 그랩
그랩안녕하세요. 데이터 플랫폼 팀의 그랩입니다.
데이터 플랫폼팀은 “쏘카 내부의 데이터 이용자가 비즈니스에 임팩트를 낼 수 있도록 소프트웨어 엔지니어링에 기반하여 문제를 해결합니다”라는 미션을 기반으로 인프라, 데이터 파이프라인 개발, 운영, 모니터링, 데이터 애플리케이션 개발, MLOps 등의 업무를 맡고 있습니다. 팀 구성원들은 모두가 소프트웨어 엔지니어라는 사명감을 가지고 개발뿐만 아니라 Ops에 대한 이해와 책임감을 가지고 업무에 임하고 있습니다.
본 글에서는 데이터 플랫폼 팀에서 운영하는 Airflow에 대해 소개하려고 합니다. 데이터 엔지니어 위주로 사용하던 초기와 달리 현재는 데이터 비즈니스 본부 구성원 모두가 Airflow를 활용하여 직접 파이프라인을 구축할 수 있습니다. 이런 변화에 따른 문제들과 어떻게 해결하였는지 풀어보도록 하겠습니다.
다음과 같은 분들이 읽으면 좋습니다.
- 운영하고 있는 Airflow를 고도화하고 싶은 소프트웨어 엔지니어
- Kubernetes 환경에서 Airflow를 운영하고 있는 소프트웨어 엔지니어
- 사용자가 다양한 Airflow의 개발 환경을 개선하고 싶은 소프트웨어 엔지니어
- 데이터 플랫폼에 관심이 있는 소프트웨어 엔지니어
목차는 아래와 같습니다.
Airflow에 대한 히스토리가 길고 다루는 내용들이 많다 보니 모든 과정을 상세하게 적지는 못했습니다. 댓글로 질문 편하게 남겨주시면 답변드리겠습니다.
1. 쏘카의 Airflow 현황과 문제점
데이터 파이프라인을 구축할 때 꼭 빠지지 않는 구성요소가 있습니다. 바로 Airflow입니다. Airflow는 Airbnb에서 개발한 워크플로우 관리 오픈소스로 현재 많은 기업에서 데이터 파이프라인을 자동화할 때 사용하는 툴입니다.
1.1. Airflow in Socar
쏘카에서는 데이터 분석가, 데이터 사이언티스트, AI 엔지니어 등 다양한 사용자들이 Airflow DAG을 통하여 파이프라인을 직접 구축할 수 있습니다. 대신 다양한 사용자가 Airflow를 불편함 없이 이용하기 위해서 관리자가 Airflow의 사용 범주와 개발 방식을 잘 정의하는 것이 중요합니다.
쏘카에서는 데이터 통합 저장소(데이터 레이크, 웨어하우스)로 BigQuery를 사용하고 있습니다.
기본적으로 외부 데이터 소스(Open API, RDBMS, S3 등)와 BigQuery 원본 데이터 셋을 BigQuery로 가공/적재하는 작업에 Airflow를 사용할 것을 권장하고 있습니다.
또한 DAG는 Data Lake, Data Mart, Monitoring, Crawling 등 각 용도에 맞게 분류하여 관리되고 있습니다.
(단순 스케줄링을 필요로 하는 작업은 Airflow의 사용을 지양하고 K8s(Kubernetes) Cronjob이나 Github Action 등을 활용하는 것을 권장하고 있습니다)
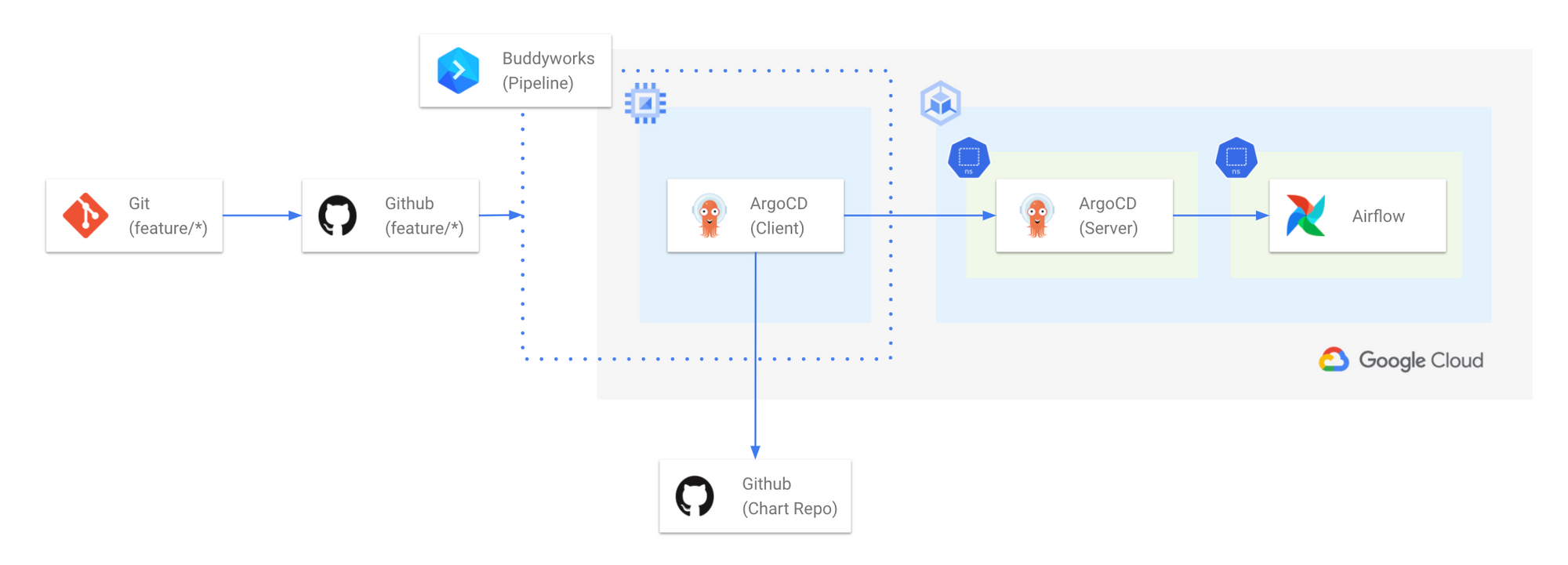 Airflow on Kubernetes Workflow
Airflow on Kubernetes Workflow
쏘카의 데이터 플랫폼/애플리케이션들은 대부분 GKE(Google Kubernetes Engine) 환경에서 동작하고 있습니다. 개발 편의성을 위해서 운영/개발 환경 별로 클러스터를 분리하여 사용하고 있으며, Airflow도 운영 환경과 개발 환경이 분리되어 있습니다. Airflow Github Repository의 Branch 이름이 특정 조건을 만족하면 CI/CD 파이프라인을 거쳐서 개발 클러스터에 Branch 별로 Airflow 서비스가 독립적으로 생성됩니다.
과거 Airflow 사용자는 DAG을 생성/변경하기 위해서 기본적으로 feature Branch를 생성하여 변경 커밋을 원격 Branch에 푸시 하였습니다. 그러면 Git Sync를 통해 Airflow에 DAG이 동기화되어 테스트가 가능했습니다.
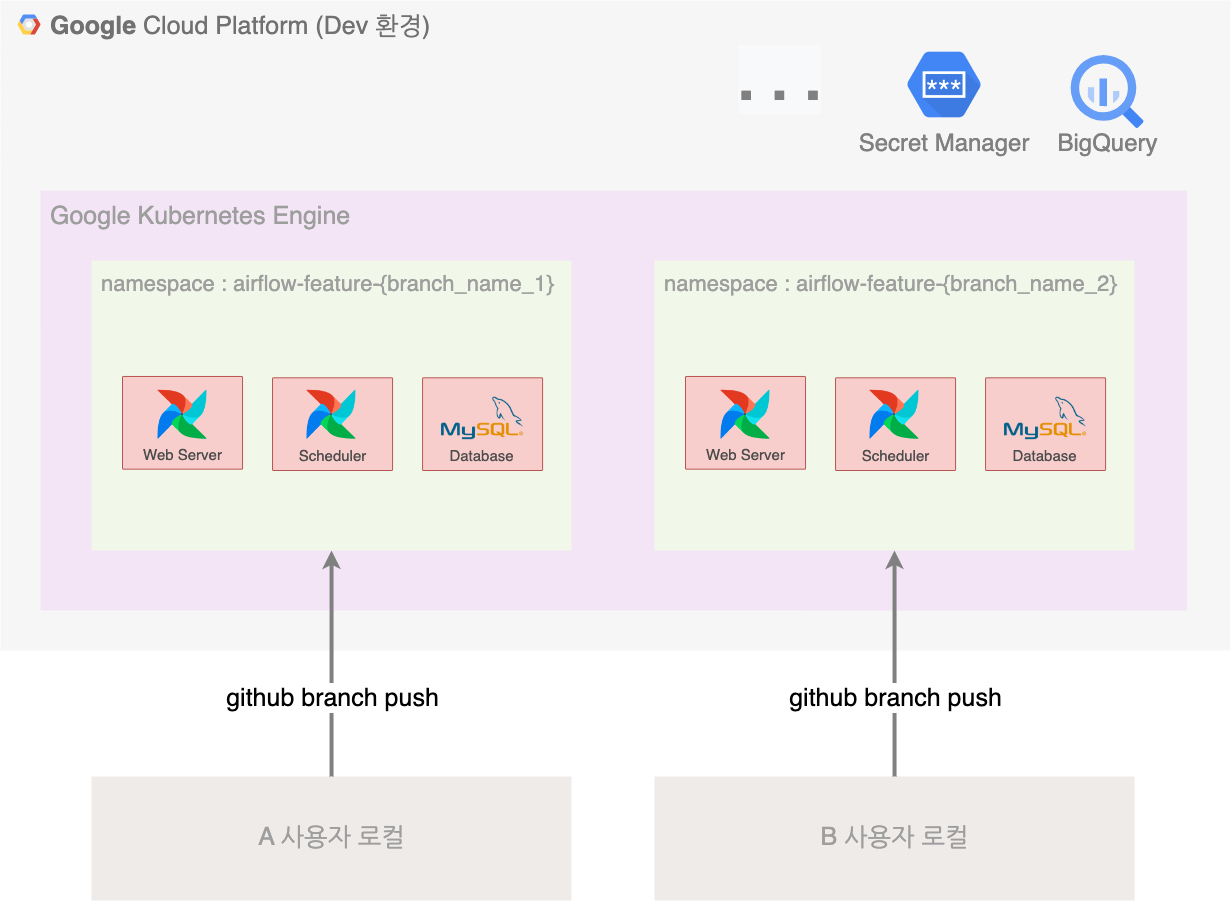 Airflow 기존 개발 환경
Airflow 기존 개발 환경
쏘카의 Airflow On K8s 운영에 대해 더 궁금하시다면 쏘카 데이터 그룹 - Airflow와 함께한 데이터 환경 구축기를 읽어보세요.
1.2. 문제점
사용자가 독립된 Airflow 개발 환경을 쓸 수 있는 것은 큰 장점입니다. 운영과 분리된 환경에서 테스트가 가능하였으며 Github을 SoT(Source of Truth)로 삼아 코드 퀄리티 관리가 용이하였습니다. 하지만 기존 방식의 Airflow는 아래와 같은 문제점들이 있었습니다.
- 개발 환경의 Airflow의 에러 발생 및 관리자/컴퓨팅 리소스 낭비
- 많은 사용자들이 사용하기엔 불친절한 개발 환경, 긴 피드백 루프
- Airflow 1 버전의 고질적인 문제들
- 코드 보안에 취약하고, 사용자 개인에 대한 권한 체계 부족
- 체계적이지 않은 오류 대응 프로세스 및 모니터링 환경
문제점 1 - 개발 환경의 Airflow의 에러 발생 및 관리자/컴퓨팅 리소스 낭비
개발 환경의 Airflow는 Github Branch를 기반으로 생애 주기가 결정됩니다. 따라서 사용자가 작업을 완료하고 Branch를 삭제하면 개발 환경의 Airflow는 함께 내려가게 됩니다. 그러나 사용자는 Branch를 만들고 작업하다가 중간에 다른 작업을 하는 경우들이 많았고, 이에 Airflow는 계속 유휴 상태로 남아있어 K8s Node의 자원을 차지하였습니다.
