 그랩
그랩안녕하세요. 데이터 플랫폼 팀의 그랩입니다.
본 글은 “신사업 FMS 데이터 파이프라인 구축기”의 2편으로 클라이언트에게 신뢰성 높은 데이터를 제공하기 위한 노력들을 다룹니다. PoC 제품 출시까지 시간이 제한된 상황에서도 데이터와 데이터 파이프라인에 대한 신뢰성을 높이기 위해서 테스트 환경 구축도 함께 고려하였습니다. 본 글에서는 안정적인 데이터 파이프라인 구현을 위해 E2E 테스트 및 부하 테스트를 적용하고, 높은 데이터 퀄리티를 보장하기 위해 데이터 검증/모니터링을 구성한 작업을 소개하려고 합니다. (1편은 링크를 참고 부탁드립니다.)
다음과 같은 분들이 읽으면 좋습니다.
- 실시간 데이터 파이프라인에 관심이 있는 소프트웨어 엔지니어
- 데이터 파이프라인에 테스트를 도입하고 싶은 소프트웨어 엔지니어
- 데이터 퀄리티를 높이기 위한 시도들이 궁금한 데이터 업계 종사자
- AWS 기반의 데이터 엔지니어링 환경 구축에 관심이 있는 소프트웨어 엔지니어
- 쏘카의 데이터 엔지니어가 무슨 일을 하는지 궁금한 모든 이들
목차는 아래와 같습니다.
- 데이터 파이프라인 테스트 소개
- 소프트웨어 테스트, 견고한 파이프라인을 E2E 테스트 환경 구축하기
- 부하 테스트, 시뮬레이터를 활용한 실 데이터 기반의 테스트
- 데이터 퀄리티 테스트, 높은 데이터 퀄리티를 위한 환경 구축하기
- 마무리
글을 읽으면서 궁금한 점들에 대해서 편하게 댓글 남겨주시면 답변드리겠습니다.
1. 데이터 파이프라인 테스트 소개
일반적으로 데이터 플랫폼의 주요 클라이언트는 인하우스인 반면 FMS 프로젝트의 경우 B2B 비즈니스 고객을 대상으로 합니다. 따라서 데이터에 대한 SLO(Service Level Objective)를 엄격하게 설정하고 플랫폼을 안정적으로 운영해야 합니다.
FMS 프로젝트는 실시간, 준-실시간, 배치 처리된 데이터를 모두 필요로 하기 때문에 전체 데이터 파이프라인에 대한 신뢰성과 가시성이 중요합니다. 클라이언트가 사용하는 데이터가 정합성, 무결성이 깨지지 않도록 퀄리티를 높게 유지하는 것도 중요합니다.
1.1. 데이터 파이프라인 테스트 종류
데이터 파이프라인을 구축할 때 적용하는 테스트는 크게 두 가지로 구분할 수 있습니다. 바로 소프트웨어 테스트와 데이터 퀄리티 테스트입니다.
소프트웨어 테스트는 소프트웨어가 기대하는 역할을 잘 수행하는지를 검증하는 과정입니다. 넓게는 하나의 컴포넌트(Kafka Consumer, Lambda 등)가 될 수도 있으며 좁게는 특정 클래스의 함수가 될 수도 있습니다. 데이터 파이프라인에서 특정 컴포넌트가 제대로 동작하지 않는다면 Downstream 컴포넌트는 당연히 동작을 하지 않고 제대로 된 데이터 변형/적재가 힘들어집니다. 즉 각 컴포넌트가 SPoF(Single Point of Failure)가 되기 쉽기 때문에 동작을 충분히 신뢰할 수 있도록 테스트를 작성하는 것이 중요합니다.
데이터 퀄리티 테스트는 데이터가 요구사항에 맞게 잘 변형/적재되었는지 검증하는 과정입니다. 데이터 파이프라인을 거치면서 데이터는 다양하게 변형되는데 이때 최종적으로 사용자가 조회하는 데이터의 퀄리티가 높은 수준으로 보장되어야 합니다. 만약 특정 레코드가 누락됐거나 칼럼의 값이 이상하다면 데이터를 신뢰할 수 없게 됩니다. 따라서 생성되는 데이터가 정합성, 무결성 등이 잘 지켜졌는지 주기적으로 검사해서 데이터의 퀄리티를 높게 유지해야 합니다.
1.2. 소프트웨어 테스트의 종류
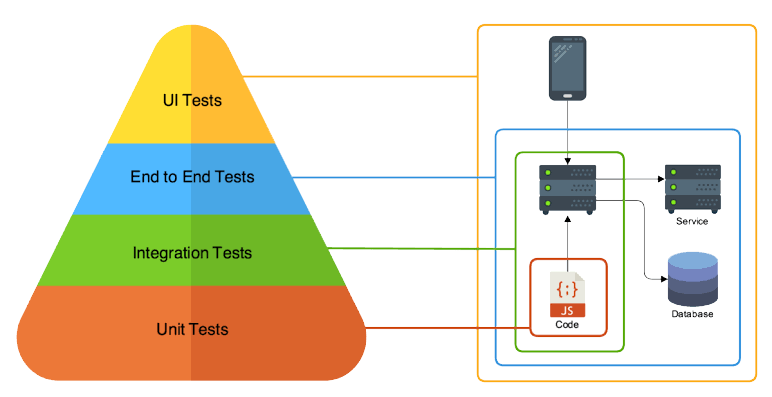
소프트웨어를 테스트할 때 많이 나누는 분류 기준으로 Unit Test(단위 테스트), Integration Test(통합 테스트), E2E Test(종단 간 테스트)가 있습니다.
