 케이피
케이피안녕하세요, 쏘카 AI 팀의 케이피라고 합니다.
저희 AI 팀은 다양한 데이터를 이용해 카셰어링 서비스의 운영을 효율화하고, 고객에게 더 나은 이동 경험을 제공하는 AI Product를 연구개발하고 있습니다. Computer Vision, Natural Language Processing 등의 도메인에서 현실의 문제를 해결하는 AI를 연구하고, 실질적인 Business Impact를 낼 수 있는 Product로 만들어가는 일을 하고 있습니다.
최근 여러 기업에서 AI를 도입하면서 AI, Deep Learning, Machine Learning에 관련된 포지션이 많이 늘어나고 있습니다. 그러나 기업마다 정의하는 직무명이 나 요구하는 Responsibility가 달라서 헷갈려 하시는 분들을 종종 질문하는 분들이 많이 계셨습니다.
이번 글에서는 AI에 관련된 포지션에 대해서 간단하게 정리해보고, 쏘카 AI팀의 Applied Research Scientist가 어떤 일을 하는지 소개드리고자 합니다. 이 글을 다 읽으시면 AI에 관련된 포지션이 요구하는 직무 역량에 대해 어느정도 윤곽을 잡고, 쏘카의 Applied Research Scientist가 어떤 일을 하는지도 이해하실 수 있습니다 :)
목차
- AI에 관련된 직무에는 무엇이 있을까?
- Research Scientist
- Applied Research Scientist
- Machine Learning Engineer
- Data Scientist
- 쏘카 AI팀은 어떤 일을 할까?
- Vision Domain
- NLP Domain
- 마무리
AI에 관련된 직무에는 무엇이 있을까?
여러 회사의 Job Description들을 살펴보면, AI, Deep Learning, Machine Learning에 관련된 주요 포지션은 아래 4가지로 정리해 볼 수 있습니다.
- Research Scientist
- Applied Research Scientist
- Machine Learning Engineer
- Data Scientist
Research라는 단어가 포함된 포지션을 보면, Research와 Applied Research를 구분해두었습니다. 그뿐만 아니라, Scientist와 Engineer가 구분되어 있는 포지션도 있습니다. 직무 명만 봐서는 각 포지션이 어떤 일을 하는지 직관적으로 이해하기가 어렵습니다. 이번 글에서는 이 4가지 포지션이 주로 하는 일과 갖추어야 할 핵심 역량에 대해 간단하게 정리하고자 합니다. 이 글을 보시는 분들이 AI와 관련된 포지션을 찾는 데 도움이 되기를 바랍니다.
단, 이 글에서 정리하는 정의가 정답은 아닙니다. 조직마다 추구하는 인재상이 다르고, 시간이 흐르면서 요구하는 역량이 달라질 수 있기 때문입니다. 어느 정도의 윤곽을 잡는 목적으로 참고해 주시면 감사드리겠습니다.
Research Scientist: 어떻게 SOTA를 뛰어넘을 수 있을까?
Concept
Research Scientist는 AI에 관련된 원천 기술을 연구하는 포지션입니다. 특정 비즈니스 도메인 (i.e., 자율주행, 카셰어링 등)에만 적용할 수 있는 주제가 아닌, 여러 비즈니스 도메인에 적용될 수 있는 근간이 되는 원천 기술을 연구하는 포지션이라고 생각합니다.
다양한 도메인에 적용할 수 있는 원천 기술을 연구하기 때문에, Research Scientist들은 여러 도메인의 연구자들이 이해하고 실험 결과를 납득할 수 있는 Public Benchmark Dataset을 이용하는 경우가 많습니다. Research Scientist는 Public Benchmark Dataset에서 이전 연구가 달성한 최고 성능 (State-of-the-Art; SOTA)를 넘어서는 기법을 연구하고, 이전 SOTA의 한계점을 보완하는 기법을 연구하기도 합니다.
2010년 즈음부터 지금까지 이미지, 텍스트(자연어), 시계열, 생성(Generation) 등의 다양한 기법들의 SOTA가 개선되면서 AI 연구가 점점 성장하고 있습니다. 아직 해결되지 않은 문제들과 연구 주제들도 무수히 많이 남아있어, 더 많은 연구들이 등장할 것으로 기대하고 있습니다.