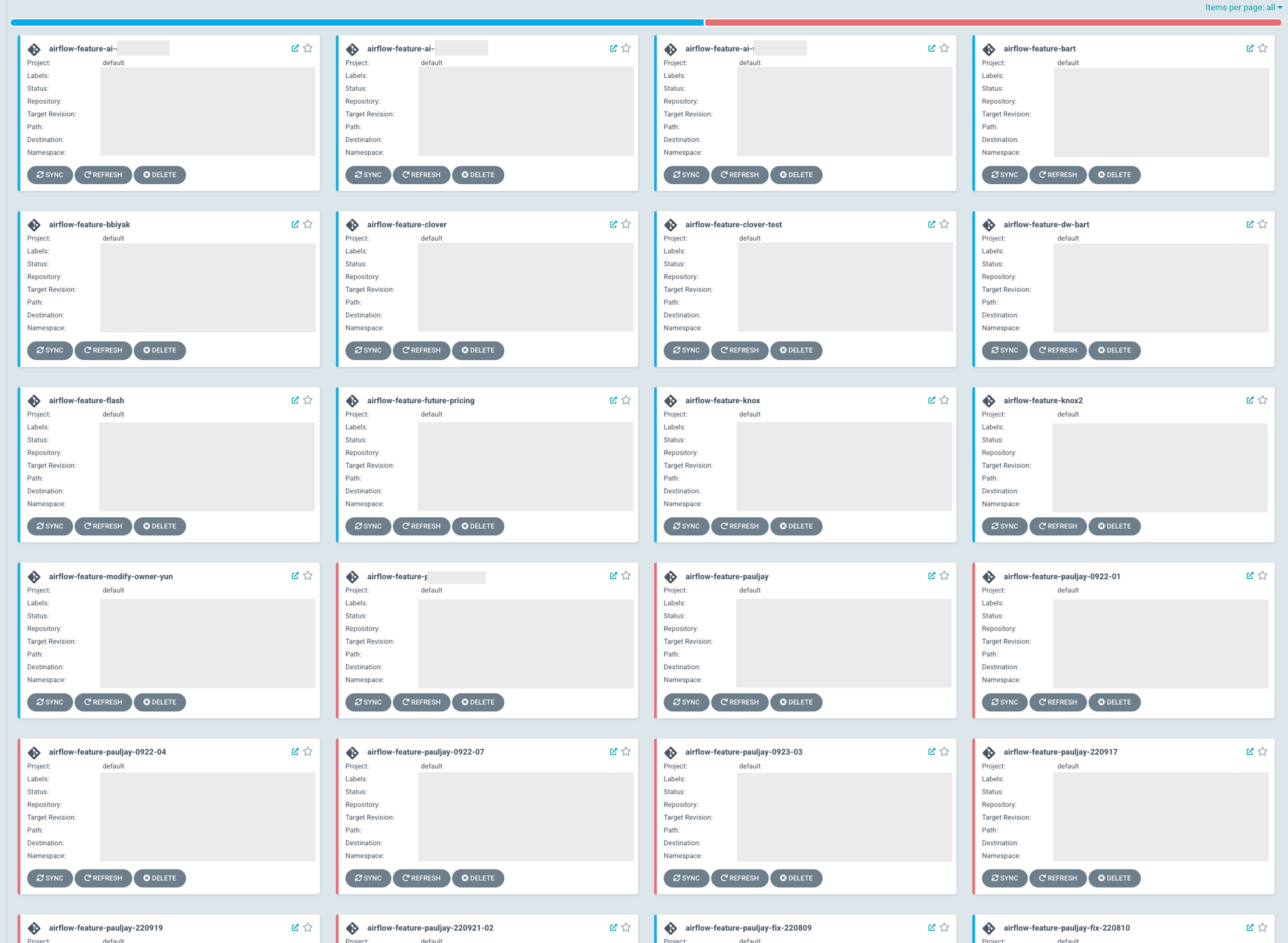 다수의 사용자가 개발 환경에서 만든 Airflow가 남아있는 모습
다수의 사용자가 개발 환경에서 만든 Airflow가 남아있는 모습
더불어 당시 Airflow를 K8s에 배포하기 위해 사용한 Helm Chart(Community 버전)도 간헐적으로 원인 모를 에러가 발생하였습니다. 이에 따라 관리자는 Airflow 에러를 수정하고 사용자와 커뮤니케이션 하는 과정에서 피로도가 높았습니다.
문제점 2 - 많은 사용자들이 사용하기엔 불친절한 개발 환경, 긴 피드백 루프
개발 환경의 Airflow는 Git Sync를 통해 Github Repository의 코드를 동기화합니다. 사용자가 DAG의 변경 사항을 개발 클러스터에 반영하기 위해 매번 Commit를 해야 하는 것도 불편했으며 운영하는 DAG의 개수들이 많다 보니 Push 때마다 동기화 시간이 1분 이상 걸리기도 했습니다. 이런 상황에서 사용자가 코드를 작성하면서 계속해서 동작 확인을 하기 위해선 Commit당 매번 1분 이상 기다려야 했습니다. 이는 피드백 루프와 개발 시간이 길어진다는 것을 의미합니다.
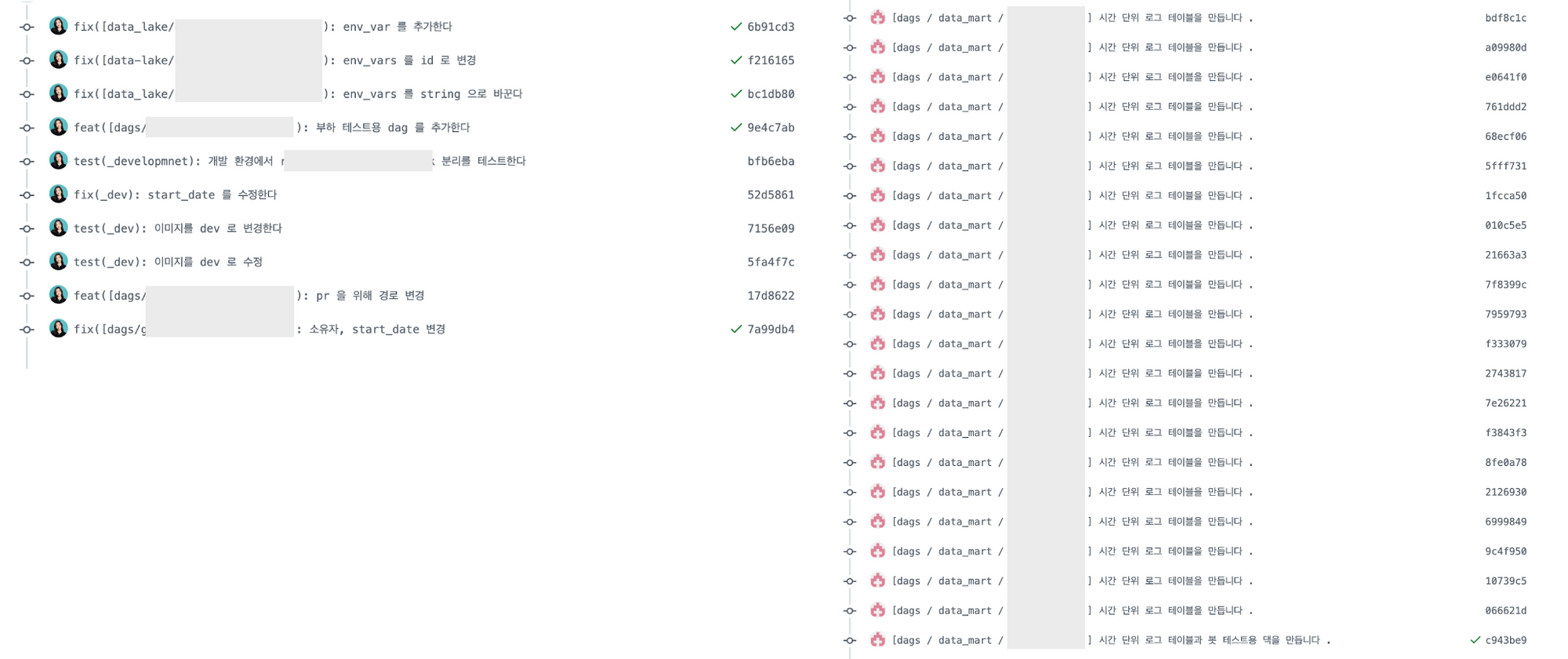 Airflow 커밋 히스토리가 불필요하게 길어지기도 합니다.
Airflow 커밋 히스토리가 불필요하게 길어지기도 합니다.
또한 개인 노트북 환경에서 코드를 작성하기 위해선 Airflow 관련 구성 의존성들을 설치해야 하고 기본 개발 환경을 설정해야 합니다. 하지만 이에 관한 가이드 문서들이 부족하였으며 일부 Mac OS 버전에서는 의존성이 제대로 설치되지 않는 문제들도 있었습니다.
문제점 3 - Airflow 1 버전의 고질적인 문제들
기존 1 버전 대 Airflow는 DAG 개수가 늘어나면 DAG Parsing 시간이 오래 걸리는 치명적인 문제가 있었습니다. 그때 당시 쏘카에서 운영하는 DAG은 수백 개였고 점점 DAG이 늘어날 때마다 Task Instance들의 스케줄링이 점점 밀리게 되었습니다. 그리고 DAG Parsing 프로세스가 백그라운드에서 동작하고 있다 보니 웹에 접근했을 때 속도가 느렸습니다. 그때 당시 K8s Node의 자원을 스케일 업해봤지만 크게 개선되는 부분은 없었고 단순 스케일 업보다는 조금 더 근본적인 해결책이 필요했습니다.
문제점 4 - 코드 보안에 취약하고, 사용자 개인에 대한 권한 체계 부족
다수의 사용자들이 Airflow를 사용하면서 Api Key나 Secret 정보들을 그대로 하드코딩하는 경우들이 있었습니다. 특히 Airflow 사용 목적 상 외부 데이터 소스/저장소와 통신해야 하는 경우들이 많아 위 문제들이 빈번하게 발생했습니다.
또한 팀 별로 공용 계정을 사용했기 때문에 간혹 Connection, Variable이 지워지거나 실행되던 Task가 갑자기 종료되는 문제들이 발생했었으며, 정확한 히스토리 추적이 힘들어지는 문제가 있었습니다.
문제점 5 - 체계적이지 않은 오류 대응 프로세스 및 모니터링 환경
기존에는 Airflow DAG가 실패했을 때 알림을 보내는 슬랙 채널이 존재했습니다. 보통 메시지가 오면 관리자 혹은 히스토리를 잘 알고 있는 사용자가 해당 DAG의 책임자에게 라우팅을 해주는 방식이었습니다. 하지만 담당자를 제대로 파악하고 대응하기까지 시간이 걸리는 경우들이 있었고, 담당자를 제때 파악하지 못하는 경우들도 있었습니다.
또한 Airflow가 동작하는 K8s 환경에 대한 체계적인 모니터링 환경을 구축하고 있지 못했습니다.
1.3. 해결 방안 모색
Airflow를 운영하면서 드러난 문제들을 개선하기 위해 아래와 같은 해결 방안들을 세웠습니다. 구체적인 내용들은 밑에서 더 상세하게 풀어내도록 하겠습니다.
| 문제점 | 해결 방안 |
|---|---|
| 개발 환경의 Airflow의 에러 발생 및 리소스 낭비 불친절한 개발 환경, 긴 피드백 루프 |
개발 환경 개선 및 개발 주기 단축하기 |
| Airflow 1 버전의 고질적인 문제들 | Airflow 2 버전 마이그레이션 및 스케일 업 |
| 코드 보안에 취약하고, 사용자 개인에 대한 권한 체계 부족 | 보안 강화 및 RBAC 적용 |
| 체계적이지 않은 오류 대응 프로세스 및 모니터링 환경 | 체계적인 모니터링 환경 구축 |
2. 개발 환경 개선 및 개발 주기 단축하기
2.1. 목적
사용자들이 빠르게 개발할 수 있도록 지원하고 DAG 개발 이외의 관심사를 최대한 분리할 수 있도록 합니다.
데이터 플랫폼을 운영하기 위해선 시스템을 개발/유지 보수하는 것을 넘어서 고객을 이해하고 플랫폼을 지속해서 개선해나가는 것이 중요합니다. 특히 쏘카의 데이터 분석가, 데이터 사이언티스트 등 프로그래밍에 익숙하지 않은 팀원들에게 Airflow 사용의 러닝 커브를 낮춰주는 것이 중요합니다.