Unit Test(단위 테스트)
- 가장 작은 단위(Unit)의 테스트입니다. 단일 기능을 가지는 함수, 클래스의 메서드가 잘 작동하는지 테스트할 때 많이 사용됩니다.
- 가장 간단하고, 직관적이며, 빠르게 실행과 결과를 볼 수 있는 테스트입니다.
Integration Test(통합 테스트)
- 여러 요소를 통합(Integration) 한 테스트를 말합니다. 데이터베이스와 연동한 코드가 잘 작동하는지, 여러 함수와 클래스가 엮인 로직이 잘 작동하는지 등을 확인합니다.
- 유닛 테스트보다는 복잡하고 느리지만, 소프트웨어는 결국 여러 코드 로직의 통합이라는 점에서 통합 테스트 역시 중요합니다.
E2E Test(종단 간 테스트)
-
E2E는 End To End의 약자로, 끝에서 끝, 즉 클라이언트 입장에서 테스트해 보는 것입니다. 예를 들어 Lambda 함수의 Input으로 Event 정보를 넣었을 때 Output으로 S3 객체가 잘 생성되었는지 확인하는 것도 E2E 테스트로 볼 수 있습니다.
-
테스트하는 대상의 Input과 Output이 명확해졌을 때 작성해야 하며 외부 의존성도 함께 구현해서 테스트하게 됩니다. 예를 들어 Lambda 함수의 E2E 테스트를 할 때 S3라는 외부 의존성이 필요합니다.
-
테스트 중 가장 신경 써야 할 것이 많지만 내부의 구현이 변경돼도 검증이 유효하며 시나리오에 맞춰 테스트할 수 있어 검증의 폭이 넓다는 장점이 있습니다.
1.3 데이터 퀄리티 정의
데이터 퀄리티는 도메인/소프트웨어 요구사항에 맞도록 정확해야 하며 누락/중복 등의 문제가 있어서는 안됩니다. 데이터 퀄리티가 높다는 것은 쉽게 이야기해서 정합성과 무결성을 지키고 있는 것을 의미합니다.
데이터 정합성은 양쪽의 데이터가 모순되지 않고 일치하는 것을 의미합니다. 예를 들어 A 저장소에 있는 원본 데이터를 가공해서 B 저장소로 적재했을 때 가공한 결과 레코드와 B 저장소에 저장된 값 레코드가 정확히 일치하지 않는다면 이는 정합성이 맞지 않음을 의미합니다.
데이터 무결성은 데이터가 일관되고 정확해야 함을 의미합니다. 예를 들어 A 테이블의 B 칼럼은 Non Null이어야 하며 C 칼럼은 비즈니스 규칙에 따라 값의 범위가 0~100이어야 하는 등의 조건이 있다면, 특정 레코드가 이를 어겼을 때 무결성이 깨졌다고 이야기합니다. 최종적으로 신뢰할 수 있는 데이터는 무결성을 지켜야 합니다.
2. 소프트웨어 테스트, 견고한 파이프라인을 E2E 테스트 환경 구축하기
1편에 소개 드린 주요 컴포넌트(Kafka Connect, Lambda 등)을 신뢰성 높게 유지하기 위해서 테스트 환경을 구성하였습니다. 각 컴포넌트의 주요 기능에 대해서 유닛 테스트, E2E 테스트를 작성하였지만 본 글에서는 E2E 테스트 위주로 설명드리겠습니다.
2.1. 테스트 환경 개요
FMS 파이프라인에서 테스트가 필요한 주요 컴포넌트는 Kafka Connect와 Lambda입니다. 다른 컴포넌트의 경우 SaaS나 클라우드 서비스를 사용했기에 어느 정도 신뢰성을 보장할 수 있지만 위 2개 컴포넌트는 요구사항에 맞춰 소프트웨어를 직접 개발했기 때문에 해당 컴포넌트의 신뢰성을 보장하는 테스트 작성이 필요했습니다.
소프트웨어 테스트 중에서도 E2E 테스트에 중점을 두어 환경을 구성하였습니다. 왜냐하면 PoC 단계에서 내부 구현이 변경될 확률이 높다는 점이 있으며 데이터 파이프라인을 구성하기 위한 명확한 요구사항이 있기 때문입니다.
E2E 테스트를 하기 위해서 필요한 외부 의존성은 Docker Compose로 구현하였고 별도의 Repository에서 관리하였습니다. 컴포넌트들의 E2E 테스트는 외부 의존성이 컨테이너 형태로 작동한 후 실행됩니다. 마지막으로 Github Action의 빌드, 배포 과정에서 E2E 테스트를 자동화하여 운영하였습니다. 더 자세한 내용은 아래에서 다루겠습니다.
2.2. Docker Compose를 통한 E2E 환경 구성
E2E 테스트를 하기 위해선 테스트할 애플리케이션뿐만 아니라 외부 의존성들도 함께 실행해야 합니다. 기본적으로 애플리케이션의 실행 및 운영은 도커 컨테이너 기반으로 수행되고 있었기에 테스트 환경 구성에 Docker Compose를 사용하였습니다. Docker Compose는 다중 컨테이너 서비스를 정의하고 실행하기 위해 많이 사용되는 도구입니다. 여러 도커 애플리케이션을 yaml 파일에서 정의/실행할 수 있어 E2E 테스트처럼 여러 의존성들을 직접 띄워야 할 때 유용하게 사용됩니다.
version: '3.8'
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.0
container_name: zookeeper
...
broker:
image: confluentinc/cp-kafka:6.2.0
container_name: broker
depends_on:
- zookeeper
...
localstack:
image: localstack/localstack
container_name: localstack
...
