 알티
알티안녕하세요! 서비스 엔지니어링 본부 Cloud DB 팀의 알티입니다.
Cloud DB 팀은 Data Architect(DA)의 역할과 Database Administrator(DBA) 역할을 수행합니다. DA로서는 전사 데이터의 표준화와 데이터 거버넌스를 맡고 있으며, DBA로서는 쿼리 검수, 물리 데이터 모델링, 트러블 슈팅, 장애 대응, 신규 기술, 업무 자동화 등의 다양한 업무를 맡고 있습니다.
AWS re:Invent는 글로벌 클라우드 시장에서 가장 큰 사업자인 AWS(Amazon Web Service)가 매년 신규 서비스와 그 활용 사례를 발표하는 행사입니다. 쏘카에서 DBA 업무를 수행할 때 AWS에서 제공하는 다양한 서비스를 사용하고 있는데, 좋은 기회로 이번 2022년 AWS re:Invent에 참석을 하여 다음 내용을 배울 수 있었습니다.
- DB와 관련된 AWS 서비스의 Best Practice는 무엇인가?
- 각각의 서비스를 어떻게 유기적으로 연결하여 사용할 수 있는가?
- 글로벌 기업들은 대량의 트랜잭션을 다루기 위해 AWS 서비스를 어떻게 이용하였는가?
이 글에서는 AWS re:Invent의 세션 중 DB와 관련된 세션들과 저의 후기를 소개해 보려고 합니다. 다음과 같은 분들이 읽어보시면 좋습니다.
- AWS re:Invent 및 AWS의 신기능에 관심 있는 독자
- 데이터베이스 관리자(DBA)
- 데이터베이스에 관심이 있는 개발자
목차는 다음과 같습니다.
- AWS Re:Invent 소개
-
2.1. 목적에 맞는 데이터베이스
2.2 MemoryDB For Redis와 쿠버네틱스를 활용한 초고속 애플리케이션 구축
2.3. SQL에서 NoSQL로 점진적으로 마이그레이션
2.4. 데이터베이스의 블루/그린 최적화된 배포
2.5. 오픈소스(Trino)를 사용하여 AWS S3 데이터 조회
- 참석 후기
1. AWS re:Invent 2022 소개
 AWS re:Invent
AWS re:Invent
AWS re:Invent는 아마존 웹 서비스(Amazon Web Service)가 개최하는 최대 규모의 행사이며, 매년 AWS의 신규 서비스와 기존 서비스의 새로운 기능을 발표하는 자리입니다. 각 분야의 전문가 및 관계자들이 모여 Best Pratice를 발표하고 공유하며, AWS 외에도 다양한 솔루션 업체(GitLab, Redis, Docker, MariaDB 등등)의 서비스 소개를 들을 수 있는 컨퍼런스 입니다.
2. DB와 관련된 세션 소개
AWS re:Invent에서는 DB와 관련하여 글로벌 기업들의 아키텍처 구성, 데이터베이스와 결합한 서비스를 제공한 사례 등에 대한 다양한 세션이 있었습니다. DB와 관련된 총 10개의 세션 중 인상 깊었던 5개의 세션들을 아래에 소개합니다.
2.1. 목적에 맞는 데이터베이스
이 세션에서는 현대 MSA(Microservice Architecture) 환경에서 목적에 맞는 데이터베이스 선택(Purpoose-built database apporach)의 중요성과 실제 기업의 데이터베이스 컨설팅 사례를 살펴봅니다.
MSA를 구성하는 각 서비스들은 확장성, 고가용성, 보안성, 성능 측면에서 각자 필요한 스펙이 다르기 때문에 그 목적에 맞는 데이터베이스를 선택하는 게 중요합니다. 예를 들면 목적에 따라서 Relational / Key-value / Caching / Time-series 등 여러 형태의 Database Portfolio에서 적절한 DB를 선택하고 성능을 개선할 수 있습니다.