또한 Airflow를 사용하기 위해서 사용자가 Airflow 구성요소와 인프라 등을 전부 이해할 필요는 없습니다. 사용자가 DAG을 개발하는 것에 집중할 수 있도록 나머지는 잘 추상화하여 관심사를 분리하여야 합니다.
사용자의 개발 및 피드백 주기를 단축합니다.
소프트웨어는 지속적인 개선을 위해서 피드백 루프를 짧게 가져가는 것이 중요합니다. 일반적으로 로컬 환경에서 Airflow DAG 개발/수행에 대한 피드백 시간이 가장 빠릅니다(LocalExecutor, SequentialExecutor). 다만 로컬에서 개발하기 위해선 외부 환경에 대한 Mocking과 인증에 대한 고민을 함께 해야 합니다.
2.2. 로컬 개발 환경 구축
기존 Airflow 개발 환경은 Airflow의 생애 주기가 Branch에 의존적이기 때문에 Branch가 남아있다면 자원을 유휴상태로 낭비하는 경우들이 많았습니다. 또한 Branch가 삭제되었을 때 CI/CD 파이프라인의 이슈로 Airflow가 제대로 삭제되지 않는 문제들이 있었습니다. 그리고 K8s + Git Sync 조합은 DAG이 많을수록 동기화 속도가 느려져서 피드백 루프와 개발 속도의 저하를 유발했습니다.
그래서 개발 환경을 노트북(로컬 환경)에서 쉽게 구축할 수 있다면 생산성이 더 높아질 것이라고 판단하였습니다. 기본적으로 Docker는 OS에 크게 상관없이 표준을 따르기 때문에 로컬 환경에 Docker Compose를 띄워서 개발 환경을 개선하는 작업을 진행했습니다.
결과적으로 로컬 환경을 도입하여서 아래와 같이 개발 생산성을 높이고 인적/클라우드 비용의 절감을 이끌어냈습니다.
- Airflow 서버를 띄우는 시간 단축 : 5분 -> 1분
- 개발 피드백 루프 시간 단축 : 1분(Commit -> Sync) -> 5초
- 개발 클러스터에서 유휴 Airflow들이 Node를 점유하였던 문제 해결 : 2개 이상의 VM 절약
- Docker라는 표준 환경을 통해 Airflow 서버의 불안정성을 낮추고 관리 비용을 줄임
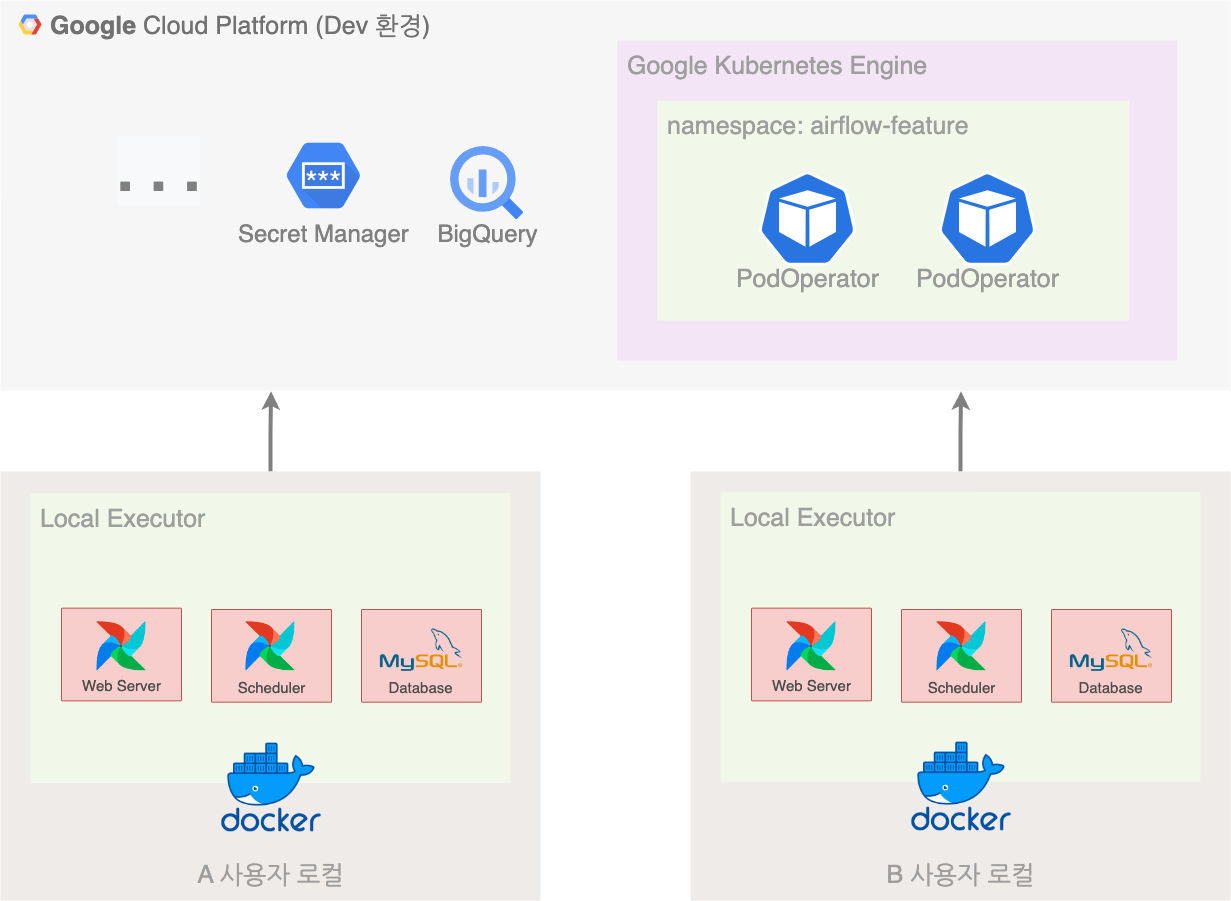 Airflow 로컬 개발 환경
Airflow 로컬 개발 환경
Docker Compose로 각 컴포넌트 띄우기
docker-compose 로컬 환경 구축을 진행할 때 기본 Airflow 컴포넌트들은 각각 Image로 나눠서 띄웠습니다.
기본적으로 공식 Airflow의 docker-compose 파일을 참고하였고, 추가로 저희 상황에 맞게 의존성을 추가하였습니다.
version: "3.8"
x-airflow-common: &airflow-common
image: apache/airflow:2.3.2
environment: &airflow-common-env
EXECUTOR: Local # LocalExecutor로 실행합니다
_PIP_ADDITIONAL_REQUIREMENTS: ... # 추가 의존성을 설치합니다
GOOGLE_APPLICATION_CREDENTIALS: ... # 사용자 인증 파일(GCP Service Account) 경로를 넣어줍니다
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: 5 # DAG 코드의 변화를 빠르게 감지하여 metadb에 반영한다.
...
services:
init: # Airflow user를 생성하고 .airflowignore를 적용하는 등의 script를 실행합니다
<<: *airflow-common
entrypoint: /bin/bash
command: /opt/airflow/scripts/entrypoint.sh
environment:
<<: *airflow-common-env
_AIRFLOW_DB_UPGRADE: "true"
_AIRFLOW_WWW_USER_CREATE: "true"
_AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD:-airflow}
TARGET_DIR: _development
...
webserver:
<<: *airflow-common
...
scheduler:
<<: *airflow-common
...
mysql:
<<: *airflow-common
...
GCP Service Account를 통합 인증 수단으로 활용하기
기본적으로 Airflow는 GCP 리소스(BigQuery, Secret Manager, GKE 등)에 접근하는 경우가 많기에, 로컬에서 개발할 때 권한 관리가 필요합니다. 이런 인증 문제는 개인 별 Service Account 발급을 통해 해결하였습니다.
현재 GCP의 전체적 운영은 데이터 플랫폼 팀에서 담당하고 있습니다. GCP IAM은 팀 단위의 역할에 맞게 Custom Role을 만들어 관리하고 있으며, 사용자별 Service Account는 해당 팀의 Role에 바인딩 되어 있습니다. 사용자가 Airflow 개발을 필요로 할 때 데이터 플랫폼 팀에서 Service Account 발급을 해줍니다.
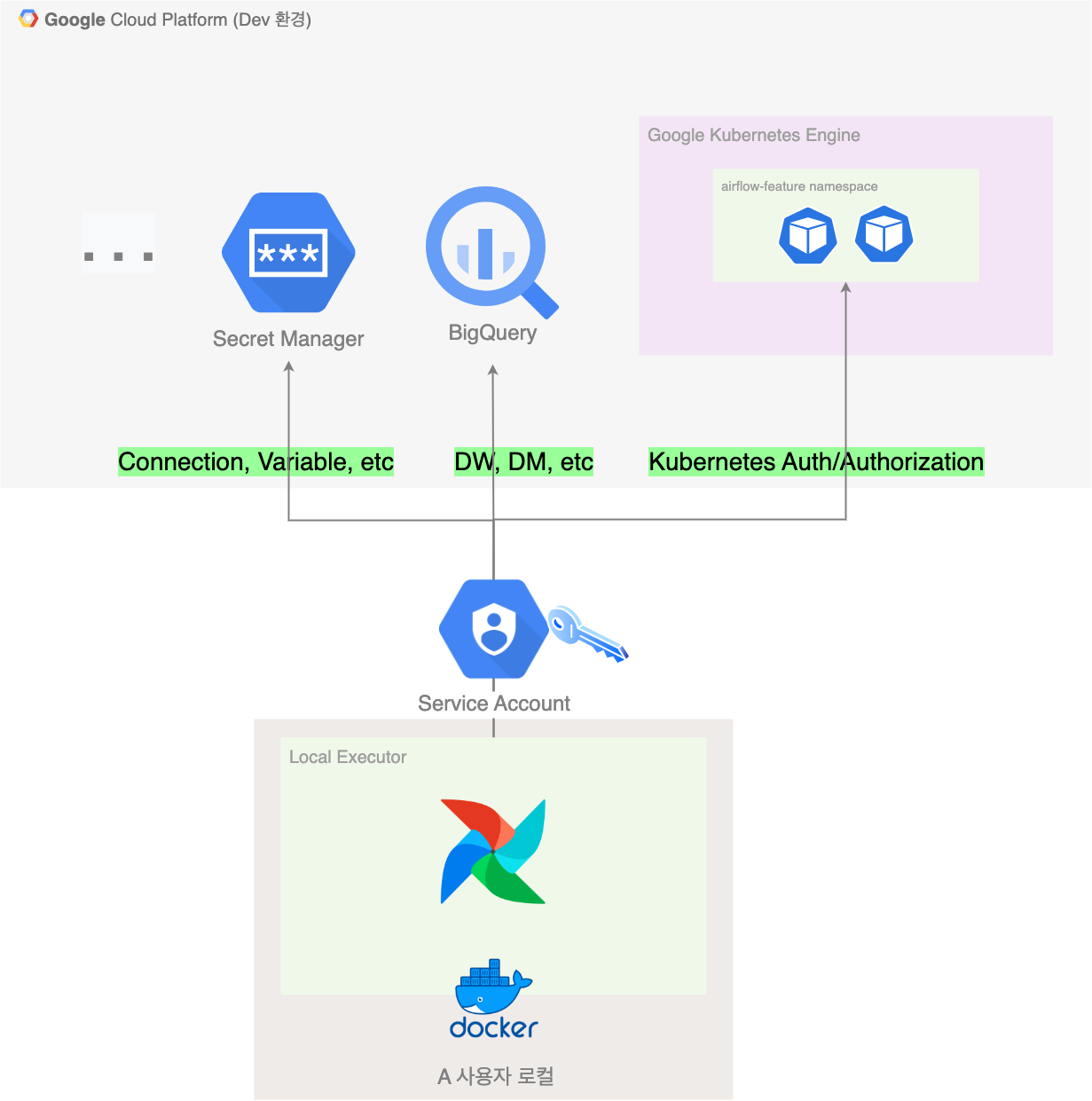 Service Account 활용 구조
Service Account 활용 구조
이를 잘 활용하여 Secret(Connection, Variable 등)도 GCP Secret Manager로 옮긴 후 Service Account로 인증하여 로컬에 보안 정보를 전부 제외할 수 있었습니다.
KubernetesPodOperator를 테스트할 수 있는 환경 구축
현재 쏘카의 Airflow는 KubernetesExecutor를 사용하고 있습니다. KubernetesExecutor의 장점 중 하나는 KubernetesPodOperator를 통해 사용자가 직접 정의한 컨테이너 이미지를 Pod 형태로 독립적 수행이 가능하다는 점입니다.