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
depends_on:
- broker
...
kafkacat:
image: confluentinc/cp-kafkacat:5.4.9
container_name: kafkacat
depends_on:
- broker
...
networks:
shared-network:
name: shared-network
driver: bridge
위는 현재 파이프라인의 컴포넌트들을 띄우기 위한 docker-compose.yaml 파일의 일부입니다.
Kafka 환경을 중심으로 모니터링 툴인 kafka-ui, AWS 서비스를 로컬 환경에서 실행할 수 있도록 Mocking 해주는 localstack 등이 있습니다. 이를 통해 로컬, CI 환경에서 각 컴포넌트들을 빠르게 띄우게 되며 호스트에서 Localhost를 통해서 접근하거나 각 컨테이너 서비스 사이에 통신이 가능해졌습니다.
또한 외부 Docker Compose로 실행되는 컨테이너와 통신할 수 있도록 하기 위해서 Network를 추가했습니다.
2.3. Git Submodule을 통한 컴포넌트 E2E 테스트
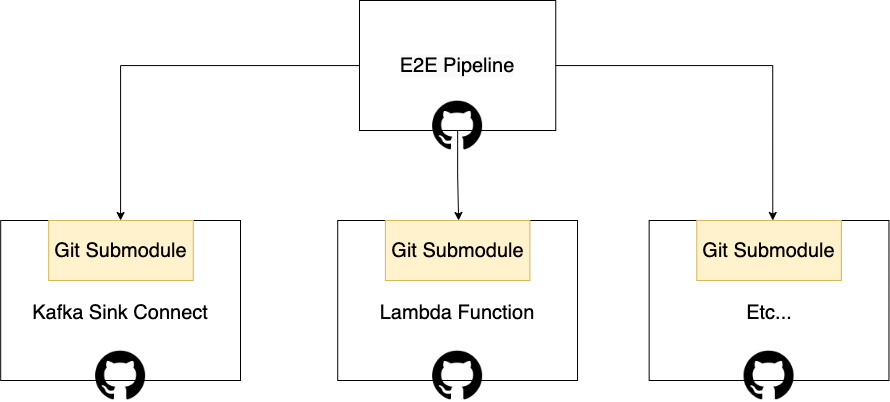
파이프라인을 띄우는 Docker Compose 코드는 독립적인 Git Repository에서 관리되고 있습니다. FMS 프로젝트에 여러 컴포넌트들을 테스트해야 하는 것뿐만 아니라 다른 프로젝트에서 사용할 수 있기 때문에 이를 분리하였습니다.
E2E 테스트 대상이 되는 Kafka Sink Connector, Lambda 같은 컴포넌트도 마찬가지로 독립적인 Git Repository로 관리되고 있습니다. 따라서 테스트할 Repository에서 파이프라인 구성 Repository를 연결할 수 있는 Git Submodule을 사용하였습니다.
예시로 Kafka Sink Connector의 E2E 테스트 폴더를 보면 아래와 같습니다. Git Submodule을 통해 Clone된 Repsoitory가 있는 걸 확인할 수 있습니다. 또한 tests/에 테스트 코드들이 들어있고 해당 테스트를 실행하는 docker-compose.e2e.yaml이 있습니다.
e2e
├── ...
├── docker-compose.e2e.yaml # 테스트할 대상들을 띄우기 위한 Docker Compose 파일
├── socar-fms-pipeline-docker # Git Submodule
│ ├── Makefile
│ ├── README.md
│ ├── docker-compose.yaml
│ └── scripts
└── tests
├── messages
├── test_ddb_sink_connector.sh
└── test_s3_sink_connector.sh
Kafka Sink Connector의 E2E 테스트를 실행하기 위해서 Kafka Connect 애플리케이션과 테스트 스크립트(Bash로 작성)을 실행하는 Docker Compose 파일이 필요합니다. 아래와 같이 Service에 작성하였으며 위에서 다룬 스트리밍 파이프라인 쪽 컨테이너들과 통신하기 위해 External Network로 연결하였습니다.
Docker-compose 코드
version: '3.8'
x-connect-test-configs: &connect-common
environment: &connect-common-env
...
services:
kafka-connect:
<<: *connect-common
image: ...
build:
context: ..
dockerfile: Dockerfile
container_name: kafka-connect
networks:
- network
- default
...
test-container:
image: confluentinc/cp-kafkacat:5.4.9
container_name: test-container
volumes:
- ./tests:/app/tests
command:
- /bin/bash
- -c
- |
...
for f in /app/tests/*.sh; do
echo "run $$f..." && bash $$f
done
networks:
- network
- default
...
networks:
network:
external:
name: shared-network
그리고 실제로 컴포넌트가 제대로 동작하는지 검증하기 위한 테스트 코드는 아래와 같습니다. REST API로 테스트할 Kafka Connector를 등록하고 Kafka Topic에 메시지를 보냈을 때 Sink에 제대로 적재가 되었는지 확인합니다. E2E 환경을 Docker Compose를 통해 전부 구축된 상황에서 Input을 넣고 Output을 확인하는 방식임을 알 수 있습니다.