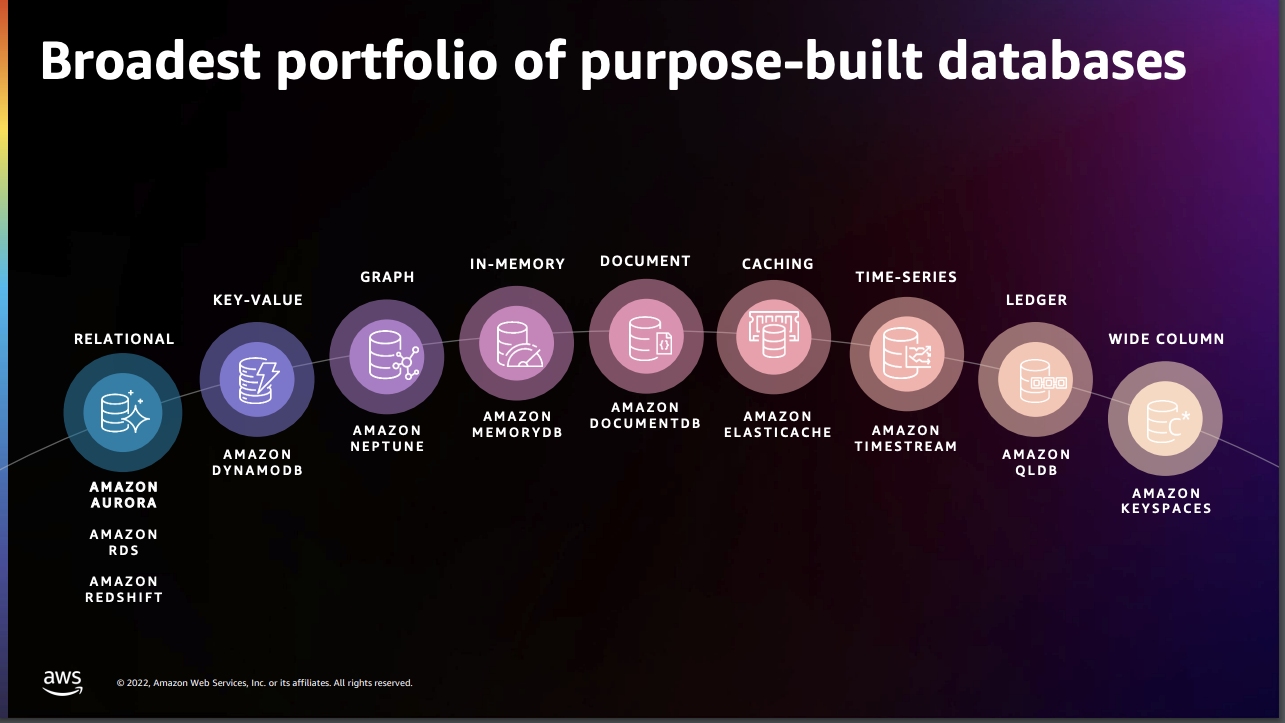 AWS 가 제공하는 다양한 Database
AWS 가 제공하는 다양한 Database
구체적인 사례로는 Twilio라는 기업이 Postflight에서 Amazon DynamoDB로 이관하여 Data Delay 와 비용을 줄인 케이스와, ADP가 Amazon Neptune 을 사용하여 성능을 10배 이상 개선한 케이스 등을 살펴보았습니다.
개인적으로는 데이터도 사람처럼 성격과 성향이 있다고 생각합니다. 특히 데이터 모델링 시 이러한 데이터의 특성을 고려하여 알맞은 데이터베이스를 사용하는 것이 필수적입니다. 추후에 데이터가 방대하게 쌓이고 난 후에는 간단한 작업이 큰 작업이 되거나 성능에 큰 영향을 미칠 수도 있기 때문입니다. 구체적으로는 단순 조회 작업에 오랜 시간이 소요되거나 CPU 부하가 발생할 수도 있습니다.
목적에 맞는 데이터베이스 선택의 예는 다음이 있습니다.
- 실시간 위치를 조회하는 데이터의 경우 지속적으로 RDBMS에 UPDATE 작업을 진행해야 하는데, 이 경우 RDBMS에 대량의 데이터를 적재하기보다는 DynamoDB를 활용하는 것이 좋을 수 있습니다.
- 실시간 데이터가 필요하다면 Redis를 활용하고 데이터 손실을 줄이기 위해서는 MemoryDB for Redis를 사용할 수 있습니다.
- 추가로 데이터 손실을 감수하더라도 조금 더 빠른 조회를 원한다면 Memcached를 이용하면 안정적인 서비스를 제공할 수 있습니다.
이 세션을 통해 다시금 “목적에 맞는 데이터베이스 선택”의 중요성을 깨닫고, 개발자와 모델링 협업 과정에서 해당 부분에 대해 어떻게 잘 커뮤니케이션할 수 있을지에 대해 고민해 볼 수 있었습니다.
슬라이드 출처 : How-ADP-and-Twilio-realize-business-vision-with-purpose-built-databases
2.2 MemoryDB for Redis와 쿠버네틱스를 활용한 초고속 애플리케이션 구축
해당 세션에서는 Kubernetes와 MemoryDB for Redis 결합을 통한 애플리케이션 구축의 Best Pratice를 소개했습니다. 세션 마지막에는 소개한 구성을 실제로 구현하는 데모도 진행되었는데, 실습 내용을 포함한 전체 발표 자료는 링크에서 보실 수 있습니다.