사용자가 정의한 이미지에는 의존성을 별도로 설치할 수 있고 Airflow DAG 레포에 종속되지 않기에, 저희 팀에서도 자주 활용하고 있습니다. (KubernetesExecutor에 대해서 더 궁금하다면 여기를 참고해 주세요)
KubernetesExecutor에서 실행하는 일반적인 Operator(PythonOperator, BigqueryOperator, etc)는 Pod 형태로 수행되며, 이는 로컬 환경인 LocalExecutor 수행 방식(Scheduler Process에서 Task를 실행)으로 대체해도 수행이 가능합니다.
하지만 KubernetesPodOperator의 경우 컨테이너 이미지를 Pod에서 수행하다 보니 LocalExecutor로 해당 태스크를 수행하는 것이 불가능합니다. 현재 쏘카에서 KubernetesPodOperator를 많이 사용하고 있는데, 해당 기능 테스트를 제한한다면 사용자 경험을 해칠 것입니다.
처음에 이 문제를 해결하기 위해서 컨테이너 형태로 태스크를 수행할 수 있는 DockerOperator를 활용해 보면 어떨까 생각하였습니다. 로컬 환경에서는 DockerOperator, 운영 환경에서는 KubernetesPodOperator를 수행하는 팩토리 형태의 Operator를 만드는 방식을 고민해 봤습니다.
하지만 두 오퍼레이터의 시그니처(속성)가 다른 부분이 꽤 있었으며 개발하더라도 본질적인 문제 해결이 아니라고 판단하였습니다.
고민 끝에 결국 개발 환경의 Kubernetes Cluster에 직접 연결해서 Pod을 띄우는 방식으로 문제를 해결하였습니다. 여기서 제일 신경 썼던 부분은 사용자가 쿠버네티스를 알지 못해도 동작할 수 있도록 추상화를 하는 것입니다. 로컬에서는 기본적으로 KubernetesPodOperator를 실행하게 되면, Service Account 기반의 K8s 인증을 한 후 미리 생성한 Namespace(Local 전용 Namespace)에 Pod을 띄울 수 있도록 하였습니다.
- OAuth 인증이 아닌 GCP Service Account 기반의 인증을 할 수 있도록 Service Account를 발급하고 이를 기반으로 .kubeconfig 파일을 사전 정의하여 Docker Image에 Mount 합니다. 이 덕분에 사용자는 Kubernetes 관련 설정(Kubectl, 인증 설정 등)을 하지 않아도 됩니다. (Kubernetes API 서버에 인증 글에서 더 자세한 내용을 확인할 수 있습니다)
-
K8s RBAC을 활용해 미리 허용한 Service Account를 대상으로 Airflow 전용 Namespace에서 K8s Pod의 CRUD가 가능하도록 합니다. 해당 Namespace를 제외하고는 다른 자원에 접근할 수 없도록 Role을 관리합니다.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: airflow-feature-role labels: ... rules: - apiGroups: [""] resources: ["*"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["pods"] verbs: ["get", "list", "create", "delete", "update", "patch"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: airflow-feature-role labels: ... namespace: airflow-feature subjects: - kind: User name: "<service_account>" ... roleRef: kind: Role name: airflow-feature-role apiGroup: rbac.authorization.k8s.io -
사용자는 KubernetesPodOperator의
in_cluster와config_file속성을 설정합니다. 꼭 KubernetesExecutor가 아니더라도 다른 Executor에서도 KubernetesPodOperator를 실행할 수 있다는 사실 알고 계셨나요? 아래와 같이 설정을 해주면 로컬에서도 K8s 인증을 하고 Pod CRUD가 가능합니다.task1 = KubernetesPodOperator( ..., in_cluster=False, config_file="/opt/airflow/.kube/config" # Service Account 기반 인증을 설정한 kubeconfig 파일의 경로 )
DAG 파싱 효율화를 위한 .airflowignore 활용
DAG 개수가 늘어나게 되면 Scheduler는 모든 DAG을 파싱 하기까지 시간이 오래 걸리며 컴퓨팅 자원을 많이 소비하게 됩니다. 따라서 개발 중인 DAG들만 Parsing 할 수 있다면 자원을 아끼고 개발 시간을 단축할 수 있습니다.
.airflowignore를 활용하여 Glob 패턴으로 특정 디렉토리를 제외하고는 Parsing이 되지 않도록 설정할 수 있습니다.
그리고 사용자가 로컬 환경에서 개발할 때 해당 디렉토리 (e.g., _development 폴더)에서 개발하도록 README를 통해 가이드를 주었습니다.
^((?!_development).)*$
(.airflowignore에 대한 내용은 Airflow 공식 문서를 참고해 주세요)
2.3. 테스트 환경 구축
신뢰성 있는 소프트웨어를 운영하기 위해선 테스트는 선택이 아닌 필수입니다. 테스트 작성 및 자동화를 통해 많은 사용자들이 개입하는 코드 베이스의 안전성을 높일 수 있으며 코드 퀄리티를 높게 유지할 수 있습니다.
테스트 코드 작성
수많은 DAG에 대해 모두 테스트 코드를 작성하기보다는 변경된 DAG 파일을 대상으로 DAG 문법 검사 및 일부 포맷 검사를 하는 방식으로 테스트 코드를 작성했습니다. 이를 위해선 커밋에서 변경된 DAG들을 대상으로 문법에 맞게 잘 작성되었는지 dagbag을 활용했습니다.
-
변경되는 파일을 추출하여 테스트를 실행하는 스크립트
#!bin/sh set -eo pipefail staged_files=${@:-$(git diff --cached --name-status | awk '$1 != "D" { print $2 }')} echo "[staged_files] ${staged_files}" airflow db init # Airflow DagBag Test를 위해선 Backend DB가 생성되어야 합니다. PYTHONPATH=. files=$staged_files python -m pytest tests/test_dag_bag.py -
pytest의
monkeypatch을 활용해 외부 의존성(Service Account, BaseHook 등)을 Mocking 합니다.@pytest.fixture def changed_files() -> List[str]: changed_files = os.getenv("files", "").replace("\n", " ").split() changed_dag_files = [ path for path in changed_files if path.startswith("dags/") and might_contain_dag(file_path=path, safe_mode=True) ] return changed_dag_files @pytest.fixture def monkey_patching(monkeypatch): # Mock monkeypatch.setattr(Credentials, "from_service_account_file", lambda *args, **kwargs: "") ... -
변경된 DAG들을 대상으로 다양한 테스트를 진행합니다.
# 기본 DAG의 문법을 DagBag을 통해 테스트합니다. def test_dags_validate(changed_files, monkey_patching): for dag_file in changed_files: ... dagbag = DagBag(dag_folder=dag_file, include_examples=False) assert len(dagbag.dags.keys()) >= 1 assert len(dagbag.import_errors) == 0 # DAG에 Owner를 쏘카 이메일 형식(e.g., grab@socar.kr)으로 작성했는지 테스트합니다 def test_dags_owner_validate(changed_files, monkey_patching): for dag_file in changed_files: ... dagbag = DagBag(dag_folder=dag_file, include_examples=False) dag = list(dagbag.dags.values())[0] assert validate_owner_format(dag.owner) # 로컬에서 KubernetesPodOperator를 테스트한 후 설정을 다시 되돌렸는지 테스트합니다 def test_pod_operator_config(changed_files, monkey_patching): POD_OPERATOR_LIST = ["GooglesheetToBigqueryOperator", "KubernetesPodOperator"] for dag_file in changed_files: ... dagbag = DagBag(dag_folder=dag_file, include_examples=False) dag = list(dagbag.dags.values())[0] for task in dag.tasks: if task.task_type in POD_OPERATOR_LIST: assert task.in_cluster is not False, f"{task.task_type}의 in_cluster 속성을 삭제해 주세요" assert task.config_file is not None, f"{task.task_type}의 config_file 속성을 삭제해 주세요" ...
이 외에도 팀에서 직접 만든 Operator나 Helper 코드에 대한 테스트를 작성 중에 있습니다.
Github Action을 통한 테스트 자동화
쏘카에서는 현재 대부분의 CI 파이프라인으로 github action을 사용하고 있습니다. Github Action을 활용하면 workflow 파일을 통해 간단하게 테스트 자동화가 가능합니다.
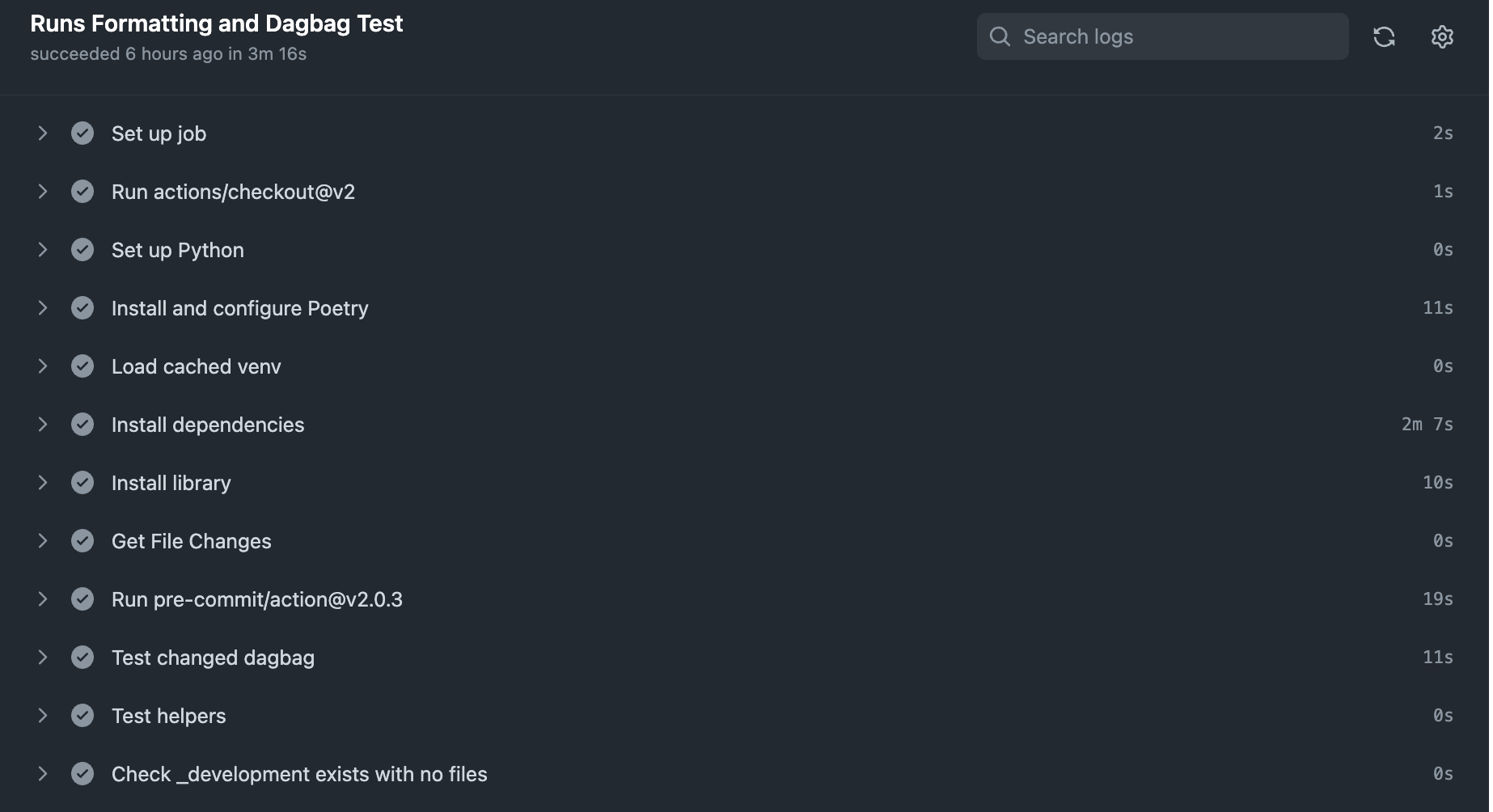 쏘카에서 사용하는 Airflow Repo의 Github Action
쏘카에서 사용하는 Airflow Repo의 Github Action
현재 CI 워크플로우는 아래와 같이 동작합니다
- 변경된 파일들을 감지합니다.
- Pre Commit으로 정해진 컨벤션(
autoflake,black,isort등)에 맞게 작성했는지 확인합니다. - 변경된 파일을 대상으로 위에서 작성한 테스트를 실행합니다.