Key Responsibility
Research Scientist는 과거에 제안된 연구들을 파악하고 새로운 연구를 수행해야 하기 때문에, 주로 요구되는 Responsibility는 아래와 같습니다. (조직마다 다르고, 시간이 흐름에 따라 변경될 수 있습니다)
- 기존에 제안된 연구들을 이해하고 구현할 수 있는 능력
- 기존 연구의 한계점을 개선할 수 있는 기법에 대한 Ideation 능력
- 독립적으로 연구 목적을 수립하고 실험 계획, 평가, 공유(논문 작성 등)를 수행할 수 있는 능력
- 다른 연구자들과 원활하게 소통하고 협력할 수 있는 능력
Research Questions
원활한 이해를 돕기 위해 Research Scientist가 고민할 만한 Research Question들을 한 번 정리해 보았습니다.
- Gradient Descent를 기반으로 Learning Objective를 달성하는 것이 아니라, 인간처럼 Reasoning을 하는 AI를 만들 수는 없을까?
- 이미지를 이해하는 여러 Neural Networks Architecture가 있는데, 특정한 패턴에 bias 되지 않고 더 인간처럼 이미지를 이해하는(혹은 인간보다 더 뛰어나게) 구조는 없을까?
- 최근에 제안된 Language Model (BERT, RoBERTa, S-BERT 등)보다 더 인간처럼 (혹은 인간보다 더 뛰어나게) 지식을 이해하는 모델은 없을까?
Applied Research Scientist: 우리 비즈니스 도메인의 문제를 어떻게 풀 수 있을까?
Concept
Applied Research Scientist는 특정 비즈니스 도메인의 문제를 풀 수 있는 AI를 연구하고, 연구된 모델을 배포하는 일을 수행하는 포지션입니다. Research Scientist가 여러 도메인에 범용적으로 적용될 수 있는 AI를 연구한다면, Applied Research Scientist는 특정 도메인에 최적화된 AI를 연구하고 이를 Production 환경에 맞게 구현하는 역할도 수행합니다.
Applied Research Scientist는 Public Benchmark Dataset을 이용하기도 하지만, 현실에서 발생한 Real-world Dataset을 주로 이용합니다. Real-world Dataset 이란 현실에서 발생하는 데이터 셋으로, 쏘카의 경우 카셰어링 서비스를 운영하면서 발생하는 여러 데이터 (i.e., 차량 이미지, 차량 센서, 채팅 텍스트 등)를 의미합니다. 조직이 직면하고 있는 문제를 해결하기 때문에, Public Benchmark Dataset은 논문에서 제안된 여러 기법의 성능을 확인하는 데 사용하고 주된 문제 해결에는 Real-world Dataset을 사용합니다. 하지만 세상만사 쉬운 일이 없듯이 public benchmark에서는 높은 성능을 달성한 기법(모델)이 Real-world Dataset에서는 잘 동작하지 않는 경우가 많습니다. Applied Research Scientist는 Public Benchmark와 Real-world의 차이를 고민하면서, SOTA 기법이 우리 도메인에서 왜 안되는지 (혹은 왜 잘 되는지)를 파악하고, 제안된 여러 기법들을 최적화하거나 새로운 기법을 디자인하기도 합니다.
AI 연구에서 더 나아가, Applied Research Scientist는 Software Engineer, Data Engineer와 협업하여 AI 모델을 배포하는 과정에도 참여합니다. 리서치용으로 작성했던 코드를 배포 가능한 형태로 리팩토링하고, 다른 조직과 커뮤니케이션하며 배포에 필요한 요소들을 결정합니다. 그뿐만 아니라, AI 모델의 추론(Inference) 결과를 모니터링하여 Dataset Shift나 Feature Drift, Out-of-Distribution 샘플이 프로덕션에 들어오는지를 파악합니다.
Key Responsibility
Applied Research Scientist는 도메인의 문제를 해결할 수 있는 AI를 연구하고, 다른 조직과 협업하여 배포하는 과정까지의 업무를 수행하므로, 주로 요구되는 Key Responsibility는 아래와 같습니다.
- 도메인에 대한 이해
- 기존에 제안된 연구들을 이해하고 구현할 수 있는 능력
- 기존에 제안된 연구를 도메인에 최적화하거나 더 나은 방법을 Ideation 할 수 있는 능력
- 독립적으로 연구 목적을 수립하고 실험 계획, 평가, 공유(논문 작성 등)를 수행할 수 있는 능력
- 다른 연구자, 엔지니어, End-User 들과 커뮤니케이션하고 니즈를 파악할 수 있는 능력
Research Questions
원활한 이해를 돕기 위해 Applied Research Scientist가 고민할 만한 Research Question들을 한 번 정리해 보았습니다.