구체적으로는 AWS EKS를 통해 Kubernetes 환경에서 MicroService Architecture(MSA) application 을 구성하는 방법과, MSA에 Memory DB for Redis가 적합한 이유를 소개하였습니다.
전체적인 구성은 아래와 같습니다.
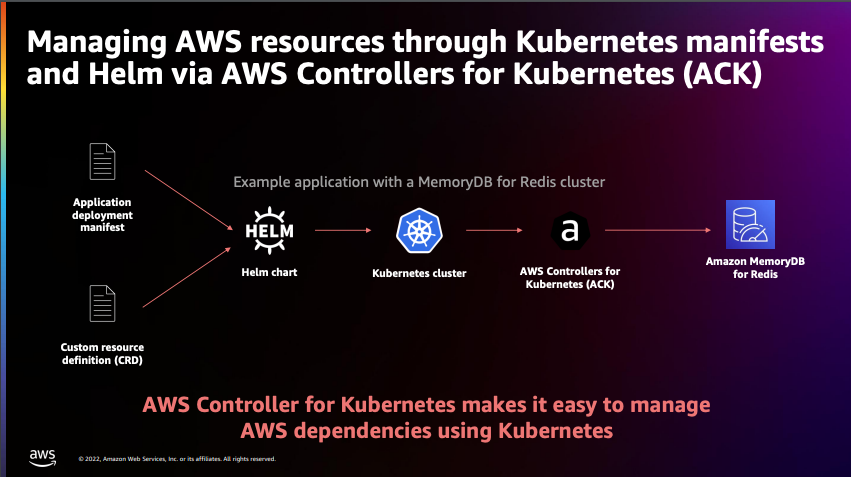 ACK(AWS Controllers for Kubernetes)를 활용한 전체적인 아키텍처
ACK(AWS Controllers for Kubernetes)를 활용한 전체적인 아키텍처
세션 초반부에는 MSA의 정의와 Managed Service 로서의 AWS EKS의 장점, AWS Controller for Kuberenetes를 통해 리소스를 관리하는 방법들을 설명합니다.
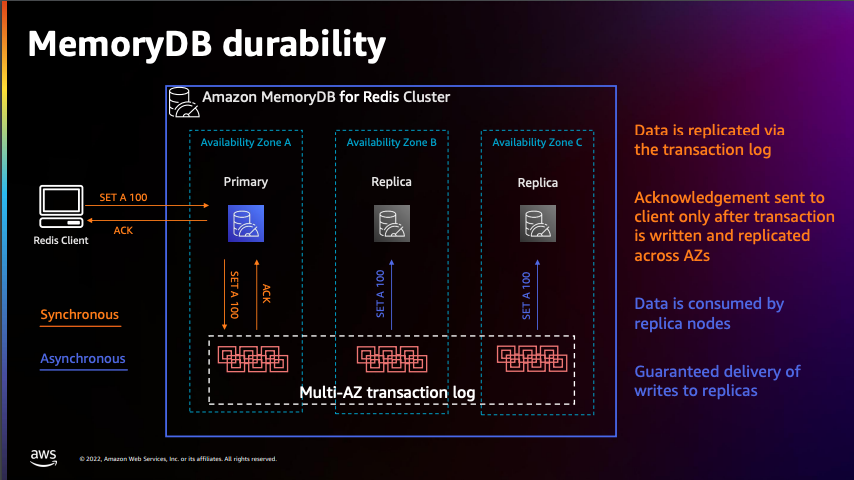 Memory DB For Redis 스토리지는 WRITE 작업 시 Log를 남겨 데이터 유실을 방지합니다.
Memory DB For Redis 스토리지는 WRITE 작업 시 Log를 남겨 데이터 유실을 방지합니다.
해당 세션을 들으면서 빠른 응답속도를 보장하기 위해 쿠버네틱스와 함께 데이터의 손실을 방지하고자 Memory DB for Redis를 사용하는 이유를 알아볼 수 있었습니다. MemoryDB for Redis는 Aurora와 동일한 스토리지 구성을 가지고 있는데 이것은 데이터 안정성 면에서 큰 장점입니다. Memory 기반의 데이터베이스인 Redis는 빠른 Return을 보장하지만 데이터에 대한 내구성이 떨어질 수 있는데 관계형 데이터베이스와 동일한 스토리지 구성을 가지면 데이터의 손실이 발생하지 않도록 보장됩니다.
해당 세션에서는 DB뿐만 아니라 전반적인 인프라 지식도 얻을 수 있었니다. 쏘카의 DB 팀은 각종 데이터베이스 구성과 네트워크 설정 작업 시 인프라팀과 긴밀하게 협업을 하고 있는데, 이런 업무 시 인프라팀과 커뮤니케이션에 도움이 되는 세션이었습니다.