- 로컬 환경에서 개발할 때 사용한 파일이나 설정 등을 되돌렸는지 확인합니다.
운영 환경으로 머지되는 모든 Pull Request는 위 워크플로우를 통과하고 한 명 이상의 리뷰어의 승인이 있어야 머지 될 수 있도록 설정하였습니다.
2.4. 사용자의 Airflow 러닝 커브를 낮추기 위한 시도들
처음 Airflow를 사용한다면 DAG, Task를 작성하는 방법부터 시작해서, 컨벤션에 맞게 코드를 작성하는 것은 난도가 높을 수 있습니다. 따라서 사용자가 최대한 빠르게 온보딩 할 수 있도록 문서화 및 교육을 진행하였습니다.
Airflow 환경 설치 & 개발 가이드 등 문서화
Airflow 로컬 환경 구축 가이드(Docker, Python 환경 등)을 시작으로 트러블슈팅, 개발 가이드 등을 문서화하여 기존 사용자와 신규 입사자가 더 빠르게 Airflow에 온보딩 할 수 있도록 하였습니다.
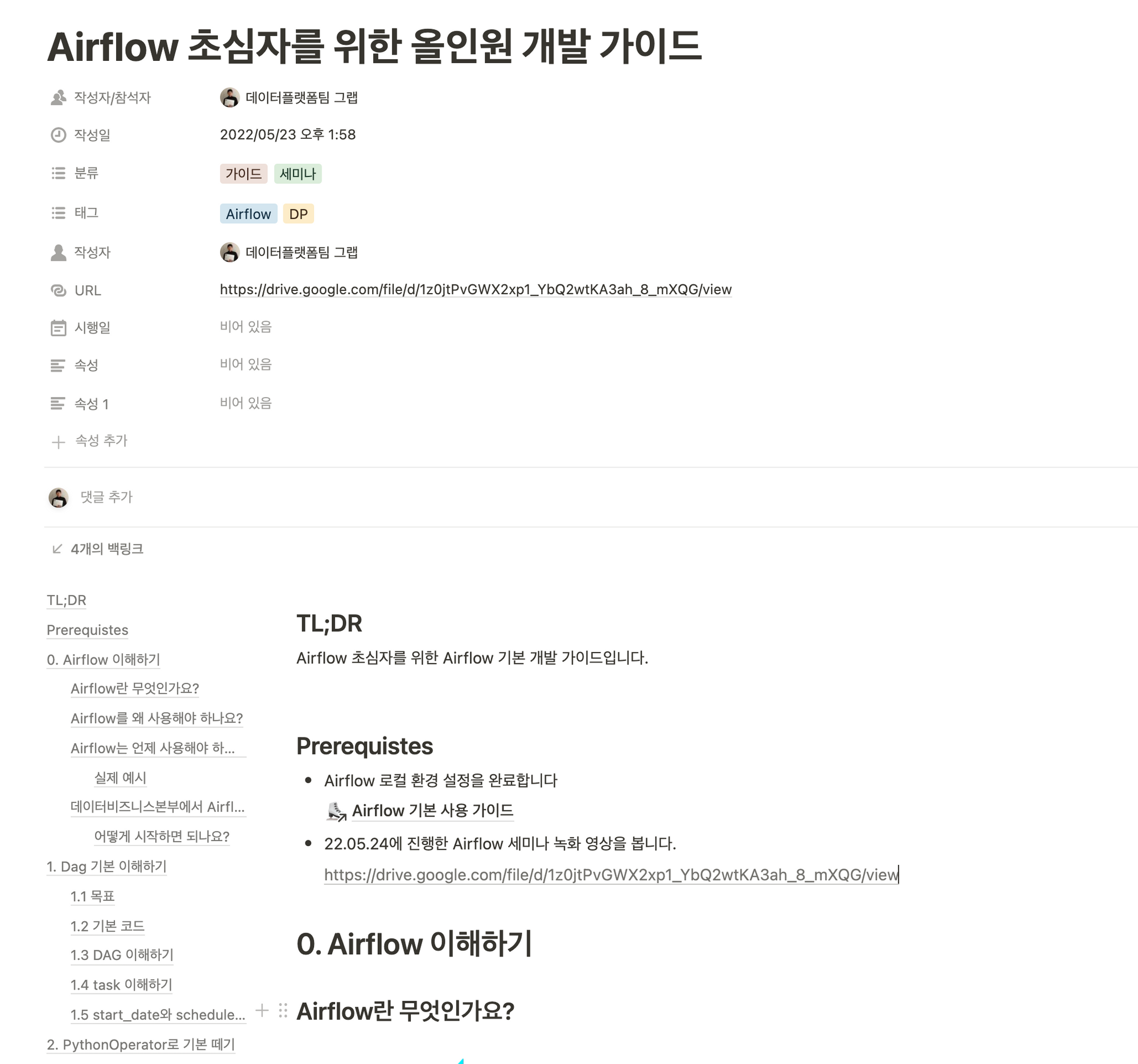 사내 Airflow 이용자를 위해 만든 가이드
사내 Airflow 이용자를 위해 만든 가이드
사내 Airflow 교육 진행
Airflow를 사용하고 싶은 사람들을 대상으로 사내 Airflow 세미나를 열었습니다. Airflow 기본 개념부터 DAG 작성법과 각종 Operator 사용법 등을 제공했으며 추후 녹화본도 공유되었습니다.
 Airflow 사내 세미나 녹화본
Airflow 사내 세미나 녹화본
오피스 아워, 슬랙 문의 채널 운영 등을 통해 개발 서포트
데이터 플랫폼 팀에서는 격주 오피스 아워를 통해 Airflow, MLOps Platform 등 데이터 플랫폼을 사용하면서 생기는 문제들을 자유롭게 질문할 수 있도록 하고 있습니다. 또한 슬랙 문의 채널을 통해 데이터 플랫폼 이용 관련 질문들을 할 수 있도록 하여 사용하는데 불편함이 없도록 최대한 서포트하고 있습니다
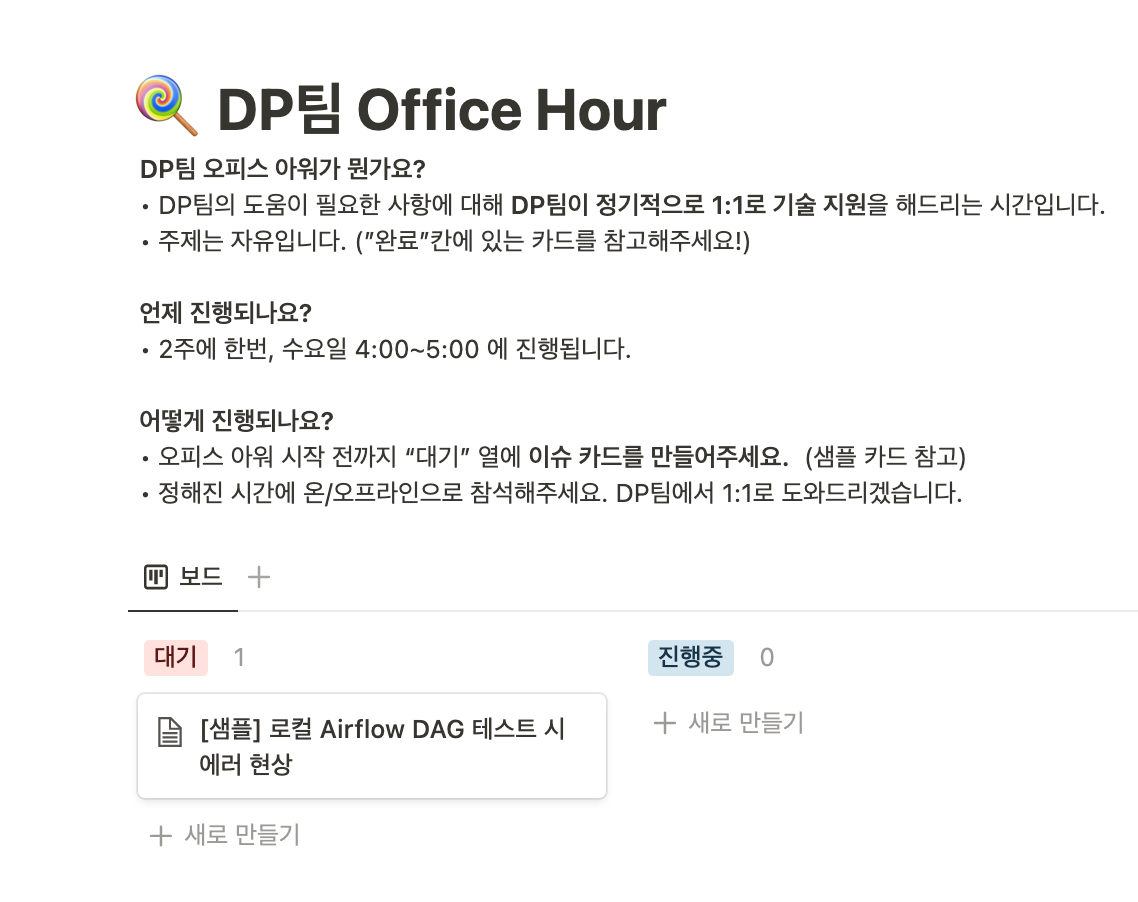 데이터 플랫폼팀 오피스 아워 페이지
데이터 플랫폼팀 오피스 아워 페이지
Makefile 활용해서 쉽게 명령어들 사용할 수 있도록 구성
사용자가 Airflow를 더 편하게 사용할 수 있도록 주요 명령어를 Shell Script 기반으로 작성하고 Makefile 커맨드를 활용하도록 가이드 하였습니다.
project_flag=-p local-airflow
# environment variables
.EXPORT_ALL_VARIABLES:
PROJECT_ROOT_RELATIVE_PATH=.
PYTHONPATH=.
install: ## ♻ 로컬 Airflow 의존성을 설치합니다.
@bash scripts/install.sh
local-airflow: ## 📍 로컬에 Airflow를 띄웁니다.
@bash scripts/run-local.sh
clean-up: ## 🌬 Airflow 환경을 초기화합니다.
@bash scripts/clean-up.sh
3. 지속적으로 Airflow 안정화하기
3.1. 목적
Data Freshness를 항상 유지할 수 있도록 합니다.
Data Freshness는 데이터가 얼마나 최신 상태인가를 나타냅니다. Airflow는 배치 데이터 파이프라인의 오케스트레이션 툴인만큼 단일 실패 지점(SPOF, Single Point Of Failure)이 되기도 합니다. 만약 Airflow가 모종의 이유로 중단될 경우 제시간에 데이터가 적재되지 않을 것이며 이는 Data Freshness를 유지하기가 어려워집니다. 따라서 Airflow의 신뢰성을 높이고 지속적으로 퍼포먼스를 확인하고 개선하는 것이 필요합니다.
3.2. Airflow 2 마이그레이션
기존 Airflow 1 버전은 DAG 개수가 늘어나면서 연속적인 Task Instance 스케줄링 간 Lag이 길었고 기타 자잘한 버그들이 있었습니다. Airflow 2에서 대표적으로 개선된 부분들은 아래와 같습니다.
-
스케줄링 퍼포먼스가 개선되었습니다.
Airflow 2는 DAG Serialization과 Fast-Follow를 도입하여 Scheduler의 반복적인 DAG 파싱 작업을 줄이고 Task Scheduling 과정을 개선하였습니다. Astronomer 블로그에서 벤치마크 테스트를 했을 때 10배 이상의 성능 개선이 있었다고 합니다. 팀에서 경험하는 문제였던 Task instance 스케줄링 간 Lag 현상도 많이 줄었습니다.
-
Scheduler HA(High Availability)를 지원해서 스케줄러의 Scale Out이 용이합니다.
Active-Active 클러스터 형태로 Scheduler의 HA를 지원합니다. 이때 Meta DB는
SELECT ... FOR UPDATE로 Row Level Lock이 걸리게 됩니다. -
웹 서버 사용성이 개선되었습니다.
DAG Serialization을 통해 더 빠르게 웹 UI에서 더 빠르게 DAG 정보를 불러올 수 있으며 Auto Refresh 기능 등 사용성이 개선되었습니다. 저희 팀에서도 사용자의 Airflow 사용성을 위해 지속적으로 하위호환성을 고려하며 버전을 업그레이드하고 있습니다. 글을 쓰는 시점인 2.3 버전은 더 직관적인 UI를 제공해 주어 저희 팀에서도 2.3 버전으로 업그레이드를 완료하였습니다.
