 Sink Connector에 적재된 원본 Json 데이터는 여러 타입의 메시지들이 함께 포함되어 있습니다(위에서 언급했듯이 하나의 Kafka 토픽에 여러 메시지 프로토콜이 존재합니다). 따라서 Redshft에서 테이블 단위로 조회하기 때문에 메시지들로 같은 타입으로 분류되어 있어야 합니다.
위 방식들을 적용하기 위해서 원본 데이터를 전처리하여 S3에 적재하는 도구로 Lambda를 선택하였습니다.
주기적으로 분석/집계하는 쿼리를 실행하고 적재할 수 있어야 합니다
일, 주 단위 집계를 위해서는 주기적으로 Redshift 쿼리를 실행하고 중간 과정을 거쳐 데이터 마트에 적재해야 합니다. 집계 데이터 적재를 위한 데이터 마트는 조회가 용이한 RDS(Mysql)를 선택하였습니다. 또한 Redshift 쿼리 실행 및 적재를 위한 스케줄링 도구로 MWAA(Managed Worflow Apache Airflow)를 선택하였습니다. 데이터 본부에서는 Airflow 사용이 익숙하기도 하고 팀 내에서 Airflow 운영에 대한 전문성이 높기에 자연스럽게 결정하였습니다.
4.2. 배치 처리 플랫폼의 흐름
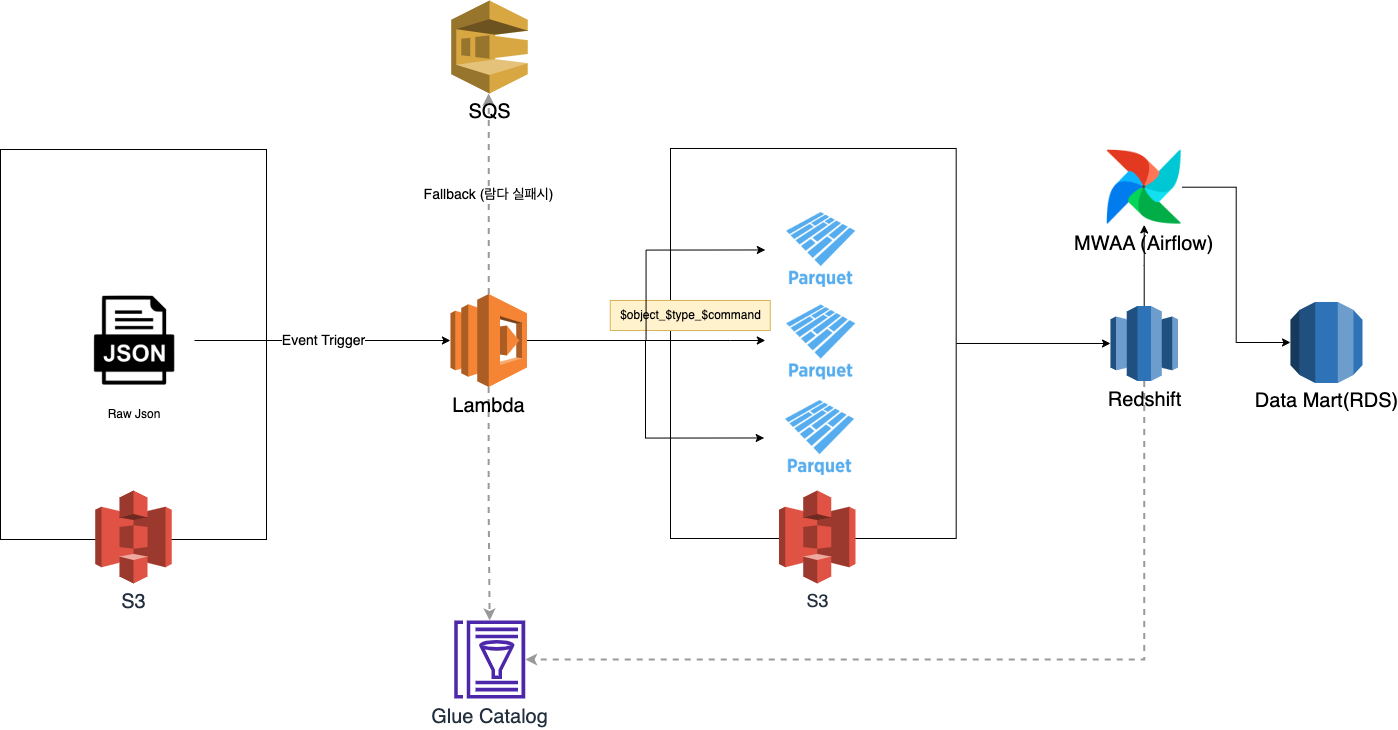
위 이미지를 통해 배치로 데이터가 처리되는 흐름을 파악할 수 있습니다.