슬라이드 출처 : Build-stateful-K8s-applications-with-ultra-fast-Amazon-MemoryDB-for-Redis
2.3. SQL에서 NoSQL로 점진적으로 마이그레이션
이 세션은 관계형 데이터베이스에 적재된 데이터를 In-Memory 기반의 데이터베이스에 데이터를 이관하는 방법을 소개합니다.
이기종 간의 데이터베이스 동기화 및 이관작업은 상대적으로 동일한 데이터베이스로 이관하는 것보다 버전, 호환성 측면에서 신경쓸 부분이 많습니다. 사용되는 모든 쿼리의 결과를 메모리형 데이터베이스에 적재하면서 동시에 운영 중인 데이터를 동기화해야 하기 때문입니다.
마이그레이션 패턴 순서(RDBMS → NoSQL)
운영중인 데이터베이스를 중단하지 않고 (다운타임을 발생시키지 않고) NoSQL로 이관하기 위해서는 RDBMS에서 NoSQL로 마이그레이션을 위해서는 아래와 같은 순서로 작업이 진행됩니다.
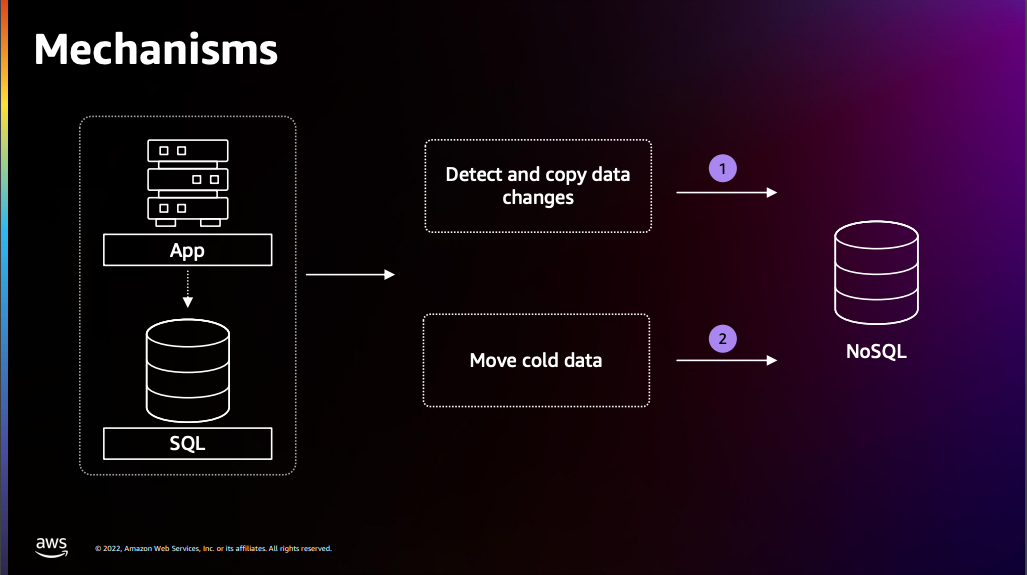 마이그레이션 시 Cold Data 와 Hot Data를 나눠 작업합니다.
마이그레이션 시 Cold Data 와 Hot Data를 나눠 작업합니다.
- Lift and Shifts 방식으로 OS, 데이터, 애플리케이션을 그대로 옮기는 작업을 진행
- 요구사항에 맞는 구성으로 설계 (Ex. On-promise 환경 → Cloud 환경)
- RDBMS의 쿼리 결과를 Key-value로 변환
- Cold / Hot Data의 적재 및 조회 방안 구성
Data는 사용 빈도에 따라 크게 Cold Data와 Hot Data로 분류됩니다.
Cold Data란 자주 사용되지 않는 데이터를 지칭하며,
Hot Data는 자주 사용되며 즉시 액세스해야 하는 데이터 (SELECT/UPDATE/DELETE 작업이 발생하는 데이터)를 지칭합니다.
마이그레이션 시 이런 데이터의 특성을 이해하고 각 특성에 맞게 마이그레이션 방안을 구성하는 것이 매우 중요합니다.
Cold Data Migration
Cold Data의 경우 Access 요청이 발생하지 않기 때문에 이관작업의 Key-value 변환 외에는 크게 복잡하지 않습니다. 다만, 트랜잭션이 많이 발생하는 시간대를 피해서 Cold Data의 이관작업을 진행해야합니다.