- 논문 A는 ImageNet, SUN, Place 365에서 높은 성능을 달성했는데, 우리 도메인에서는 성능이 높지 않은데, 그 이유가 뭘지? 우리 데이터와 Public Benchmark에는 어떤 차이가 있어서 그럴까?
- 우리 도메인에서 다루는 데이터는 Public Benchmark들과는 너무 다른데, 우리 도메인에서 잘 동작하는 새로운 Neural Architecture를 디자인해 볼까?
- 모델 B가 배포되었을 때 낮은 Overhead를 달성하려면 코드를 어떻게 리팩토링 해야 할까? 모델에 들어가는 Input은 어떻게 설계하고, Inference 결과는 어떤 테이블에 어떻게 적재하지?
Machine Learning Engineer: AI 모델을 어떻게 효과적으로 구현하고 서비스화 시킬까?
Concept
Machine Learning Engineer는 AI 모델의 개발과 서비스에 더 무게를 두고 있는 포지션입니다. Scientist와 커뮤니케이션하며 모델을 구현하고, 효율적으로 모델을 학습시킬 수 있는 환경을 구축하기도 합니다. 모델이 학습이 완료된 이후에는, 효율적으로 Inference를 수행할 수 있는 아키텍처를 구성하거나 모델을 리팩토링합니다.
Key Responsibility
전 문단에서 “효율”이라는 단어가 자주 등장했는데, Machine Learning Engineer는 특정 데이터 셋에서 성능을 향상시키기보다는 모델을 개발하고 운영하는 과정을 효율화하는 포지션입니다. AI 모델의 학습과 배포하는 단계에서 Machine Learning Engineer가 하는 일들을 나열해 보면, 아래 4가지 정도를 꼽아볼 수 있습니다.
- Scientist가 사용하는 데이터 셋을 효율적으로 구축하고 관리하기
- AI 모델을 리팩토링하여 Computation Overhead 줄이기
- GPU 클러스터를 더 효과적으로 사용할 수 있도록 최적화하기
- 반복적인 작업을 자동화할 수 있는 ML Pipeline 구성하기
Machine Learning Engineer는 데이터 셋 구성에서부터 모델 구현, 학습 효율화, 그리고 배포에 이르는 AI 모델의 전 과정에 참여해 효율성을 높이고, 더 나아가 AI 조직의 생산성을 높이는 일을 수행합니다. Research Scientist, Applied Research Scientist뿐만 아니라 Software Engineer, Data Engineer와 자주 커뮤니케이션하면서 효율이 낮은 부분을 찾고, 기술적인 문제를 진단하며, 그 문제를 해결할 수 있는 방법을 찾는 것이 Machine Learning Engineer의 주요한 역할입니다.
Research Questions
원활한 이해를 돕기 위해 Machine Learning Engineer가 고민할 질문들을 몇 개 가져왔습니다.
- 매 실험에 사용된 데이터 셋과 모델의 아키텍처, Weight 파일들이 관리가 어려운데, 이를 좀 효과적으로 관리할 수 있는 방법이 없을까?
- Pytorch로 작성된 모델이 비효율적인 것 같아. 프로덕션에 들어가려면 더 Overhead를 낮춰야 할 것 같은데, Tensorflow로 이를 변환해 볼 수 있을까?
- GPU의 개수는 많은데 그 성능을 100% 사용하지는 못하네. 최대한 효율적으로 GPU 자원을 사용할 수는 없을까?
Data Scientist: 데이터를 기반으로 어떤 Action을 할 수 있을까?
Concept
마지막으로, Data Scientist는 비즈니스 도메인에서 발생한 다양한 데이터를 분석하는 포지션입니다. 비즈니스의 여러 실무자와 커뮤니케이션하며 문제를 해결하며, 그 과정에서 필요한 다양한 업무를 진행합니다. 이때, 가장 중요한 것은 단순 Report가 아닌 Action을 위한 데이터 분석을 수행한다는 점입니다. 목적 없이 데이터를 분석하는 것이 아니라, 분석 결과를 기반으로 실무자가 실제 Action을 수행하기 위한 데이터 분석을 진행합니다.