이 외에도 TaskFlow API 도입, Airflow Core Component에서 Provider 분리, Task Group, Smart Sensor 도입 등등 많은 변화가 있습니다. 더 궁금하신 분들은 해당 글을 읽어보시면 도움이 될 것 같습니다.
![]() Airflow 로고를 커스텀 해보았습니다.
Airflow 로고를 커스텀 해보았습니다.
Airflow 2로 마이그레이션하면서 1 버전과 호환성이 깨지는 부분들이 다소 있었고 이를 해결하는 데 시간이 꽤 소요됐습니다. 하지만 마이그레이션 한 후 Airflow의 스케줄링 퍼포먼스가 올라갔으며 Task/DAG 간의 의존관계가 복잡하거나 코드가 복잡한 경우도 제공되는 API를 잘 활용하여 코드 퀄리티를 높일 수 있었습니다.
3.3. 스케줄러 성능 최적화를 위한 Configuration 설정
Airflow는 Scheduler, Webserver의 성능을 Configuration 을 통해 설정할 수 있도록 지원합니다. 팀에서도 많은 DAG들을 운영하는 과정에서 스케줄러 성능 최적화를 위해 아래처럼 Configuration을 변경하였습니다.
| 변수명 | 정의 | 설정 내용 |
|---|---|---|
AIRFLOW__CORE__PARALLELISM |
스케줄러 당 동시에 스케줄링 가능한 DagRun 개수에 대한 설정 | 병렬 처리를 위해 기존보다 높게 설정 |
AIRFLOW__SCHEDULER__PARSING_PROCESSES |
스케줄러가 DAG 파일을 파싱 할 때 사용할 Process 개수에 대한 설정 | 스케줄러 HA를 적용하기도 했고, CPU 사용량에 비해 기대효과가 잘 나오지 않아 기존 값 유지 |
AIRFLOW__SCHEDULER__MIN_FILE_PROCESS_INTERVAL |
스케줄러가 DAG File을 파싱 하는 주기(초)에 대한 설정 | Parsing 시 CPU 사용량이 높아져서 기존보다 높게 설정 |
AIRFLOW__SCHEDULER__POOL_METRICS_INTERVAL |
pool 사용량을 StatSD로 보내는 주기에 대한 설정 | 공식 문서에 상대적으로 비싼 쿼리라고 명시되어 있어 기존보다 높게 설정 |
Scheduler에서 지속적으로 스케줄링 지연 현상이 발생하면 아래 Configuration도 함께 조정할 계획입니다.
| 변수명 | 정의 |
|---|---|
AIRFLOW__KUBERNETES__WORKER_PODS_CREATION_BATCH_SIZE |
스케줄러가 한 번 루프를 돌 때 Worker Pod 최대 생성 개수에 대한 설정 KubernetesExecutor를 사용할 때 더 높은 퍼포먼스를 기대할 수 있음 |
AIRFLOW__SCHEDULER__MAX_DAGRUNS_PER_LOOP_TO_SCHEDULER |
스케줄러가 한 번 루프를 돌 때 얼마나 많은 DagRun들을 처리할지에 대한 설정 |
AIRFLOW__SCHEDULER__MAX_DAGRUNS_TO_CREATE_PER_LOOP |
스케줄러가 한 번 루프를 돌 때 얼마나 많은 DAG이 DagRun을 생성하게 할지에 대한 설정 |
스케줄러 성능 튜닝에 대해 더 자세하게 알고 싶다면 공식 문서 와 Astronomer 블로그 문서를 읽어보세요.
3.4. 고가용성 설정
Airflow 2에서는 Scheduler HA 설정이 가능합니다. 즉 복수개의 Scheduler를 통해 DAG 스케줄링 지연을 개선할 수 있습니다. 저희는 공식 Helm Chart를 사용하고 있기에 손쉽게 HA 설정을 하였습니다.
 Airflow Scheduler HA 설정
Airflow Scheduler HA 설정
이때 한 가지 주의할 점은 Scheduler가 증가하는 만큼 Meta DB의 부하도 증가하게 된다는 것입니다. Scheduler들은 Row Level Locking(SELECT … FOR UPDATE) 방식으로 DAG, Task 등 자원에 접근하므로 Scheduler가 늘어나면 자연스럽게 Meta DB의 자원 사용량도 높아집니다. 그래서 데이터베이스의 메트릭을 보면서 스케일 업을 해주거나 다중화를 설정하는 것도 하나의 옵션일 것 같습니다.
3.4. Kubernetes 환경 개선
저희는 K8s 환경에서 Airflow를 운영하기 때문에 Kubernetes의 자원 관리도 함께 고려해야 합니다. 현재 운영 중인 DAG이 700개가 넘기 때문에 많은 Task Pod들이 각각 리소스를 점유하게 됩니다. 만약 특정 시간대에 DAG들이 몰려있는 경우 K8s Node의 리소스가 부족해지고 해당 Node에 떠있는 Pod들의 성능이 저하될 수 있습니다.
Node Pool 분리 및 Auto Scaling 적용
기본적으로 K8s에서 Airflow를 구성하는 컴포넌트는 기본 구성 컴포넌트(Scheduler, Webserver 등)과 Worker Pod으로 분리할 수 있습니다. 기본 컴포넌트는 요청 자원이 충분히 예측 가능한 반면, Worker Pod은 시간대에 따라 요청하는 자원이 다릅니다.
그래서 저희는 Worker Pod을 별도로 Ochestration 하는 Node Pool을 분리하였습니다. 그리고 해당 Node Pool은 Auto Scaling을 적용하여 유동적으로 Throughput을 늘려줄 수 있도록 하였습니다.
사용자의 Task 리소스 직접 할당
K8s 환경의 장점은 Task 별로 자원 할당을 할 수 있다는 점입니다. CPU Bound 한 Task의 경우 CPU 리소스를 높게 할당하고, I/O Bound 한 Task는 CPU 리소스를 낮게 관리하여 K8s Node의 자원 관리를 더 효율적으로 할 수 있습니다. 아래와 같이 Operator의 K8s 리소스 설정을 Patch 하는 assign_operator_resources라는 Helper 함수를 만들어서 관리하고 있습니다.
@dataclass
class DynamicResource:
"""
요청할 cpu, memory 자원을 입력해 줍니다.
ex) cpu: "500m", memory: "500Mi"
- cpu의 기본 단위는 m으로 1000m이 1코어라고 보시면 됩니다.
- memory의 기본 단위는 Mi로 MB와 동일합니다.
"""
request_cpu: str
request_memory: str
limit_cpu: Optional[str] = None
limit_memory: Optional[str] = None
def __post_init__(self):
# validation
_request_cpu = int("".join(re.findall(r"\d+", self.request_cpu)))
_request_memory = int("".join(re.findall(r"\d+", self.request_memory)))
_limit_cpu = int("".join(re.findall(r"\d+", self.limit_cpu))) if self.limit_cpu else None
_limit_memory = int("".join(re.findall(r"\d+", self.limit_memory))) if self.limit_memory else None
if (_request_cpu and _limit_cpu) and (_request_cpu > _limit_cpu):
raise ValueError("request_cpu가 limit_cpu보다 클 수 없습니다")
if (_request_memory and _limit_memory) and _request_memory > _limit_memory:
raise ValueError("request_memory가 limit_memory보다 클 수 없습니다")
def assign_operator_resources(operator: BaseOperator, resource: DynamicResource) -> BaseOperator:
"""
KubernetesPodOperator가 아닌 Operator들도 Resource 할당이 가능하도록 설정합니다.
"""
operator.executor_config = {
"pod_override": k8s.V1Pod(
spec=k8s.V1PodSpec(
containers=[
k8s.V1Container(
name="base",
resources=V1ResourceRequirements(
limits={"cpu": resource.limit_cpu, "memory": resource.limit_memory},
requests={"cpu": resource.request_cpu, "memory": resource.request_memory},
),
)
],
)
)
}
return operator
t1 = assign_operator_resources(
PythonOperator(
task_id="t1",
python_callable=...,
...
),
resource=DynamicResource(request_cpu="100m", request_memory="128Mi", limit_cpu="300m", limit_memory="256Mi"),
)
3.5. Clean Up DAG 적용
실제로 DAG 개수가 많아지고 운영 기간이 길어질수록 데이터베이스에 히스토리 관련 레코드들이 많이 쌓여있게 됩니다. 이는 데이터베이스의 성능을 저하시키고 Scheduler의 쿼리 성능 저하를 유발하여 전체적인 퍼포먼스가 떨어지게 됩니다.
따라서 주기적으로 오래된 DAG과 Task 등 Historical Record들을 지워주게 되면 쿼리 속도를 향상시킬 수 있습니다. 저희는 teamclairvoyant의 airflow-maintenance-dags 레포지토리 를 참조하여 특정 기간 내에 DAG, Task Instance 등을 지워주는 DAG을 스케줄링했습니다.
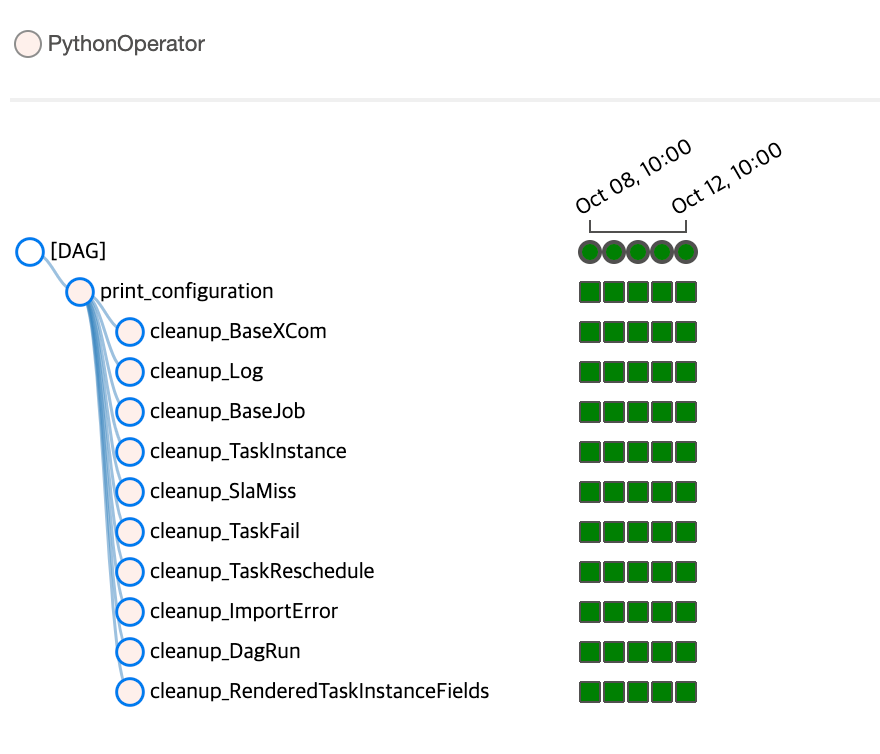 Clean Up DAG의 Task 목록
Clean Up DAG의 Task 목록
실제로 Clean Up DAG이 스케줄링되면서 Database의 리소스 사용량이 상당량 줄었으며, Airflow의 스케줄러 및 웹 서버의 성능 향상을 체감하였습니다.
4. 보안 강화하기
4.1. 목적
코드에서 보안 정보들을 분리합니다.
외부 자원에 많이 의존하게 되는 Airflow의 특성상 코드에 많은 보안 정보들이 담기게 됩니다. 이때 Airflow의 보안 정보들은 코드 상에 노출되는 것보다 Secret 저장소를 활용하도록 하여 보안성을 높일 수 있도록 합니다. 현재 데이터 본부에서 Airflow를 다수의 사용자가 사용하고 있기에 보안에 대한 교육과 정책 수립도 필요합니다.
다수의 사용자를 관리하고 적절한 권한을 줄 수 있도록 합니다.
다수의 사용자가 시스템을 사용할수록 적절한 권한을 부여하는 것이 중요합니다. 따라서 개인 사용자별 인증을 할 수 있도록 계정을 제공하고, 인가를 더 체계적으로 관리하기 위해 RBAC를 적용합니다.
4.2. 보안 강화
기존 Airflow는 소스 코드에 보안 정보들이 포함되어 있었습니다. DAG 코드에 보안 정보들(API Key, Password 등)이 포함되는 경우들이 종종 있었고, Airflow 배포를 위한 Helm Chart에서도 Connection, Variable, 보안이 필요한 환경 변수 등을 그대로 노출하고 있었습니다. 따라서 보안 정보들은 별도의 저장소로 분리하는 작업을 진행했습니다.