Hot Data Migration
Hot Data의 경우 실시간으로 변경이 일어나기 때문에 Cold Data 보다 작업이 복잡합니다. 운영 중인 데이터베이스에서 어떤 데이터 요청이 발생하는지 정확히 파악하기에는 한계가 존재하기 때문에 READ / WRITE / 변경 요청의 분류에 따라서 아래 Mechanism 을 따라 마이그레이션을 진행합니다.
| Mechanism | 설명 |
|---|---|
| Read 요청 | - NoSQL 데이터베이스에 READ Request 요청 - NoSQL에서 데이터가 없어 Return을 못하는 경우, RDBMS에 READ Request 요청 - RDBMS Return 과 함께 해당 데이터를 NoSQL로 Write 작업 진행 |
| Write 요청 | - NoSQL 데이터베이스로 Write 요청 - RDBMS에 해당 Write 작업 결과가 존재하는지 확인 - NoSQL에 데이터가 적재되지 않았다면, RDBMS → NoSQL로 데이터 적재 |
| 변경 요청 | - RDBMS와 변경 건에 대한 DMS(Data Migration Service)를 이용하여 진행 - 실시간 데이터 스트림 서비스인 Kinesis로 DMS로 연결 - Lambda를 이용하여 변경 건에 대한 Trigger 진행 |
해당 세션에서는 실제 마이그레이션 작업에 못지않게 작업 대상에 대한 데이터의 전수조사가 중요하다는 것을 배웠습니다. 실제로 데이터가 어떻게 요청되고 있는지를 알아야 정확한 마이그레이션을 정확하게 진행할 수 있었습니다.
또한 일반적으로 마이그레이션은 Mysqldump, Orcale datapump 등 마이그레이션 툴을 이용하여 작업을 진행하는데,
해당 세션에서는 Python Script를 이용하여 운영 중 요청이 들어오는 쿼리를 확인하고 그 결과를 NoSQL으로 적재하는 방법을 소개했습니다.
결과적으로 좀 더 섬세하고 복잡한 마이그레이션을 안정적으로 진행하는 법을 배울 수 있었던 의미 있는 세션이었습니다.
슬라이드 출처 : Modernize-and-gradually-migrate-your-data-model-from-SQL-to-NoSQL
2.4. 데이터베이스의 블루/그린 최적화된 배포
Blue/Green Optimized 세션은 Aurora의 버전 업그레이드와 관련하여 AWS 발표한 새로운 기능에 대해 소개하는 세션입니다. 데이터베이스의 버전 업그레이드와 그 과정에서 발생하는 다운타임을 고려하는 것은 DBA 입장에서 매우 중요한 부분이라 개인적으로도 가장 듣고 싶었던 세션이었습니다.
이 세션에서는 기존의 방식보다 안전하게 최대 1분 이내로 업그레이드 작업을 진행할 수 있다고 발표하였습니다.