Kafka Sink Connector E2E 테스트 코드
#!/bin/bash
set -eo pipefail
Red='\033[0;31m' # Red
Green='\033[0;32m' # Green
Yellow='\033[0;33m' # Yellow
kafkaConnectServer=kafka-connect:8083
targetTopic=s3-topic
deadletterTopic=deadletterqueue
echo "\n=============\n 0. Waiting for Kafka Connect to start listening on localhost \n============="
while [[ $(curl -s -o /dev/null -w %{http_code} $kafkaConnectServer) -ne 200 ]]; do
echo "waiting..." && sleep 5
done;
echo "\n=============\n 1. test s3 sink connector exists \n============="
command=$(curl -s $kafkaConnectServer/connector-plugins | grep "kr.socar.fms.connector.s3.S3SinkConnector" | wc -l)
if [[ ${command} == 0 ]]; then
echo "${Red}Fms kafka connect doesn't have S3SinkConnector"
exit 1
else
echo "${Green}passed"
fi
echo "\n=============\n 2. test s3 sink connector registered \n============="
command=$(echo '
{
"connector.class" : "kr.socar.fms.connector.s3.S3SinkConnector",
"topics": "'"$targetTopic"'",
...
}
' | curl -X PUT -d @- -s $kafkaConnectServer/connectors/s3-sink-connector/config --header "content-Type:application/json")
if [[ -z $(echo $command | jq -r ".error_code" ) ]]; then
echo "${Green}passed"
else
echo $command
exit 1
fi
echo "\n=============\n 3. test s3 objects exist after putting messages \n============="
kafkacat -P -b broker:29092 -t $targetTopic -l /app/tests/messages/s3-sink-test.message
sleep 3 # wait for a work of s3 connector
result=$(aws --endpoint-url http://localstack:4566 s3api list-objects --bucket test-bucket)
s3FileSize=$(echo $result | jq -r '.Contents | length')
if [[ $s3FileSize == 2 ]]; then
echo "${Green}passed"
else
echo "${Red}S3SinkConnector doesn't put messages to s3 (object size : $s3FileSize)"
exit 1
fi
echo "\n=============\n 4. test dlq after putting error messages \n============="
...
Kafka Sink Connector Docker Compose 환경에서 전부 실행했지만, Lambda 함수에 대한 E2E 테스트는 아래와 같이 Python + Pytest 환경에서 실행할 수 있습니다. 아래 코드는 Docker Compose의 일부 서비스(LocalStack S3)만 실행하여 E2E 테스트를 구현하였습니다.
Lambda E2E 테스트 코드
...
S3_BUCKET = "test-bucket"
S3_PREFIX = "raw"
def is_port_in_use(port: int) -> bool:
import socket
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
return s.connect_ex(("localhost", port)) == 0
...
@pytest.mark.skipif(
not is_port_in_use(4566), reason="localstack s3 (포트번호 4566)를 실행해야 합니다"
)
def test_save_to_s3_in_parquet_with_partitions(s3_source_json_key, s3_parquet_parser):
import awswrangler as wr
wr.config.s3_endpoint_url = "http://localhost:4566"
paritition_col = "partition"
s3_prefix = "formatted"
messages = [
{"object": "vehicle", "type": "kinematic", paritition_col: "0"},
{"object": "vehicle", "type": "status", paritition_col: "0"},
]
result = s3_parquet_parser.save_to_s3_in_parquet_with_partitions(
messages=messages,
partition_cols=[paritition_col],
s3_bucket=S3_BUCKET,
s3_prefix=s3_prefix,
)
assert result["paths"][0].startswith(f"s3://{S3_BUCKET}/{s3_prefix}")
...
2.4. Github Action을 통한 E2E 테스트 자동화
위에서 구성한 E2E 테스트는 사용자가 로컬에서 수행하는 것뿐만 아니라 CI(Continuous Integration) 단계에서도 수행됩니다.
쏘카에서는 CI 도구로 Github Action을 사용하고 있습니다. 아래는 Github Action에서 E2E Test 관련 워크플로 설정 파일입니다. 보통 Pull Request와 배포하기 전에 해당 워크플로가 실행됩니다.
E2E 테스트 관련 Github Action Worflow 코드
name: E2E Test On Kafka Connect
on:
pull_request:
...
jobs:
e2e-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
persist-credentials: false
- name: Checkout socar-data-pipeline-docker
uses: actions/checkout@v3
with:
repository: socar-inc/socar-data-pipeline-docker
ref: main
token: $
path: socar-data-pipeline-docker
- name: Run e2e pipleine
run: |
cd socar-data-pipeline-docker
docker-compose -p pipeline-docker --project-directory $PWD up -d --force-recreate
cd ..
- uses: actions/checkout@v3
with:
persist-credentials: false
clean: false # pipeline-docker를 유지하기 위해서 사용합니다.
- name: run e2e test
run: |
cd e2e
docker-compose --project-directory $PWD -f docker-compose.e2e.yaml up --abort-on-container-exit
Checkout Action을 사용하면 외부의 Github Repostiory를 손쉽게 Checkout 할 수 있습니다.
Github Action에서 하나의 Job은 하나의 격리된 환경에서 동작합니다. 따라서 E2E 환경을 구성하는 Repository로 Checkout 하여 Docker Compose로 실행한 후, 다시 원 Repository로 Checkout 하여 E2E 테스트를 수행합니다.
이때 주의할 점은 checkout 할 때 clean 속성을 false로 줘야 기존 볼륨을 유지할 수 있습니다 (기수행된 컨테이너에 마운트 된 볼륨이 갑자기 사라지는 이슈로 꽤 골치가 아팠습니다.)