1. S3 Sink Connector를 통해 차량 단말기의 데이터가 S3에 Json 포맷으로 적재됩니다.
5분 주기로 각 Kafka 토픽의 메시지들이 S3에 파티셔닝(Hive Partition) 되어 적재됩니다. 예를 들어 object=vehicle/type=kinematic/year=2022/month=12/day=25/hour=11과 같이 시간 분류를 위한 년, 월, 일, 시간과 메시지 프로토콜 별로 분류를 위한 파티션들로 각각 분류되어 데이터가 적재됩니다. 이렇게 파티션으로 분류된 데이터는 Athena, Redshift 같은 쿼리 엔진에서 데이터를 효율적으로 조회할 수 있습니다.
2. Lambda의 이벤트 트리거를 통해 원본 JSON의 타입별로 분류하여 Parquet로 형 변환하여 적재합니다
위 요구사항에서 언급한 것처럼, Redshift에서 효율적으로 조회하기 위해서 원본 데이터의 전처리 작업이 필요합니다. Lambda 함수는 타입별로 메시지를 분류하며 Parquet로 적재합니다. 이때 Redshift의 분석 패턴에 맞게 Range 스캔이 쉽도록 .../ymd=2022-12-25/hour=11 다음과 같은 파티션으로 변경해서 적재합니다.
적재하는 과정에서 Glue Table을 통한 메시지 Schema에 대한 검증을 진행하며 문제가 있다면 AWS SQS로 실패한 이벤트 정보를 전송합니다.
3. Airflow로 Redshift 집계 쿼리를 스케줄링하여 데이터 마트(RDS)에 적재합니다.
Airflow에서 Redshift 조회 결과를 Mysql(RDS)에 적재하기 위해서 Custom Operator를 구현해서 사용하고 있습니다. 또한 Airflow는 AWS 관련 Provider를 제공해 주기에 저희는 RedshiftSQLOperator를 사용하여 Redshift 조회 결과를 임시로 저장할 때 사용할 수 있었습니다.
4.3. Glue Data Catalog 활용
AWS Glue Data Catalog는 S3 데이터 레이크에 저장된 데이터들을 SQL 형태로 조회할 수 있도록 메타 스토어를 제공해 줍니다. 현재 S3에 저장되어 있는 프로토콜 별 경로에 맞춰 Glue Table을 생성하여 관리하고 있습니다.
Redshift에서 S3의 반정형 데이터에 접근하기 위해서는 External Table이라는 개념이 필요합니다. 실질적으로 External Table은 Glue Data Catalog의 Table과 동일하기에 Redshift의 S3 조회를 위해서는 Glue의 Table이 꼭 필요합니다. 따라서 각 프로토콜 별로 Glue Table을 생성해서 관리해 줘야 하며 처음부터 스키마를 일일이 만들어주는 것보단 Glue Crawler를 활용하면 자동화된 추론을 통해 손쉽게 스키마를 생성할 수 있습니다. 물론 정확하지 않기에 한 번 생성 후 수동으로 스키마를 다시 조정해 주는 작업은 필요합니다.
생성된 Glue Table은 Redshift뿐만 아니라 Lambda에서 S3 원본 객체를 전처리할 때 스키마를 검증하는 용도로도 수용되고 있습니다.