Blue/Green Deployment는 보통 서버에서 자주 이용되는 무중단 배포 기법 중 하나이며, 구 버전과 새 버전을 동시에 운영 환경에 띄워놓고 구 버전에서 새 버전으로 트래픽을 서서히 이동시키는 방법입니다. DB의 Blue/Green Deployment는 다음 순서로 진행됩니다.
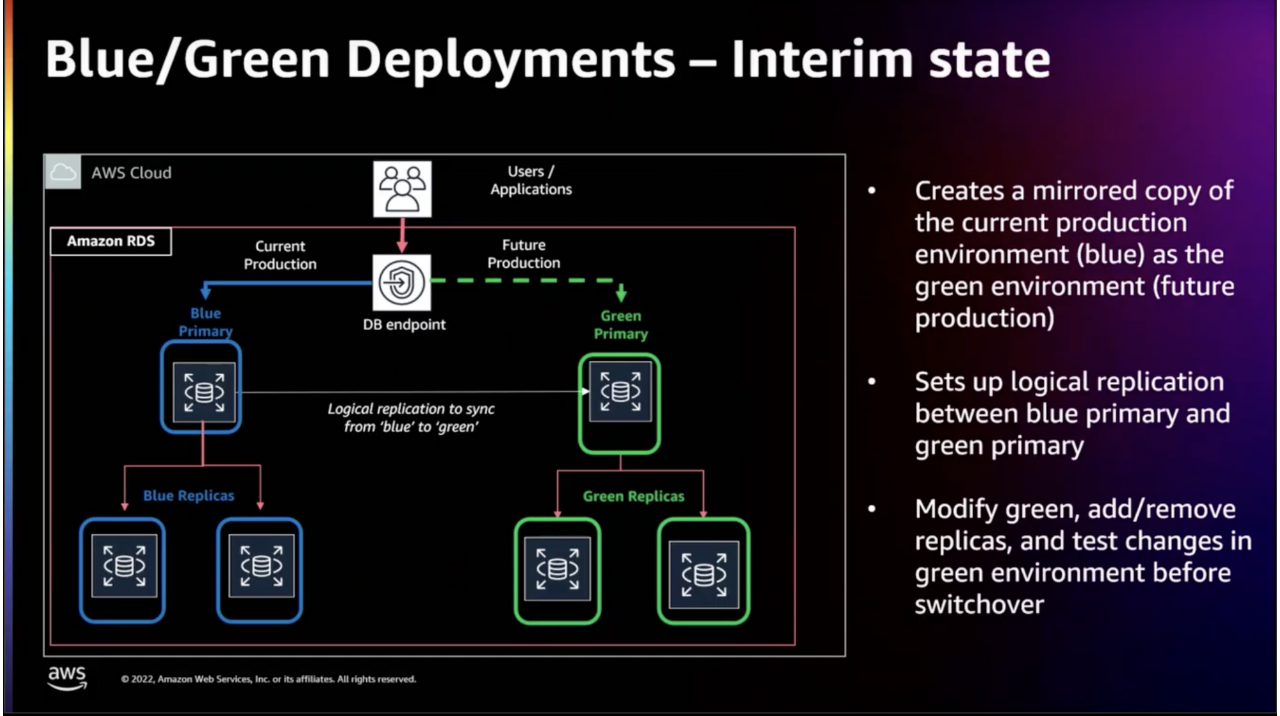 Blue-Green Deployment
Blue-Green Deployment
- Blue → Green 간의 Logical Replication
- Blue에서 발생하는 모든 변경 사항을 Green에서 미러링하도록 설정
- 변경 복제를 이용한 여러 수준의 Replication 지원(One-Level 복제)
- 메트릭을 모니터링하여 Replication이 최신 상태인지 확인
- RDS 인스턴스 버전 업그레이드 완료 및 데이터 검증
- Blue(업그레이드 이전) 인스턴스 삭제
해당 세션을 듣고 정말 1분 이내에 업그레이드 Switch Over를 완료할 수 있을지에 대해 의문이 들었습니다. 개발 계정에서 신규 Aurora MySQL RDS Instance를 생성하여 Blue/Green Deployment 테스트를 진행했습니다.
테스트 진행 절차
테스트 세팅
- 신규 RDS Instance 생성(Aurora MySQL 5.7)
- 더미 데이터 Import 수행 (5GB 데이터 적재)
- Blue/Green 설정
- Blue - Aurora MySQL 5.7
- Green - Aurora MySQL. 8.0
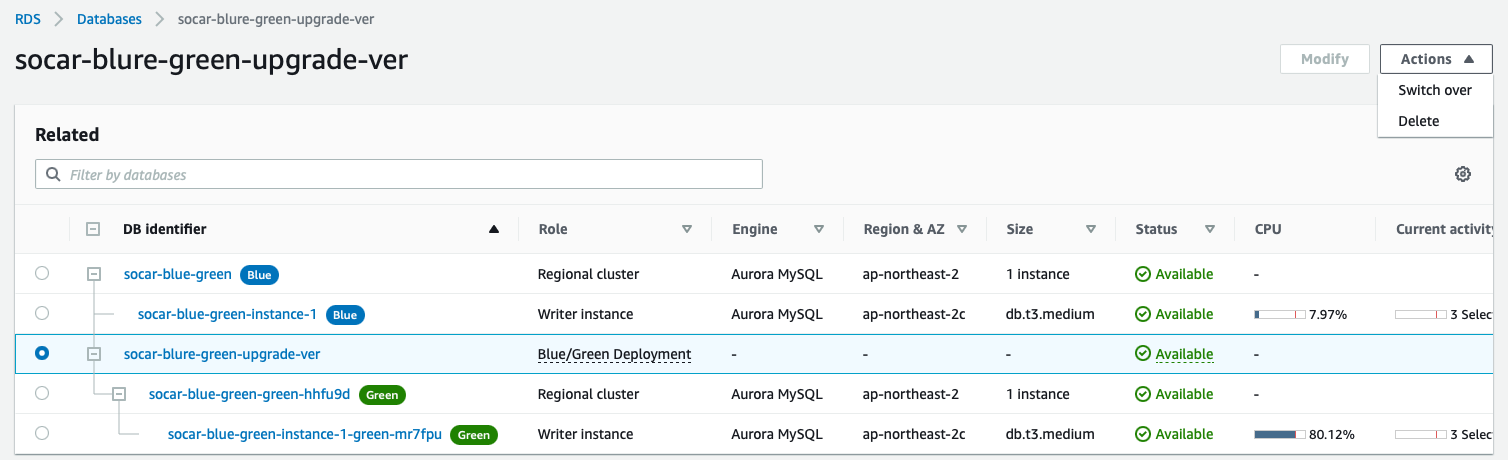 Blue-Green Deployment Test
Blue-Green Deployment Test
테스트 과정
- Blue/Green 커넥션 확인
- 작업 중 New Connection 연결 시 Connection Error 미발생
db.t3.medium기준 약 21분 소요
- Logical Replication 확인
- Blue의 데이터 변경 작업(DML/DDL) 진행 시 Green에도 정상적으로 반영 확인
- Switch Over를 이용하여 Green → Blue 배포 진행
- 읽기 작업은 Blue(운영) 쪽에서 진행 가능
- 내부적으로 Bin Log를 기준으로 미러링 확인
- Major/Minor 버전 업그레이드 포함
이때 Switch Over 시 Timeout Setting 을 1분으로 설정했을 때, 실제 배포 과정이 1분이 초과되어 자동으로 Rollback이 되었습니다. Timeout Setting을 3분으로 늘려 재실행 했을 때는 정상적으로 Blue/Green Deployment이 완료되었습니다.