3. 부하 테스트, 시뮬레이터를 활용한 실 데이터 기반의 테스트
3.1. 부하 테스트 계획
데이터 파이프라인을 구축하면서 주요하게 신경 써야 하는 부분 중 하나는 성능입니다. 위에서 언급한 것처럼 파이프라인의 각 지점은 SPoF가 되기 쉽기 때문에 높은 트래픽으로 인해 서비스가 중단되면 안 됩니다. 따라서 FMS 프로젝트에서 실 차량 데이터가 들어오기 전 부하 테스트를 계획하였습니다.
IoT Core에 메시지 전송을 시작으로 Kafka → Kafka Connect를 거쳐 DynamoDB, S3로 가는 E2E 부하 테스트를 준비하였습니다. 서비스에 주요하게 사용되는 메시지 위주로 시나리오를 작성하였습니다. 이때 FMS 프로젝트의 내년 목표 차량 대수를 기준으로 부하 기준을 설정하였습니다.
시뮬레이션을 통해 모니터링해야 하는 주요 대상은 직접 개발하고 관리하고 있는 Kafka Connect, DynamoDB, Lambda으로 정하였습니다. 각 컴포넌트마다 설정했던 주요 지표는 다음과 같습니다.
- Kafka Connect: Worker Pod의 시스템 리소스(CPU, Memory, Network IO 등)와 Kafka Sink Connector 별 Lag
- DynamoDB: 온디맨드 모드 시 WCU/RCU, 쓰로틀링 및 에러 발생 여부
- Lambda: 이벤트 처리 시간, 메모리 사용량
3.2. 실 데이터 기반의 메시지 시뮬레이터
데이터 파이프라인을 구축하는 도중에도 클라이언트(서비스 API 서버, Redshift 등)는 데이터 저장소에 접근해서 데이터를 조회할 수 있어야 개발 속도를 높일 수 있습니다. 이때 차량 단말기에서 실제로 데이터를 전송하는 것처럼 시뮬레이터를 구현하면 여러 팀에서 이를 사용해서 개발하는 과정에서 보틀넥이 발생하진 않을 것이라 판단했습니다.
실제로 메시지 시뮬레이터는 PoC 런칭 이전까지 프로젝트에 참여한 개발자들이 손쉽고 유연하게 시뮬레이션이 가능하도록 도움을 주었습니다.
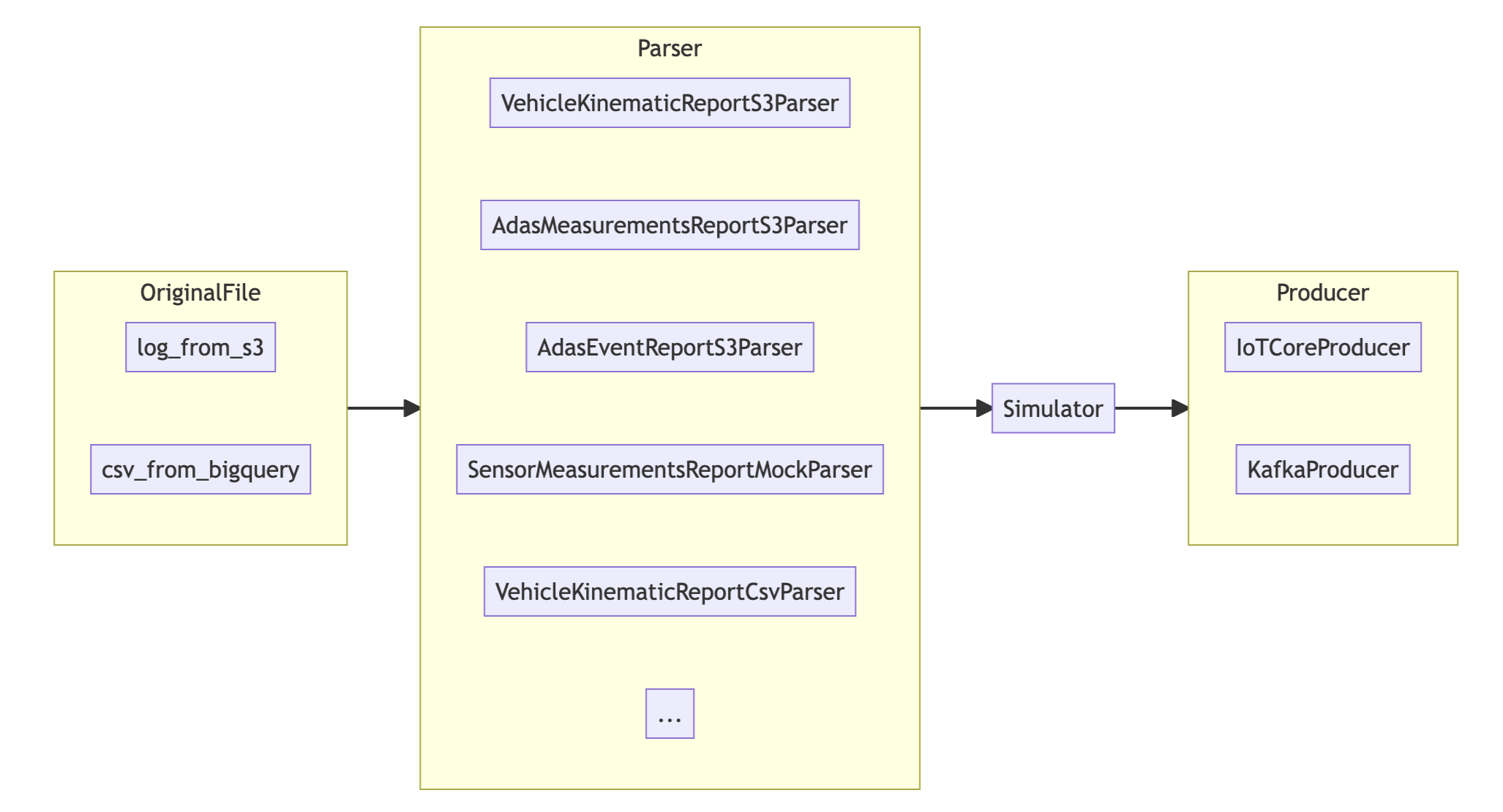
메시지 시뮬레이터는 외부 데이터(S3 Log, Bigquery) 혹은 직접 생성하는 방식으로 메시지를 생성합니다. FMS 프로젝트에서 정의한 프로토콜과 쏘카 차량에서 발생하는 데이터가 유사도가 높았기에 적재된 데이터를 잘 활용하면 손쉽게 메시지를 생성할 수 있습니다. 만일 없는 프로토콜의 경우 fake 데이터를 기반으로 메시지를 생성하였습니다.