Glue Table은 AWS의 분석 환경에서 SoT(Source Of Truth)로 간주되며 이를 위해서는 스키마의 변경이 합의 없이 이뤄지면 안 됩니다. 따라서 Glue Crawler의 설정이나 외부 환경에서 Glue Table의 Schema 변경을 막는 방향으로 설정하는 것을 추천드립니다.
4.4. Lambda 함수의 주요 동작 및 구현
FMS 프로젝트에서 Lambda 함수는 원본 S3에 적재된 객체(Json 포맷)를 메시지 프로토콜 별로 분류하고 Parquet로 포맷을 형 변환하여 저장하는 역할을 합니다. 지정된 S3 Bucket의 객체가 생성되는 Put Event가 발생할 때 Lambda 함수가 트리거 되어 동작합니다. S3 객체가 생성되는 주기와 Lambda의 이벤트 처리 비용을 고려했을 때 경제적으로 가장 저렴하다고 판단하였습니다.
S3 Sink Connector에서는 Parquet로 적재를 지원해 주지만 Schema Registry가 필수적으로 필요하며, 원본 메시지도 Avro, Protobuf 같은 바이너리 포맷의 경우에만 지원을 합니다. 현재 차량 단말기에서 Json 포맷으로 메시지를 전송하고 있고 하나의 토픽에 여러 메시지 타입이 들어오는 경우 S3 Sink Connector에서 분류/형 변환 과정이 어렵습니다.
Lambda 함수를 구성하는 주요 라이브러리로 AWS Data Wrangler가 있습니다. AWS Data Wrangler는 Pandas를 기반으로 해서 AWS의 데이터 레이크 관련 서비스들을 연결하는 기능을 제공합니다. 대표적으로 AWS Glue, S3, Redshift, Athena 등을 쉽게 연결하여 사용할 수 있습니다. 특히 S3에서 Parquet 형식의 데이터 처리가 가능해서 형 변환을 손쉽게 할 수 있습니다 (더 자세한 내용은 여기를 참고해 주세요)
Lambda 함수의 구현부는 아래와 같습니다. 크게 다음과 같은 순서로 함수가 동작합니다.
- S3 Key에서 파티션 추출
- 파티션 요구사항에 맞게 새로운 파티션 생성
- 메시지 분류 작업
- 메시지 적재
Lambda 구현 코드
import json
import urllib.parse
import awswrangler as wr
from s3_format.s3_parquet_parser import S3ParquetParser
def lambda_handler(event, context):
parser = S3ParquetParser()
bucket = event["Records"][0]["s3"]["bucket"]["name"]
s3_key = urllib.parse.unquote_plus(
event["Records"][0]["s3"]["object"]["key"], encoding="utf-8"
)
...
# 1. s3 key를 통해 파티션 추출
partitions = parser.extract_partitions_from_s3_key(
s3_key=s3_key,
format="topics//year=/month=/day=/hour=/",
)
# 파티션 삭제 및 추가 작업
partitions.pop("topic")
partitions[
"ymd"
] = f"{partitions.get('year', '1972')}-{partitions.get('month', '1')}-{partitions.get('day', '1')}"
...
# 2. 메시지 분류하기
fields = ["object", "type", "command"]
classified = parser.classify_s3_json_into_field(
s3_bucket=bucket, s3_key=s3_key, fields=fields, partitions=partitions
)
# 3. 메시지 타입 별 S3에 적재하기
target_bucket = ...
glue_database = ...
for key, messages in classified.items():
_object, _type, _command = key.split("#")
glue_table = f"{_object}_{_type}_{_command}"
...
try:
result = parser.save_to_s3_in_parquet_with_partitions(
messages=messages,
partition_cols=[
"ymd",
"hour",
],
s3_bucket=target_bucket,
s3_prefix=f"formatted/object={_object}/type={_type}/command={_command}",
extra=extra_args,
)
print(f"Successful in loading {result}")
except Exception as e:
...
raise e
# wr.lakeformation.commit_transaction(transaction_id=transaction)
...
S3 Parquet 적재 관련 책임은 S3ParquetParser라는 모듈이 담당하고 있습니다. Lambda Layer로 배포되며 Lambda 함수에서 Import가 가능합니다. S3ParquetParser는 아래와 같이 구성됩니다.