Switch Over 결과
 Blue/Green Deployment 완료 후 위와 같이 분리
Blue/Green Deployment 완료 후 위와 같이 분리
실제 작업은 위와 같은 방법으로 작업이 수행되며 db.t3.medium 기준으로 약 $91의 비용이 소요됩니다.
세션에서 들었던 것과 달리 Timeout을 1분으로 설정했을 때 Switchover 작업이 실패하였는데 정확한 원인은 파악하지 못하였습니다. 혹시 1분 기준으로 테스트를 성공하신 분이 있다면 댓글 부탁드립니다.
세션에서 소개된 내용은 빠르고 안정적이나 추가로 인스턴스가 생성되기 때문에 추가 비용이 발생할 우려가 있습니다. 또한 새로운 기능을 운영에 적용하기에는 보수적으로 생각해야 하기에 실제 적용에는 여러 고민이 되는 점이 있었습니다. 하지만 이러한 새로운 기능을 접할 수 있어 좋았으며 AWS의 RDS가 점점 발전하고 있다는 것을 느꼈습니다.
슬라이드 출처 : Amazon-RDS-Blue-Green-Deployments-Optimized-Writes-and-Optimized-Reads
2.5. 오픈소스(Trino)를 사용하여 AWS S3 데이터 조회
해당 세션은 Open-source인 Trino를 이용한 S3 데이터 접근 방법에 관련된 세션입니다. S3의 데이터를 조회하기 위해서는 기존에는 AWS가 제공하는 서비스인 Athena를 이용하여 데이터를 조회하여 쿼리 결과를 얻을 수 있습니다.
다만, Athena를 이용하여 쿼리 결과를 얻기 위해서는 서울 리전을 기준으로 1TB 당 $5의 비용이 발생합니다. 하지만 이번 세션에서는 Trino를 이용하여 Athena의 조회 비용을 제거하고 쿼리 성능을 개선하는 방법을 소개하고 있습니다. 단, EMR(Elastic MapReduce)의 Computing 비용을 지불합니다.
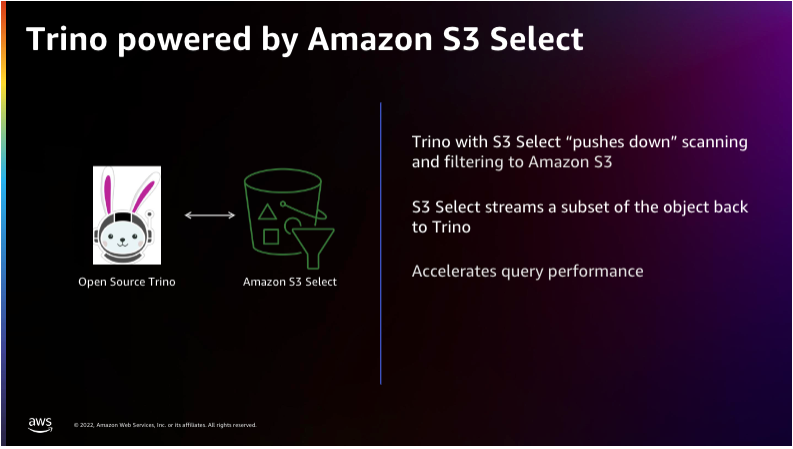 Trino와 AWS S3 Select
Trino와 AWS S3 Select
이러한 속도를 낼 수 있는 것은 Pushdown이라는 기능 때문입니다. 그 이유는 MySQL에서도 비슷한 기능이 존재하며 Index Condition Pushdown 과 유사하기 때문입니다. 스토리지에 Index를 밀어 넣어 필요한 데이터만을 그대로 가지고 메모리에 올려놓고 결과를 반환하는 과정과 유사합니다.
마찬가지로 S3 Select는 지정된 바이트 수만큼 CSV 파일에서 Range Scan(범위)을 전체 객체 스캐닝을 병렬로 처리하여 속도가 빠릅니다.