FMS 서비스에서 여러 차량을 관제하는 것을 테스트하기 위해선 동시에 여러 차량이 차량 위치 데이터가 필요하며 차량 별로 일부 다른 데이터가 필요합니다. 이런 요구 사항들은 Simulator 객체를 통해 병렬 처리나 중간 변형 작업 등이 가능하도록 구현하였습니다.
마지막으로 메시지 브로커의 역할을 하는 IoT Core와 Kafka에 메시지를 전송할 수 있도록 Producer로 추상화하여 사용자가 원하는 환경으로 메시지를 쏠 수 있도록 하였습니다.
3.3. 부하 테스트 진행 및 결과
부하 테스트를 진행할 때는 각 시나리오 별 스크립트를 미리 작성하였습니다. 병렬로 메시지를 전송하는 스크립트들을 시간에 따라 각각 실행하였으며 주요 컴포넌트들을 모니터링하였습니다.
동시 차량 대수와 메시지 프로토콜 별로 컴포넌트의 주요 지표들을 측정하였으며 메시지 부하가 선형적으로 늘어났을 때 각 컴포넌트의 스케일 업/아웃이 정상 동작하는지도 확인하였습니다. 결과적으로 예상 비용과 우려되는 부분들도 함께 정리하여 리포트 형태로 공유하였습니다.
부하 테스트를 하면서 트러블 슈팅이 필요한 부분들도 있었습니다. S3 Sink Connector의 경우 내부적으로 버퍼를 둬서 메시지를 메모리에 저장하는데, 동시 메시지 개수가 늘어날수록 메모리가 빠르게 차서 Out Of Memory가 종종 발생하였습니다. 따라서 S3 Sink Connector의 속성을 튜닝하고 Worker Pod Memory와 Task의 heapOptions를 높여주었습니다. Lambda 또한 메모리 관련 이슈가 있어서 메모리를 높여주고, 내부 처리 로직을 개선하였습니다.
4. 데이터 퀄리티 테스트, 높은 데이터 퀄리티를 위한 환경 구축하기
이번 장에서는 데이터의 신뢰성을 높이기 위해서 했던 작업들에 대해 알아보도록 하겠습니다. 배치 분석 플랫폼을 통해 분석/집계된 데이터가 정말 유효한지, 차량 단말기에서 이상 데이터가 발생하지 않았는지 같은 검증 작업을 통해서 데이터의 신뢰성을 높이고자 하였습니다.
참고 : 현재 사내에서 진행되고 있는 프로젝트이기 때문에 구체적인 사항들은 의도적으로 생략하였습니다.
4.1. 검사할 대상 정의하기
FMS 프로젝트에서 데이터 퀄리티를 높게 유지하기 위해서 크게 아래와 같이 검사 유형들을 나눴습니다.
-
원본 데이터에 대한 이상 여부 검사
차량 단말기에서 전송되는 메시지의 이상 여부를 검사합니다. 예를 들어 GPS 상태 관련하여 에러가 발생하거나 특정 필드가 누락되는 등의 이상 현상을 모니터링합니다.
-
데이터 마트 테이블의 정합성 검사
Redshift를 통해 원본 데이터를 분석/집계된 데이터가 데이터 마트(Mysql)에 잘 적재되었는지 검사합니다. 쿼리 결과가 MySQL에 저장되는 과정에서 값의 변화가 없는지, 특정 시간이 지난 후 쿼리 해도 동일한 결과를 가지는지 등의 정합성 여부를 확인합니다.
-
데이터 마트 테이블의 무결성 검사
데이터 마트 테이블 별로 도메인에 맞는 칼럼 값을 가지고 있는지 확인합니다. 예를 들어 연료량이 0~100 사이에 존재하는지, 운행한 차량들은 전부 집계가 되었는지 같은 무결성 여부를 확인합니다. 도메인 전문가와 개발자가 분리되어 있는 경우도 많고 데이터 파이프라인의 특성상 여러 이해관계자들이 관여하기 때문에 각 이해관계자 들이 모여 주기적으로 데이터 신뢰성을 높이기 위한 회의를 진행하였습니다. 아래와 같이 템플릿을 통해 신뢰성을 검증하는 대상들을 문서화하고 함께 논의하였습니다.