Key Responsibility
Data Scientist는 주로 비즈니스 도메인에서 발생하는 다양한 종류의 데이터를 다룹니다. 쏘카의 Data Scientist 포지션으로 예를 들어보겠습니다. 쏘카의 Data Scientist는 서비스의 앱, 웹 로그, 유저의 서비스 이용 데이터, 차량의 센서 데이터 등 다양한 영역에서 비즈니스 문제 해결을 위한 문제 정의, 가설 설정, 실험 설계와 성과 측정을 진행합니다. 쏘카는 주로 분석하는 데이터를 기준으로 Business Data Scientist와 Product Data Scientist로 나누어 채용하고 있는데, 공통적으로 요구되는 역량은 아래와 같습니다.
- 비즈니스 임팩트를 위한 문제 정의, 가설 설정, 실험 설계와 성과 측정 능력
- 데이터 기반 비즈니스 알고리즘 개발 능력
- 효과적인 데이터 분석을 위한 핵심 지표의 도출과 관리, 예측 모델링 능력
Research Questions
원활한 이해를 돕기 위해 Data Scientist가 고민할 질문들을 정리해 보았습니다. 이번에는 원활한 이해를 위해 Business Data Scientist와 Product Data Scientist로 나누어서 가져와 보았습니다.
- (Business) 이번 주말에 강남역 10번 출구 쏘카 존의 예약 건은 얼마나 될까?
- (Business) 2022년에 서울시 은평구에 몇 대의 차량을 배차하면 대 당 매출이 얼마나 될 것으로 예측할 수 있을까?
- (Business) 가장 적은 매출이 나올 지역을 데이터에 기반해 찾아주는 알고리즘을 어떻게 만들 수 있을까?
- (Product) 쏘카의 Funnel 중 가장 전환율이 낮은 부분은 어디일까? 그 부분을 개선하기 위해서는 어떤 Action을 할 수 있을까? 어떤 실험을 진행하면 이에 대한 결론을 얻을 수 있을까?
- (Product) 새로운 기능 개발을 시작하려고 하는데, 이 기능 개발이 성공했다고 보려면 어떤 Metric을 결정해야 할까? 그 Metric을 보기 위해 어떤 앱, 웹 데이터를 로깅해야할까 새로운 기능을 AB Test 하려고 할 경우, 어떤 방법으로 설계할 수 있을까?
- (Product) 새로운 기능이 출시된 이후에 성공적인지 확인하기 위해 대시보드는 어떻게 구성해야 할까?
- 더 자세한 내용은 쏘카의 채용 노션 페이지를 참고하시면 좋을 것 같습니다.
다시 한번 강조 드리고 싶은 점은, Research Scientist / Applied Research Scientist / Machine Learning Engineer / Data Scientist로 나누어진 포지션이 절대적인 기준이 아니라는 것입니다. AI에 관련된 일들이 칼로 무 자르듯이 나누기 어렵기 때문에, 조직마다 수행하는 역할이 겹치기도 하고 한 포지션에서 여러 역할을 수행하는 경우도 많습니다. 각 조직이 풀고 있는 문제, 성향, 문화 등 여러 가지 요인이 작용하여 포지션을 구성하기 때문에, JD를 보실 때 참조하는 용도로 이 글을 읽으시는 것을 추천합니다.
쏘카 AI팀은 어떤 일을 할까?
쏘카의 AI 팀은 Human-Interactive AI System라는 목표 아래, Vision, NLP 기술을 활용해 카셰어링 서비스에서 발생하는 여러 문제를 해결하고 있습니다. “Human-Interactive”라는 말이 다소 생소하실 텐데요, 저희 팀이 정의한 Human-Interactive AI System 이란 End User(사람)의 피드백을 기반으로 지속적으로 성장하는 시스템으로, 현실에서 Robust 하게 동작하여 비즈니스 임팩트를 내는 AI 시스템을 뜻합니다.