GCP Secret Manager 적용
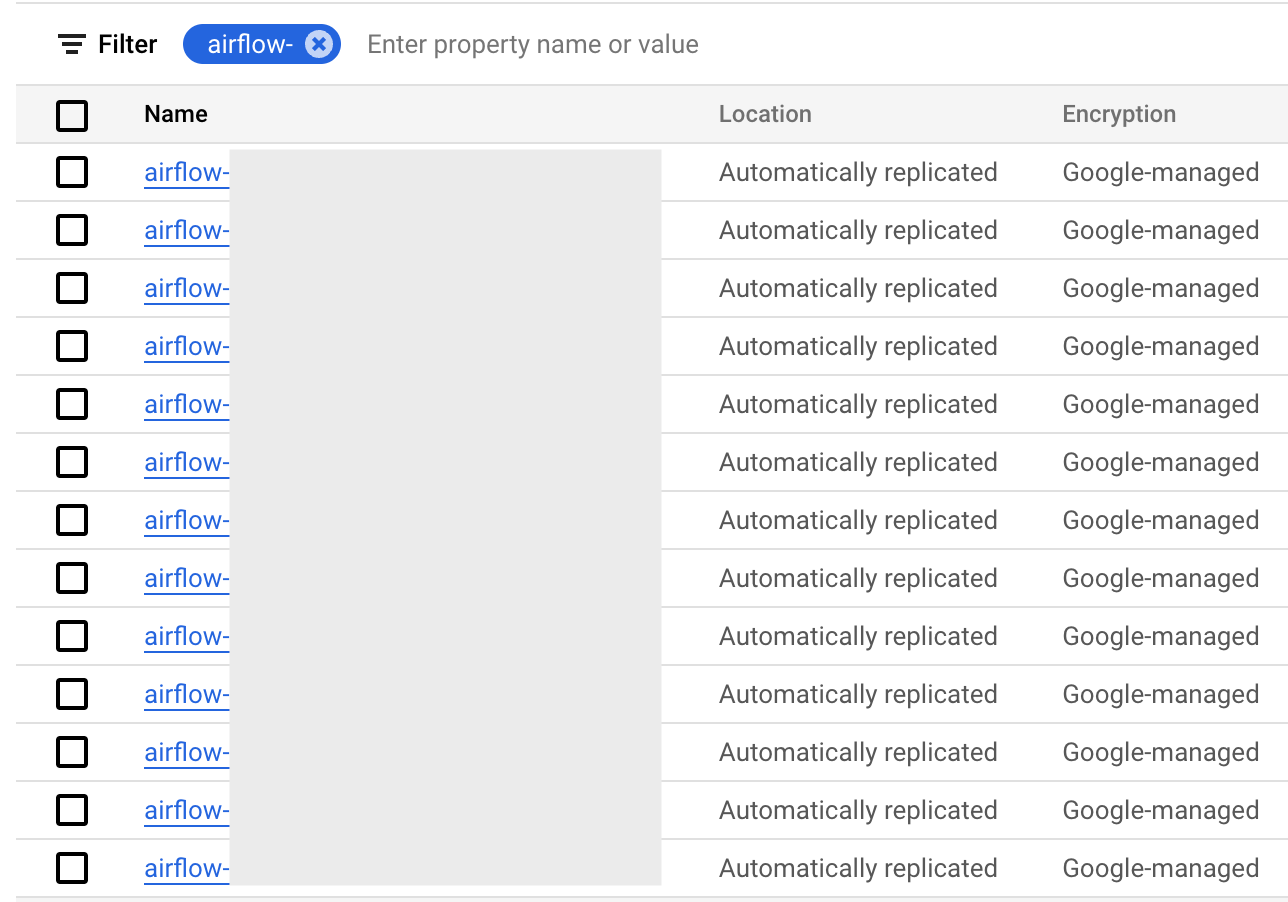 Secret Manager 목록
Secret Manager 목록
GCP Secret Manager는 GCP에서 제공해 주는 보안 정보 관리 툴입니다. 기본적으로 IAM을 통해 세부 권한 조정이 가능하며, 다양한 클라이언트에서 접근할 수 있도록 API를 제공합니다. GCP Secret Manager를 사용하면 손쉽게 보안 정보들과 코드를 분리할 수 있습니다.
저희는 GCP Secret Manager를 활용할 때 DAG에 하드코딩되어 있는 경우 Airflow Variable 혹은 Secret Manager SDK(Python)를 사용하였습니다. K8s의 경우 External Secret 과 함께 사용하고 있는데 External Secret을 활용하면 외부 Secret 저장소(e.g., GCP Secret Manager)를 통해 쉽게 Secret 리소스로 변환이 가능합니다. 보안 정보들을 분리하려면 Airflow 사용자들의 보안에 대한 인지가 필요하고 이를 CI 레벨에서 막을 수 있도록 하는 장치도 필요합니다. 현재 저희는 사용자가 암호화된 정보를 직접 저장하고 관리할 수 있도록 프로세스를 구축하고 있으며, 보안 정보들을 감지할 수 있도록 돕는 GitGuardian Action 같은 오픈소스를 검토 중에 있습니다.
Secret Backend 적용을 통해 하드코딩된 Connection, Variable을 옮기기
Airflow에서는 Secret Backend로 GCP Secret Manager, Vault 등 시크릿 관리 툴을 설정할 수 있도록 지원합니다. 위에서 언급한 것처럼 GCP Secret Manager를 Secret Backend로 사용하여 Connection, Variable을 암호화하여 사용하고 있습니다.
AIRFLOW__SECRETS__BACKEND: airflow.providers.google.cloud.secrets.secret_manager.CloudSecretManagerBackend # GCP Secret Manager 적용
AIRFLOW__SECRETS__BACKEND__KWARGS: '{ "connections_prefix": "airflow-connections", "variables_prefix": "airflow-variables", "gcp_key_path": "..." }'
위와 같이 AIRFLOW__SECRETS__BACKEND 환경 변수를 활용해 Secret Backend 설정이 가능합니다. 그리고 AIRFLOW__SECRETS__BACKEND__KWARGS 환경 변수를 활용하면 Connection, Variable의 Prefix를 설정해두면 GCP Secret Manager에 Prefix에 맞게 작성된 Secret들을 자동으로 불러오게 됩니다.
더 자세한 내용은 여기를 참고해 주세요.
4.3. RBAC 적용 (진행 중)
Airflow는 RBAC(Rule Based Access Control) 을 제공합니다. 기본적으로 제공해 주는 Role(Admin, Public, Viewer 등) 뿐만 아니라 Resource, DAG Based Permission에 기반한 Custom Role을 만들 수도 있습니다. (저희 팀은 현재는 기본 Role에 기반해서 계정을 운영하고 있지만, 추후 액세스 패턴에 맞춰 Custom Role을 만들어 관리할 계획입니다.)
사용자가 많아지면 Airflow 계정 관리도 중요해집니다. 현재 팀 별로 공용 계정을 운영하고 있는데 팀별 계정의 Role이 실제 사용 대비 여유롭게 권한을 부여한 부분이 있습니다. 이는 추후 문제가 발생했을 때 Audit이 힘들어질 수 있습니다.
Airflow의 auth_backend를 활용하면 Airflow Auth API가 아닌 외부 인증 프레임워크를 사용할 수 있습니다. 현재 쏘카에서는 SSO로 Keycloak을 사용하고 있는데 (참고 글 : Keycloak를 이용한 SSO 구축). 위 인증 문제를 해결하기 위해 Airflow 사용자 인증을 Keycloak으로 위임하는 방식을 검토 중에 있습니다. 사용자 별로 인증을 관리할 수 있다면 이후 Audit Log를 통해 문제 해결에 도움을 줄 수 있을 것입니다.
5. 모니터링 고도화하기
5.1. 목적
사용자가 직접 DAG 오류에 대응할 수 있도록 합니다.
사용자가 늘어나고 운영하는 DAG의 개수가 늘어나면서 관리자가 모든 DAG의 맥락을 파악하고 대응하기가 어려워졌습니다. 따라서 DAG 스케줄링, 런타임 오류 등의 1차적 책임은 DAG 사용자(혹은 팀)이 질 수 있도록 하는 것이 중요해졌습니다.
관리자가 더 다양한 지표들을 보고 모니터링할 수 있도록 합니다.
Airflow on K8s의 모니터링을 위해선 Airflow의 상태뿐만 아니라 이를 실행하는 K8s 환경도 함께 모니터링할 수 있어야 합니다. 또한 DAG에 대한 통계 정보(시계열 메트릭, 실패 추이 등)를 보고 거시적으로 대응할 수 있도록 하는 것도 중요합니다.
5.2. DAG 별 모니터링 담당자 지정
데이터 파이프라인을 직접 개발하기 위해 Airflow를 사용하는 경우들이 늘어났고, 현재 700개 이상의 DAG이 운영되고 있습니다. 이에 관리자는 모든 DAG을 관리하고 문맥을 파악하는 것이 힘들어졌습니다. 따라서 1차적으로 DAG 개발/동작에 대한 책임은 DAG 사용자(개발자)가 질 수 있도록 기반 모니터링 환경을 구축하였습니다(기본적인 Airflow 개발/관리 교육과 지원을 가정합니다)
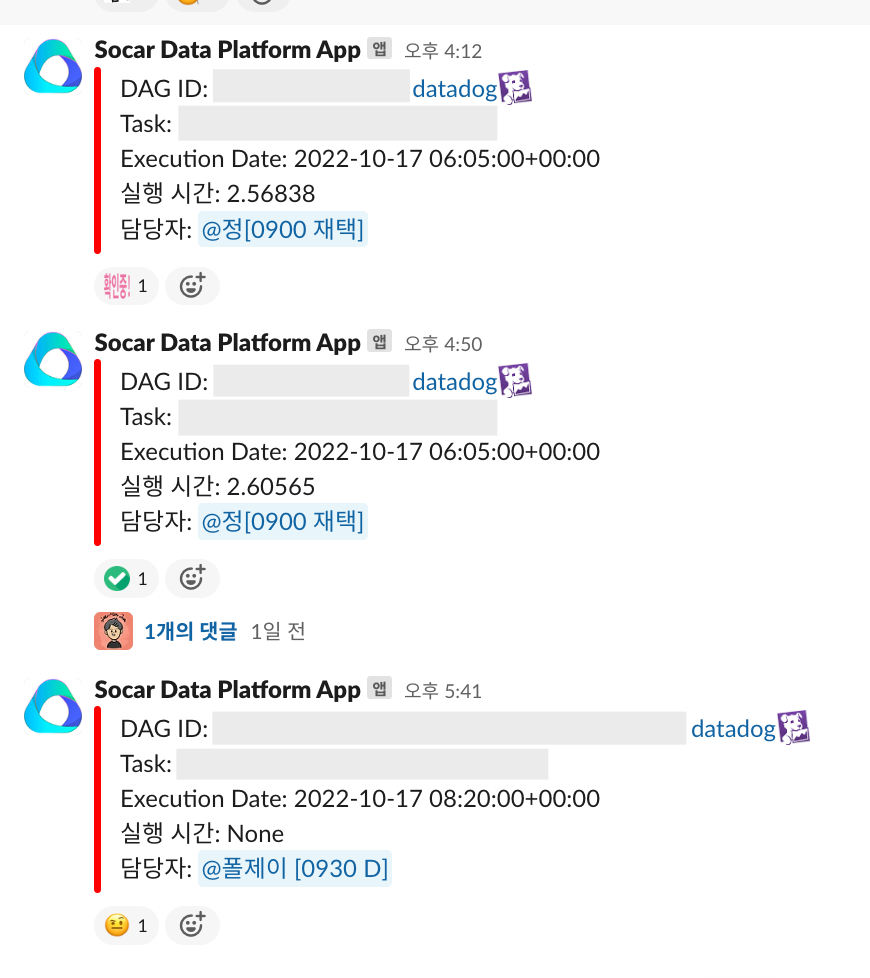 실패한 DAG의 담당자를 태그 하는 알람
실패한 DAG의 담당자를 태그 하는 알람
정상적으로 스케줄 되지 않은 DAG을 모아서 10분에 한 번씩 슬랙 채널에 알림을 주고 있습니다. 이때 즉각적으로 대응할 수 있도록 담당자를 멘션 할 수 있도록 구현하였습니다. 이를 통해 실패한 DAG을 대응하는 속도가 빨라졌으며 관리자도 담당자를 찾고 대응하지 않아도 되기에 관리 비용을 줄일 수 있었습니다.