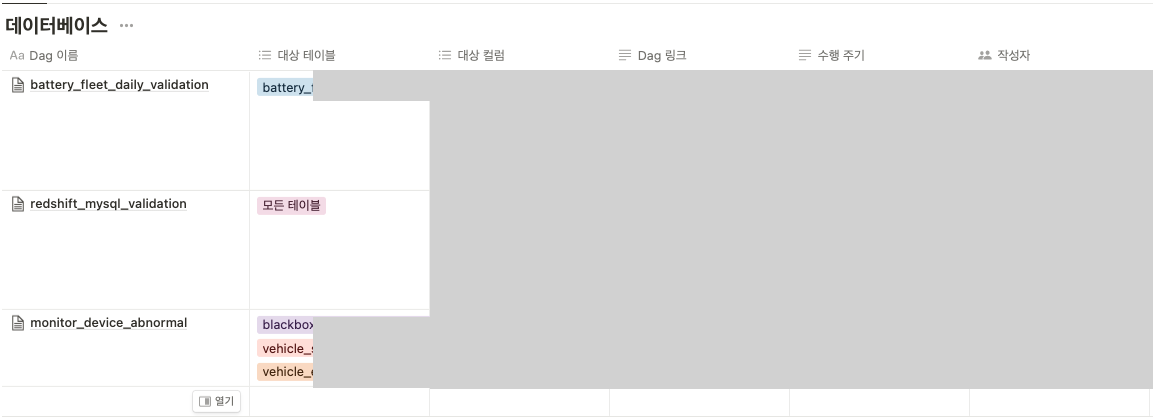 검증 대상이 되는 마트 테이블을 정의하여 기록하였습니다.
…
검증 대상이 되는 마트 테이블을 정의하여 기록하였습니다.
…
4.2. 데이터 퀄리티 검사 파이프라인 소개
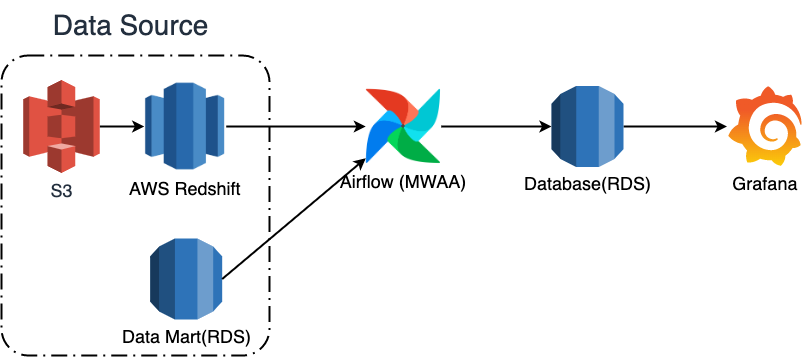 데이터 퀄리티 검사를 구현하기 위해서 아래와 같은 기술들을 선택하였습니다.
데이터 퀄리티 검사를 구현하기 위해서 아래와 같은 기술들을 선택하였습니다.
- 데이터 무결성 검사 : SQLColumnCheckOperator
- 데이터 정합성 검사 : Pandas (Redshift, Mysql Connection)
- 검사 스케줄링 : Airflow
- 데이터베이스 : RDS(MySQL)
- 모니터링 : Grafana
저희는 데이터 무결성을 검사하기 위해 선택지로 서드파티 툴인 great_expections나 dbt(+ dbt expectations)이 있고 Airflow에서 간단하게 사용할 수 있는 SQL Operator 등을 고려했습니다. 결과적으로 가볍게 사용할 수 있는 Airflow SQL Operator를 선택하였습니다.
데이터 정합성 검사는 SQL의 Except 구문을 활용하여 데이터 마트(MySQL)와 Redshift 쿼리 결과를 비교하였습니다. 그리고 쿼리 실행 및 결과 처리는 Pandas를 사용하였습니다.
검사는 크게 아래와 같은 순서로 진행됩니다.
-
정합성/무결성 검사는 매일 새벽에 수행되며 무결성 검사는 전날 생성된 마트 데이터, 정합성 검사는 이틀 전 데이터를 기준으로 합니다.
-
수행된 검사 결과(성공, 실패)는 데이터베이스(RDS)에 저장됩니다.
-
Grafana를 통해 데이터베이스에 저장된 결과를 대시보드에서 확인하며,
Grafana Alert를 통해 검사가 실패한 경우 슬랙으로 메시지를 전송합니다
4.3. Monitoring Operator 구현
데이터 퀄리티 검사를 진행한 후 검사 결과를 데이터베이스에 저장하는 과정이 필요합니다. 무결성 검사 도구인 SQLColumnCheckOperator의 경우 검사 실패 시 Exception을 발생시키지만 데이터베이스에 결과를 저장하는 기능은 존재하지 않았습니다. 따라서 SQLColumnCheckOperator에 새로운 기능을 적용하기 위해서 상속(Inheritance)이나 구성(Composition) 방식을 통해서 새로운 Operator를 생성하였습니다.
따라서 아래와 같이 MonitoringValidationOperator를 구현하였습니다.
MonitoringValidationOperator 코드
class MonitoringValidationOperator(BaseOperator):
"""
정합성/무결성 검사 결과를 Database에 저장하는 Operator입니다
:param operator_constructor: 검사를 진행하는 Operator를 생성 함수 형태로 입력합니다 (Airflow DAG에서 Operator 생성 감지 이슈로 인해 함수 형태로 작성)
:param conn_id: Database에 연결할 connection id를 입력합니다
:param table: 검사 결과를 저장할 table을 "{database}.{table}" 형식으로 입력합니다
:param database: 검사 결과를 저장할 database를 입력합니다
:param target_table: 검사를 진행한 table을 입력합니다 (data_mart, redshift 등)
"""
target_fields = ["result", "target_table", "result_content", "dag_id", "task_id", "owner", "execution_date"]
def __init__(
self,
operator_constructor: Callable[[], BaseOperator],
conn_id: str,
table: str,
target_table: str,
database: Optional[str] = None,
*args,
**kwargs,
) -> None:
super(MonitoringValidationOperator, self).__init__(*args, **kwargs)
...