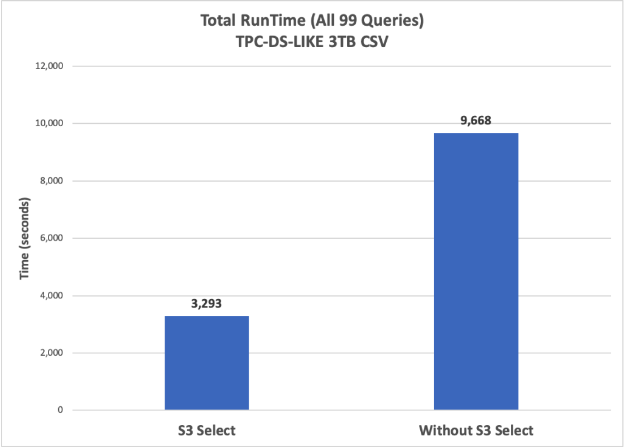 AWS S3 Select를 사용했을 때의 조희 성능 차이
AWS S3 Select를 사용했을 때의 조희 성능 차이
위 그림은 S3 내 CSV 파일 데이터를 조회하는 속도를 보여 줄 수 있는 성능 그래프입니다. S3 내 압축되어 있지 않은 3TB의 CSV 데이터를 조회할 때 S3 Select를 이용했을 때와 아닐 때의 RunTime 차이를 알 수 있습니다.
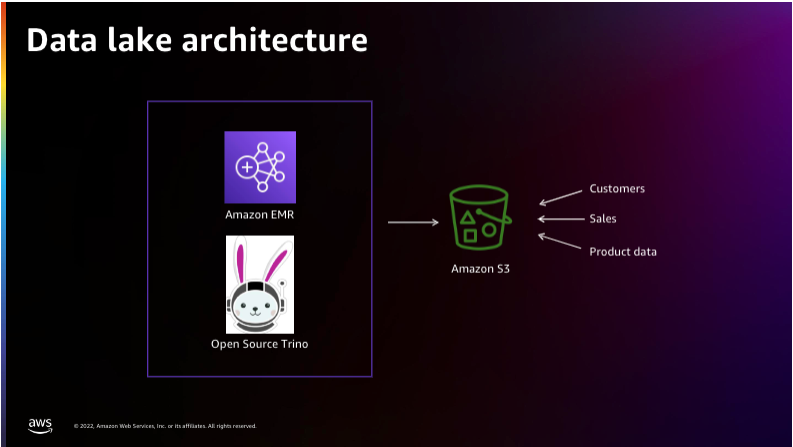 데이터 레이크 구조
데이터 레이크 구조
위 그림은 데이터 레이크 아키텍처를 소개한 것으로, Amazon EMR(Elastic MapReduce)에 Trino를 설치하여 S3를 연동하여 쿼리를 실행할 수 있는 SQL 쿼리 엔진을 보여줍니다.
일반적으로 데이터베이스에서 더 이상 사용되지 않는 정적 데이터는 S3로 이관하는 것을 지향합니다. 불필요한 데이터는 테이블을 무겁게 하고 성능에도 영향을 미치며, 대량의 테이블에서는 ALTER 작업에도 CPU 부하를 유발할 수 있기 때문입니다.
테이블의 경량화를 위해 S3로 이관하고 사용 빈도가 적은 데이터를 빠르게 조회할 수 있는 방법에 대해 알아볼 수 있었던 세션이었습니다. 또한 쏘카에서는 S3에 적재된 데이터를 Athena를 이용하여 조회를 하고 있는데, Athena 외에도 대체 방안을 알 수 있어서 좋았습니다.
슬라이드 출처 : Accessing-data-lakes-in-Amazon-S3-using-open-source-projects.
3. 참석 후기
업무에 AWS 툴을 다양하게 활용하고 있는 입장에서 AWS re:Invent를 통해 AWS에서 직접 진행하는 발표와 데모를 들어볼 수 있어 좋았습니다. 특히 관심 있는 DB 툴에 대해 Deep Dive 하고 Insight를 가져볼 수 있는 값진 시간이었습니다.
세션 뿐만 아니라 수백개의 파트너 사가 AWS와 관련된 솔루션을 홍보하는 자리기도 해서, re:Invent 행사가 단순히 콘퍼런스의 개념만 가지고 있는 것이 아니라 클라우드 기술을 통합하는 장소라는 것을 느꼈습니다.
마지막으로 AWS re:Invent를 참석할 수 있는 기회를 주신 본부장님 아나킨과 그룹장님 제이든, 인프라 팀장님 로원께 감사드리며, 값진 시간을 보낼 수 있도록 도움을 주신 서비스 엔지니어링 본부 및 오퍼레이션 그룹 구성원분께 감사 인사를 드립니다. 긴 글 읽어주셔서 감사합니다.