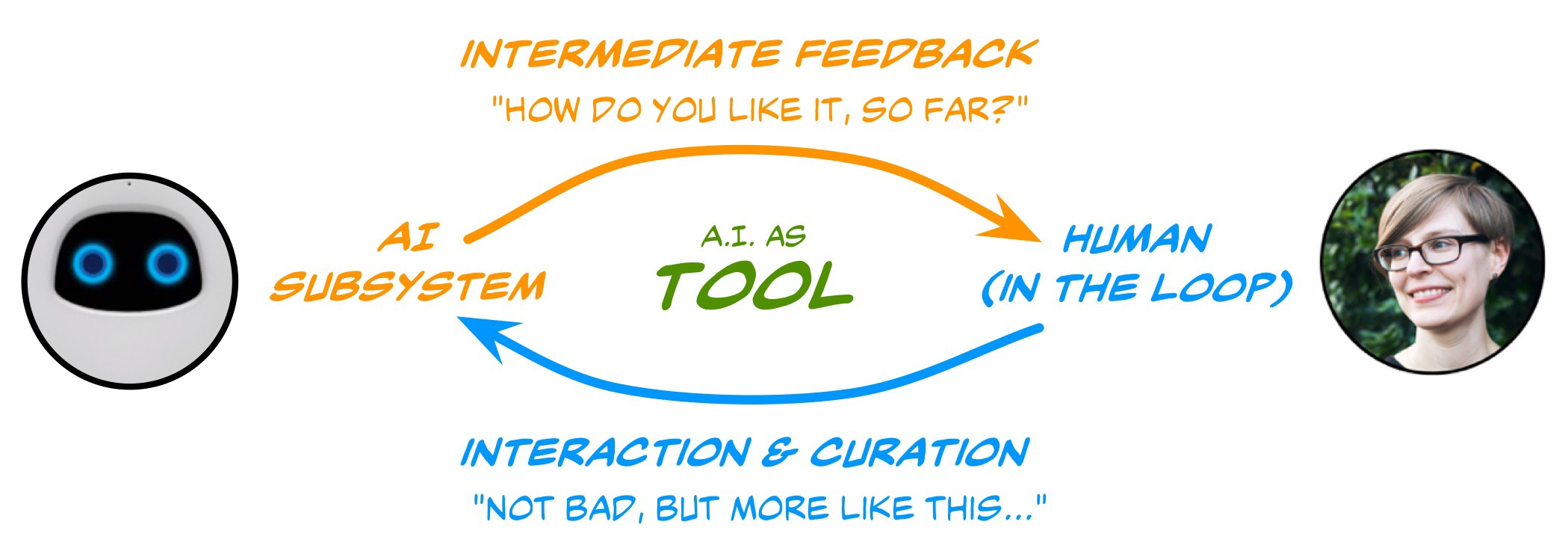 Human-Interactive AI(Human-In-The-Loop)
Human-Interactive AI(Human-In-The-Loop)
Vision Domain
현실에서 Robust 한 AI 시스템을 디자인하기 위해서는 많은 고민들이 필요합니다. 먼저 Vision 도메인에서 간단한 예를 들어보겠습니다.
경차와 중형차 이미지를 구분하는 이진 차종 분류 모델 (Binary Classifier)이 존재한다고 가정해 봅시다. 이진 분류기를 만드는 것은 간단합니다. DB에 쿼리를 날려 경차와 중형차 이미지를 수집하고, 레이블링을 수행하고, ResNet과 같은 Neural Network Architecture에 Cross Entropy Loss를 설정하여 분류 모델을 학습시키면 됩니다. 그러나 이 분류기가 현실에 배포되기 위해서는 더 깊고, 다양한 고민이 필요합니다.
 경차(왼쪽)와 SUV(오른쪽) 이미지 예시
경차(왼쪽)와 SUV(오른쪽) 이미지 예시
만약 분류기에 들어가는 Inference 이미지가 경차도, 중형 차도 아닌 경우에는 어떻게 해야 할까요? 자동차 사진이 아니라 음식 사진, 차종을 판단할 수 없는 사진, 심한 blur 등으로 식별할 수 없는 사진이 들어오면 어떻게 처리해야 할까요?