@dag(
schedule_interval="*/10 * * * *",
default_args={"owner": "grab@socar.kr"},
...
)
def failed_dag_alert_v2():
...
@task
def get_failed_dag_list():
start_date, end_date = get_query_datetime()
session: sqlalchemy.orm.Session = settings.Session()
query = (
session.query(DagModel, TaskInstance)
.join(TaskInstance, TaskInstance.dag_id == DagModel.dag_id)
.filter(
TaskInstance.state == "failed", TaskInstance.end_date >= start_date, TaskInstance.end_date < end_date
)
)
result: List[Tuple[DagModel, TaskInstance]] = query.all()
return [asdict(create_payload(dag_, task_instance)) for dag_, task_instance in result]
@task
def send_slack_notification(failed_dags: List[dict]):
payloads = [DAGAlertPayload(**failed_dag) for failed_dag in failed_dags]
if not payloads:
return
hook = SlackHook(slack_conn_id="slack_dp_monitoring")
# hook.
hook.call(
"chat.postMessage",
json={
"channel": MONITORING_CHANNEL,
"attachments": [
{"color": "#FF0000", "blocks": [payload.to_attachment_block() for payload in payloads]}
],
"username": SLACK_USERNAME,
"icon_url": SLACK_ICON_URL,
},
)
send_slack_notification(get_failed_dag_list())
@dataclass
class DAGAlertPayload:
dag_id: str
task_name: str
execution_date: str
owners: str
duration: str
try_number: int
url_link: str
@property
def owner_name_in_slack(self):
...
def get_linked_text(self, text: str, link: Optional[str] = None):
....
def to_attachment_block(self) -> dict:
return {
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"DAG ID: *{self.get_linked_text(text=self.dag_id, link=self.url_link)}* {self.get_linked_text(text='datadog:datadog:', link=self.get_datadog_dashboard_link())}\n"
f"Task: {self.task_name}\n"
f"Execution Date: {self.execution_date}\n"
f"실행 시간: {self.duration}\n"
f"담당자: <{self.owner_name_in_slack}>\n",
},
}
위와 같이 10분마다 Meta DB에서 실패한 Task를 DAG과 Join 하여 쿼리한 후, 입력된 Owner 정보를 바탕으로 담당자 멘션을 하는 Slack Hook이 호출됩니다.
슬랙 사용자 멘션을 위해선 유저의 ID 값이 필요합니다. 저희는 DAG의 Owner에 Email 정보를 필수로 받도록 하였으며(Github Action을 통해 PR 단계에서 검증합니다) 슬랙의 users.lookupByEmail API를 활용하여 해당 문제를 해결하였습니다.
5.3. 관리자 모니터링
Airflow는 내부적으로 statsd를 통해 Metric을 외부로 전송이 가능합니다. 대표적인 Metric으로는 Task Instance의 성공/실패 개수, DAG Run의 Task 실행 시간, DAG Run의 스케줄 딜레이 시간 등이 있습니다. 더 자세한 내용은 Airflow 공식 문서를 참고해 주세요.
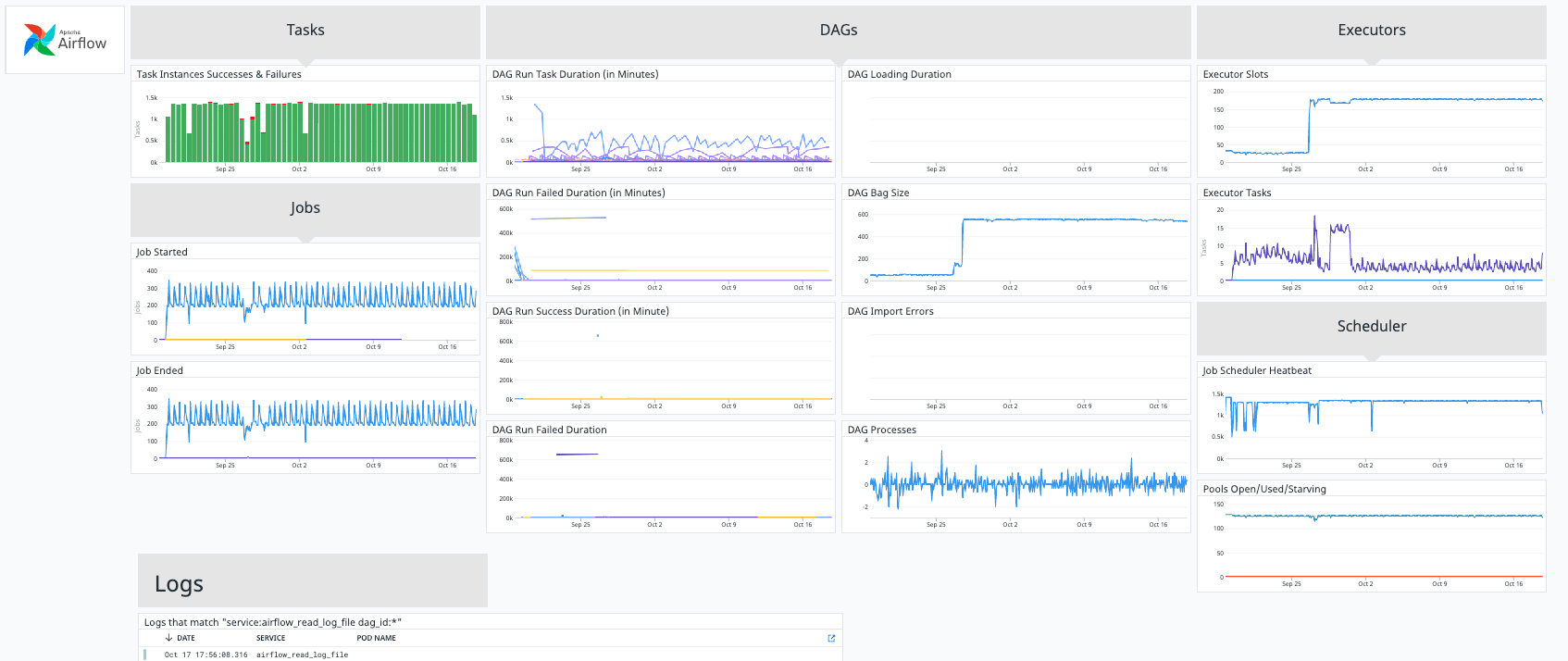 Datadog의 Airflow Dashboard
Datadog의 Airflow Dashboard
쏘카는 전사 모니터링 툴로 Datadog을 사용하고 있는데, Datadog에서 Airflow Integration 을 제공하므로 손쉽게 주요 Airflow Metric을 대시보드로 확인할 수 있습니다. 저희는 Airflow 공식 차트를 통해 statsd 설정을 통해 Datadog과 연결하여 사용하고 있습니다. Datadog에서 수집한 Metric들을 통해 저희가 집중해서 봐야 할 대상(e.g., 너무 오래 실행 중인 DAG)을 알림으로 만들어 슬랙에서 확인이 가능하도록 하고 있습니다.
Kuberentes의 경우도 동일하게 Datadog을 활용하여 모니터링하고 있습니다. Kubernetes 전용 대시보드를 통해 기본 상태를 확인하고 있으며, Task의 Log(Remote Logging)가 제대로 남지 않는 문제가 발생했을 때 Pod Log를 보고 있습니다. 현재 Kubernetes를 Managed Service인 GKE(Google Kubernetes Engine)로 사용하고 있는데, 간혹 Node가 갑자기 내려가서 Task가 실패하는 경우들도 발생하고 있습니다. 이 경우 Task의 로그가 제대로 남지 않아서 K8s Node의 상태와 기타 인프라 상황을 종합적으로 검토하여 문제를 해결하려고 시도 중입니다.
6. 되돌아보기
6.1 좋아진 점
기존보다 빠르고 쉽게 원하는 데이터 파이프라인 구축이 가능해졌습니다.
불편했던 개발 환경과 DAG 개발에 대한 러닝 커브가 높았던 문제가 있었지만, 현재 팀 차원에서 Airflow 사용법에 대한 교육을 진행하고 쉽고 빠르게 개발할 수 있도록 개발 환경을 개선하고 있습니다.
또한 사용자가 Kubernetes를 알지 못하도록 관심사를 분리하고, 인프라 의존 관계를 걷어내서 사용성을 개선하였습니다.
안정적인 Airflow 운영이 가능해졌습니다.
매니지드 서비스가 아닌 K8s Native 환경에서 Airflow를 운영하기 위해선 신경 써야 할 부분들이 꽤 있습니다. K8s 관리/운영으로 시작해서 KubernetesExecutor의 동작 방식을 이해하고 최적화 방안도 계속 고민해야 합니다. K8s 인프라 환경에 대한 모니터링을 강화하고 있으며, Airflow를 지속적으로 업그레이드하고 유연하게 자원을 분배할 수 있도록 하여 Airflow 운영을 안정적으로 할 수 있게 됐습니다.
모니터링 및 보안 환경이 개선되었습니다.
기존에는 장애가 발생했을 때 K8s Pod이나 Node에 직접 접근해서 Log, Event를 확인했다면, 현재는 모니터링 대시보드를 통해 거시적으로 문제를 파악하고 해결하고 있으며 사용자가 빠르게 장애에 대응할 수 있는 환경을 구축하였습니다.
또한 다수의 사용자들이 접근하는 만큼 보안에 취약할 수 있기에, 보안 정보들을 중앙 저장소에서 관리할 수 있도록 하고 사용자 교육과 시크릿 탐지 자동화 등 개선 작업을 진행 중에 있습니다.
6.2 발전해야 할 점
Airflow를 Docker Compose 환경으로 옮기면서 확실한 이점들이 있지만 아직까지 해결해야 하는 문제들도 있습니다.
- M1 호환 문제 : 데이터 본부 팀원들이 사용하는 MacOS는 Intel과 M1 두 가지로 나뉩니다. 기존의 Intel은 Docker 호환에 크게 문제가 없지만 M1의 경우 특정 부분에서 호환이 안되는 이슈가 있으며, Airflow 의존성 일부가 제대로 설치되지 않는 문제들이 있습니다.
- 추상화 개선 : 로컬 환경 사용에 대해 추상화를 해두었지만, 사용자들이 Python 환경(
poetry,pyenv)과 Docker에 대해 알고 있어야 하며 파이썬 버전 이슈나 컨테이너 미 종료 이슈 등을 마주칠 때가 있어 해결할 필요가 있습니다. - 의존성 간소화 : 파이썬 의존성을 하나 설치해서 운영까지 올리기 위해서는 3번의 의존성 설치가 필요합니다. Airflow 런타임에서는 Docker Compose에 의존성을 명시해 줘야 하고, 개발하는 IDE에서 Type Hinting과 Auto Complete를 위해서 로컬 가상환경에 의존성을 설치해 줘야 합니다. 또 운영 환경에 배포할 때는 Airflow 이미지 Dockerfile에 의존성을 추가해 준 후 CI 파이프라인을 거쳐야 합니다. 따라서 이런 복잡한 의존성 관리 방식을 간소화할 필요가 있습니다.
이 외에도 보안을 강화하는 동시에 사용성을 해치지 않는 방향으로 Secret Manager 사용 정책과 가이드를 세워야 하며 종종 Pod 로그를 남기지 않고 Task가 실패하는 이슈들이 있어 모니터링 환경을 더 개선하고 알림 정책을 개선할 필요가 있습니다.
6.3 마무리
위와 같은 시도들을 통해 더 많은 사용자가 Airflow를 사용하여 직접 데이터 파이프라인을 구축할 수 있도록 하였으며 동시에 시스템의 신뢰성과 안전성을 높여가고 있습니다. Airflow 로컬 환경을 시작으로 나중에는 Airflow를 모르더라도 사용자가 손쉽게 파이프라인을 구축할 수 있는 사내 플랫폼을 만들 계획입니다.
Airflow는 배치 데이터 파이프라인의 중추인 만큼, 중요하게 관리되어야 합니다. 데이터 플랫폼 팀은 계속해서 사용 패턴에 맞게 Airflow 플랫폼을 개선해 나갈 것이며 궁극적으로 쏘카의 모든 구성원들이 손쉽게 데이터 파이프라인을 구축하여 데이터를 활용할 수 있도록 하겠습니다.
많은 시행착오들을 거치며 Airflow를 함께 고도화하고 있는 험프리, 디니, 루디, 피글렛, 토마스 그리고 모든 데이터 비즈니스 본부 분들에게 감사드립니다.