S3ParquetParser 구현 코드
import json
import logging
from collections import defaultdict
from typing import Any, Dict, List, Optional
import awswrangler as wr
import boto3
import pandas as pd
from ttp import ttp
logging.getLogger().setLevel(logging.INFO)
class S3ParquetParser:
def __init__(
self,
boto3_session: boto3.Session = boto3.Session(region_name="ap-northeast-2"),
endpoint_url: str = None,
):
...
def extract_partitions_from_s3_key(
self, s3_key: str, format: str
) -> Dict[str, str]:
parser = ttp(s3_key, format)
parser.parse()
result = parser.result()[0][0]
if not result:
raise ValueError(f"해당 s3_key({s3_key})에 올바른 포맷({format})인지 확인해 주세요")
return result
def classify_s3_json_into_field(
self,
s3_bucket: str,
s3_key: str,
fields: List[str],
partitions: Optional[Dict[str, Any]] = dict(),
) -> Dict[str, list]:
s3 = self.session.client("s3", endpoint_url=self.endpoint_url)
result = defaultdict(list)
response = s3.get_object(Bucket=s3_bucket, Key=s3_key)
messages = response["Body"].read().decode("utf-8").splitlines()
for m in messages:
...
result[field_concat_key].append(obj)
return result
def save_to_s3_in_parquet_with_partitions(
self,
messages: List[dict],
partition_cols: List[str],
s3_bucket: str,
s3_prefix: str,
extra: dict = {},
):
df = pd.DataFrame.from_records(messages)
...
result = wr.s3.to_parquet(
df=df,
path=f"s3://{s3_bucket}/{s3_prefix}",
boto3_session=self.session,
dataset=True,
partition_cols=partition_cols,
**extra,
)
return result