@cached_property
def _hook(self):
...
def get_db_hook(self) -> DbApiHook:
...
def execute(self, context: any):
operator = self.operator_constructor()
self._render_operator_template(operator, context)
try:
self.log.info("Execute a wrapped operator")
operator.execute(context)
self._load_result_in_table(...)
except AirflowFailException as e: # Validation 과정에서 실패한 경우 AirflowFailException을 발생한다
self.log.error("Exception Occurred during validation", e)
self._load_result_in_table(...)
raise e
except Exception as e:
self.log.error("Exception Occurred", e)
raise e
def _load_result_in_table(self, records: List[Tuple], target_fields: List[str]):
...
def _render_operator_template(self, operator: BaseOperator, context: Dict) -> None:
...
SQLColumnCheckOperator가 검증에 실패하면 AirflowFailExcpetion을 발생시키기 때문에 공통 인터페이스로 다른 검사 로직에서 실패 시 AirflowFailException을 발생시키도록 통일하였습니다. 그리고 Operator의 execute 메서드에서 try/catch 형태로 이를 감지하여 검사 결과를 저장하도록 구현하였습니다.
실제로 아래와 같은 구조로 데이터 퀄리티 검사가 진행되고 있으며 매일 결과가 적재되고 있습니다.
validate_mysql = MonitoringValidationOperator(
task_id="monitoring_operator",
conn_id="mysql_write_conn",
database="fms_monitoring",
table="validation_result",
target_table="fms_data_mart.battery_fleet_daily",
operator_constructor=lambda: SQLColumnCheckOperator(
partition_clause="std_date = '{{ execution_date.in_timezone('Asia/Seoul').strftime('%Y-%m-%d') }}'",
column_mapping={
"fleet_intg_id": {
"max": {"leq_to": 1}
}
}
)
)
4.4. 검사 결과 모니터링
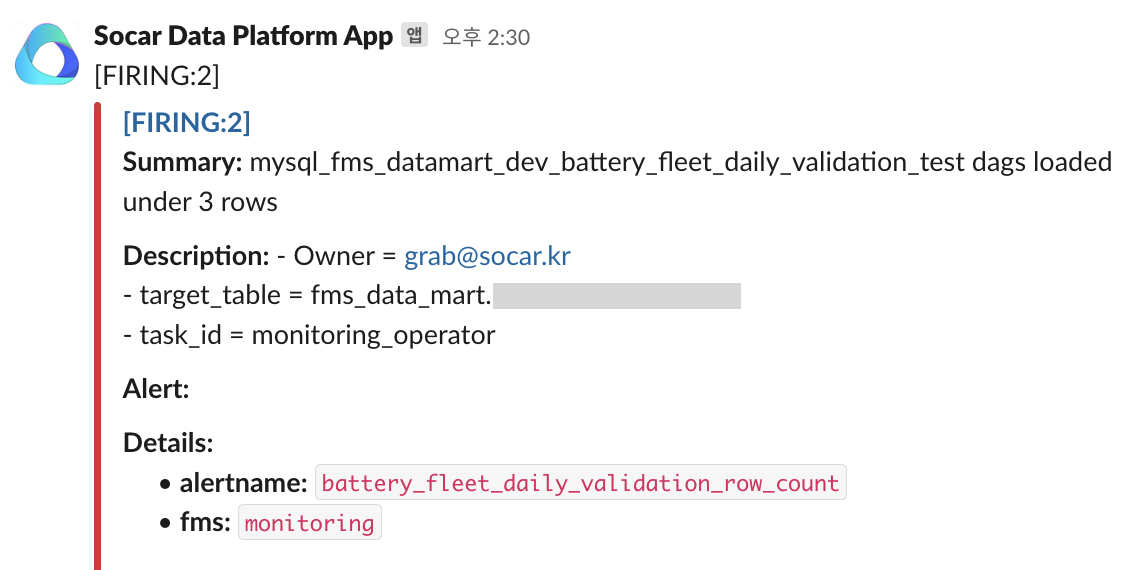
데이터베이스에 적재된 테스트 결과는 Grafana를 통해 시각화하였습니다. 각 테스트하는 DAG 별로 날짜별 테스트 수행 개수를 통해 데이터 퀄리티 테스트가 잘 수행되는지 확인 가능하며, 실패한 테스트의 개수를 통해 실패한 테스트를 확인할 수 있습니다.
만약 실패한 테스트가 발견되는 경우 아래와 같이 슬랙 알림을 통해 확인할 수 있도록 하였습니다.
5. 마무리
안정적으로 데이터를 사용자에게 제공하기 위해서 많은 노력이 필요합니다. 짧은 PoC 개발 기간에 꼭 필요하다고 생각이 들었던 데이터 파이프라인의 테스트와 데이터 품질 검사를 먼저 개발하였습니다. 앞으로 더 체계적으로 테스트 환경을 구축하고 데이터 퀄리티를 높이는 동시에 가시화할 수 있도록 노력하려고 합니다.
파이프라인을 개발하면서 동시에 소프트웨어의 안정성과 데이터 퀄리티를 함께 챙겨야 하는 과정은 힘들었지만 정말 배운 점들이 많았습니다. 안정적인 데이터 파이프라인 구축을 위해 함께 힘써주고 계신 피글렛, 누즈, 루디, 삐약, 파스모에게 감사의 말을 전합니다.