 차종 분류와 관련없는 이미지들 예시
차종 분류와 관련없는 이미지들 예시
모델이 풀고자 하는 Task에 관련 없는 이미지 (Out-of-Distribution sample)가 분류기에 들어오면, Supervised Learing 패러다임으로 학습된 분류기는 무조건 경차나 중형차 중에 하나로 판단을 내리게 됩니다. 즉, 불필요하고 잘못된 정보가 Inference 되어 End-User에게 전달됩니다. (고기 사진을 경차라고 판단하여 실무자에게 전달하는 것입니다!) 이러한 문제는 어떻게 해결할 수 있을까요? 사전에 경차나 중형 차에 속하지 않는다고 판단하면서 (Out-of-Distribution Detection), 기존 분류기의 성능을 유지할 수는 없을까요? (Open-Set Recognition)
다른 관점에서 차종 분류 모델을 살펴보겠습니다. CNN 기반의 분류 모델은 이미지가 들어왔을 때, 해당 이미지에 대한 예측의 Confidence를 갖습니다. 이 Confidence가 특정 이미지가 Class에 속할 Probability(확률)이라고 말할 수 있을까요? 일반적인 CNN들은 대부분의 판단에 대해 overly-confident 한 예측을 수행하는 Overconfidence Problem을 가지고 있습니다. 이때, 과도하게 높은 Confidence를 갖는 문제를 어떻게 해결할 수 있을까요? 잘못된 예측을 수행했을 때는 less-confident 하게 틀리고, 옳은 예측에 대해서는 more confident 하게 맞추도록 할 수는 없을까요? (Calibration) 실무에서는 모델의 예측 결과뿐만 아니라, 모델이 확실하게 예측한 건들을 먼저 검토하고자 하는데, 이 확신의 정도를 어떻게 잘 측정할 수 있을까요?
NLP Domain
AI 팀에서는 고객이 쏘카 이용 중 겪을 수 있는 문제를 빠르게 해결해 줄 수 있는 채팅 AI(Dialogue Sytem)를 연구하고 있습니다. 예를 들어, 고객이 겪는 문제 상황을 이해하기 위해 간단한 Intent Classifier가 있다고 가정해 보겠습니다. 고객의 여러 문제상황(Intent)들 중 “쏘카 존에 반납이 불가능해요”라는 Intent가 있을 때, 아래와 같은 고객의 문의들은 어떻게 처리할 수 있을까요?
- 1) “쏘카 존 입구가 어디에 있는지 몰라서 반납을 못하겠어요”
- 2) “쏘카 존이 침수되어 진입이 불가능해서 반납을 못할 것 같아요”
- 3) “차단기가 열리지 않아 쏘카 존에 들어갈 수 없어요. 어떻게 할까요?”
- 4) “기름이 떨어져서 차량이 중간에 멈췄어요. 쏘카 존에 반납을 못하겠어요.”
이 문의들은 공통적으로 “쏘카 존에 반납이 불가능하다”라고 생각할 수 있지만, 각 문의들은 모두 다른 Reply가 필요합니다.
- 1의 경우 쏘카 존 입구를 안내드려야 하고
- 2의 경우 인근 쏘카 존을 안내드려야 하고
- 3의 경우 쏘카 존 관리자와의 커뮤니케이션이 필요하며
- 4의 경우 긴급출동이 필요합니다.
고객이 필요로 하는 솔루션이 각기 다른데, 이 문의들을 하나의 Intent로 묶을 수 있을까요? 혹은 한 문장에 여러 가지 문제가 섞여있을 때는 어떻게 처리할 수 있을까요? (Multi-Labeled Sample) 뿐만 아니라, 사전에 정의해둔 Intent에서 벗어난 문의는 어떻게 응답해야 할까요? (Unknown Intent Detection) Vision 도메인에서와 마찬가지로, 고객의 문의에 대해 예측한 Intent에 대한 Confidence를 어떻게 측정할 수 있을까요?
마무리
쏘카의 AI 팀은 이러한 고민들을 해결하기 위해 여러 분야의 논문을 스터디하고 구현하며, 실무에 적용하고 있습니다. 과거 논문에서 제안된 기법을 이용하는 것뿐만 아니라, 비즈니스 도메인에서 최적의 성능을 달성하는 새로운 기법을 디자인하기도 합니다. 기술적인 문제를 해결한 후에는 다른 팀과 협업하며 현실에서 Business Impact을 달성합니다. 데이터 사이언스 팀과 협업하여 개발한 AI가 가져올 임팩트를 산정하기도 하고, 엔지니어링 그룹과 협업하여 모델을 배포하고, 모델의 예측 결과를 모니터링합니다. 모델을 실무에 적용하고 프로젝트의 한 Cycle을 완수한 이후, End-User의 피드백을 기반으로 모델을 성장시키고 있습니다 (Human-in-the-Loop).
앞으로 이어질 테크 블로그 글에서는 쏘카 AI 팀이 비즈니스의 문제를 해결한 Case들을 소개하고, Conference나 Journal에 Publish 한 저희 팀의 연구 실적에 대해서도 소개 드리고 자 합니다.
다음 글에서 뵙겠습니다. 긴 글 읽어주셔서 감사합니다!