메시지를 적재해 주는 save_to_s3_in_parquet_with_partitions에서는 AWS Data Wrangler의 s3.to_parquet를 사용합니다. Pandas Dataframe을 s3에 Parquet 형태로 저장해 주는데 이 과정에서 Glue Table과 연동이 가능합니다. 이를 통해 적재할 메시지들의 스키마가 Glue Table의 스키마와 일치하는지를 검증할 수 있으며, 파티션을 Glue Table에 추가해 줄 수 있습니다(이를 통해 Glue Crawler를 사용하지 않아도 되는 이점이 있습니다)
또한 메시지를 분류하기 위해서는 원본 Json 포맷을 Serialization 해야 합니다. 먼저 Pandas의 read_json으로 Dataframe 화해서 메시지를 분류하려고 했지만 처리 시간 및 메모리 사용량이 높은 이슈가 있었습니다. 따라서 str 객체의 splitLines와 json 모듈의 loads로 Serialization을 대체하였고 이를 통해 메모리 할당량을 절반 이하로 낮추고 처리 속도를 2배 이상 개선하였습니다.
4.5. Lambda 모니터링 및 Fallback 처리
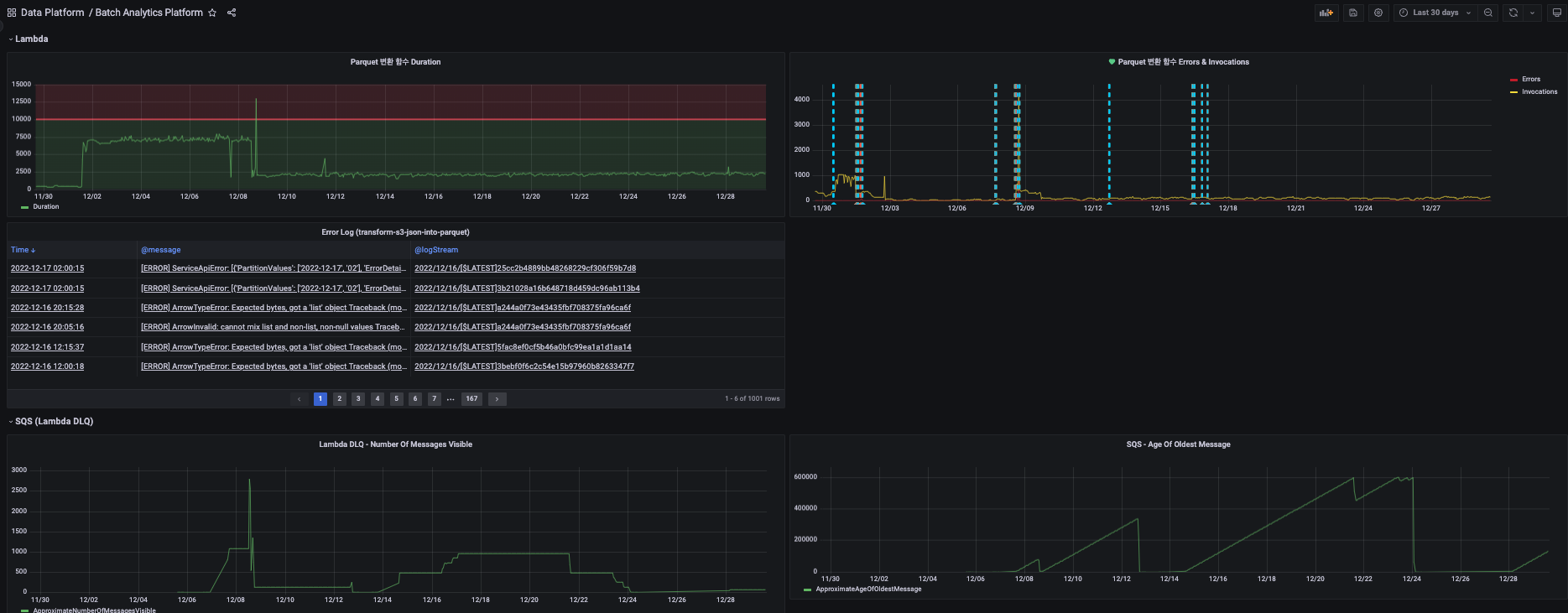 Grafana Alert와 연동한 Slack 메시지
Grafana Alert와 연동한 Slack 메시지
배치 처리 플랫폼의 모니터링은 마찬가지로 Grafana를 사용하고 있습니다. 현재는 주로 Lambda 함수에 대한 모니터링을 하고 있지만, Airflow의 데이터 신뢰성 검사 결과나 다른 리소스에 대한 지표들도 시각화할 계획을 하고 있습니다.
Lambda 함수가 실패하는 경우 Redshift에서 누락된 데이터를 조회하게 됩니다. 정합성을 보장해 주기 위해선 재처리를 할 수 있도록 Fallback 처리가 중요합니다. 따라서 Lambda에서는 이벤트가 실패할 때 SQS로 이벤트 정보를 보내도록 설정하였으며 문제 원인 파악 후 다른 Lambda 함수에서 SQS의 메시지를 소비할 수 있도록 하였습니다.
5. 마무리
비즈니스 요구사항에 따라 데이터 파이프라인, 더 나아가 소프트웨어는 매번 변화합니다. FMS 프로젝트도 마찬가지로 IoT라는 도메인, 차량 비즈니스라는 특징과 제약 사항에 따라 위와 같이 PoC 데이터 파이프라인을 구축하였습니다. 현재는 비용 경제적 관점을 우선시하여 기술 스택을 결정하고 개발하였지만, 추후 서비스가 안정화되고 더 많은 사용자들이 사용하게 된다면 운영 관점에서 새로운 선택 및 고도화를 진행하게 될 것 같습니다.
짧은 PoC 개발 기간에 다양한 팀들과 빠르게 커뮤니케이션하면서 일련의 데이터 파이프라인을 구축한 경험은 힘들었지만 정말 즐거웠습니다. 함께 파이프라인을 구축한 토마스, 루디, 피글렛과 차량 단말 파이프라인을 구축해 주신 라네 그리고 전체적인 AWS 인프라 환경을 구축해 주신 인프라팀 로원, 제이든에게 감사의 말을 전합니다.
1부에서는 주로 데이터 파이프라인의 구성요소에 대해 소개 드렸다면 다음 2부에서 데이터 파이프라인의 안정성을 높이고 데이터의 신뢰성을 위한 시도들을 풀어보겠습니다.