 에스더
에스더안녕하세요 쏘카 데이터비즈니스 본부의 AI팀 에스더라고 합니다! 😎
저는 AI팀에서 Computer Vision 관련 다양한 Task와 연구를 하고 있습니다. 이번 글에서는 세차 인증 자동화 모델을 개발한 과정을 정리해보려고 합니다. 이 글을 끝까지 다 읽고 나면 현실에서 AI를 적용하여 비즈니스적인 임팩트를 내는 과정을 이해하실 수 있습니다.
목차
목차는 다음과 같습니다
- 세차 인증 자동화는 왜 해야 할까
- 세차를 위한 데이터 스킴을 어떻게 정할 수 있을까
- 모델 적용기
- 3.1. 분류 모델 실험 과정
- 3.2. Rejection 모델 개발
- 3.3. 실무 적용 위한 External Validation
- 이 글을 마치며
- 참고
1. 세차 인증 자동화는 왜 해야할까
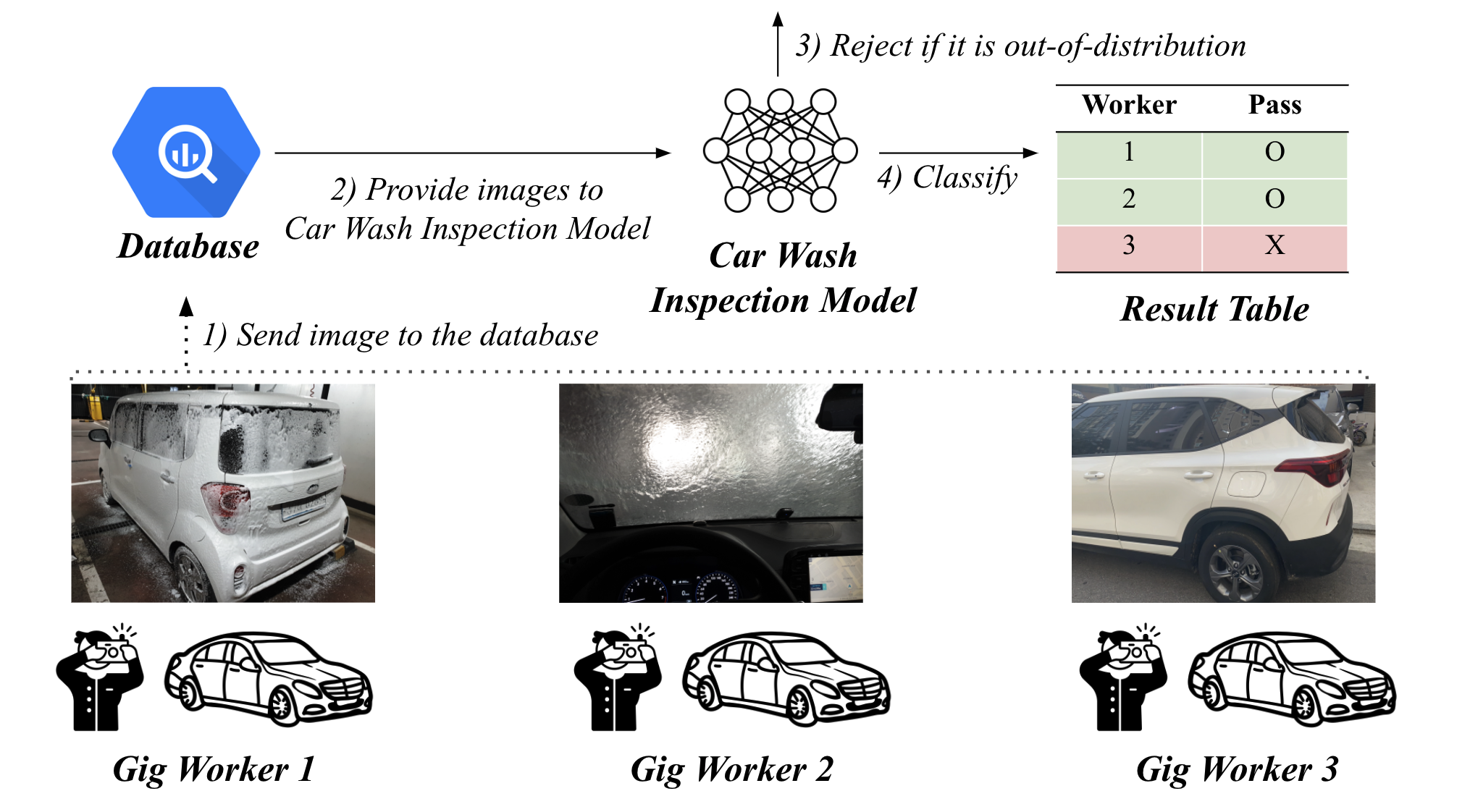
쏘카는 여러 유저가 쏘카의 차량을 공유하는 서비스입니다. 따라서 공유되는 차량을 주기적으로 세차해 주는 것이 중요한데, 이를 위해 반납 전 세차하는 고객에게 쏘카 크레딧을 제공하고 있습니다.
쏘카 크레딧이 제공되는 과정은 다음과 같습니다.
- 고객은 세차장을 방문하여 세차를 진행합니다.
- 세차가 완료되면, 세차를 수행했음을 인증할 수 있는 사진을 쏘카 앱에 업로드합니다.
- 쏘카 직원이 업로드된 사진을 검토한 뒤, 크레딧 지급 여부를 결정합니다.
하지만 서비스가 성장함에 따라 어느덧 쏘카 매니저분들이 한 달에 6,000건 이상 세차 사진을 보아야 하는 상황에 이르렀습니다. 매니저분들의 단순 작업이 가중되었고, 고객에게도 크레딧 지급 여부 결과를 빠르게 받기 어려운 문제가 생기게 되었습니다.
이에 쏘카 매니저분들을 대신하여 세차 인증을 해줄 딥러닝 모델을 만들게 되었습니다.
2. 세차를 위한 데이터 스킴을 어떻게 정할 수 있을까
딥러닝 관련 문제들을 풀다 보면, 중요한 것은 어떤 모델이나 프레임워크를 사용하는 것이 아니라 좋은 데이터를 사용하는 것임을 알 수 있습니다. 하지만 현실에서 수집되는 데이터는 우리가 생각하는 이상향과는 많이 다른 경우가 많습니다.
같은 뷰로 찍은 사진이라도 접사가 있을 수 있고, 너무 멀리서 찍어서 어떤 것을 말하고자 하는 것인지 모를 때도 있습니다. 혹은 지금 풀고자 하는 문제와 완전히 Distribution이 다른 데이터가 들어올 수도 있습니다. 이러다 보니, 비즈니스 문제 상황을 잘 표현하며 모델이 잘 학습할 수 있는 데이터 스킴을 만드는 작업이 매우 중요합니다.
데이터 스킴에는 각 Class마다 같은 Characteristic을 가진 데이터만이 속해있어야 합니다. 레이블러의 주관에 따라 달라질 수 있는 애매한 데이터들은 오히려 성능을 더 낮출 수도 있습니다. 따라서 전체 데이터 중에서 상대적으로 명확한 기준을 잡는 것은 매우 중요하지만 동시에 어려운 일이기도 합니다.
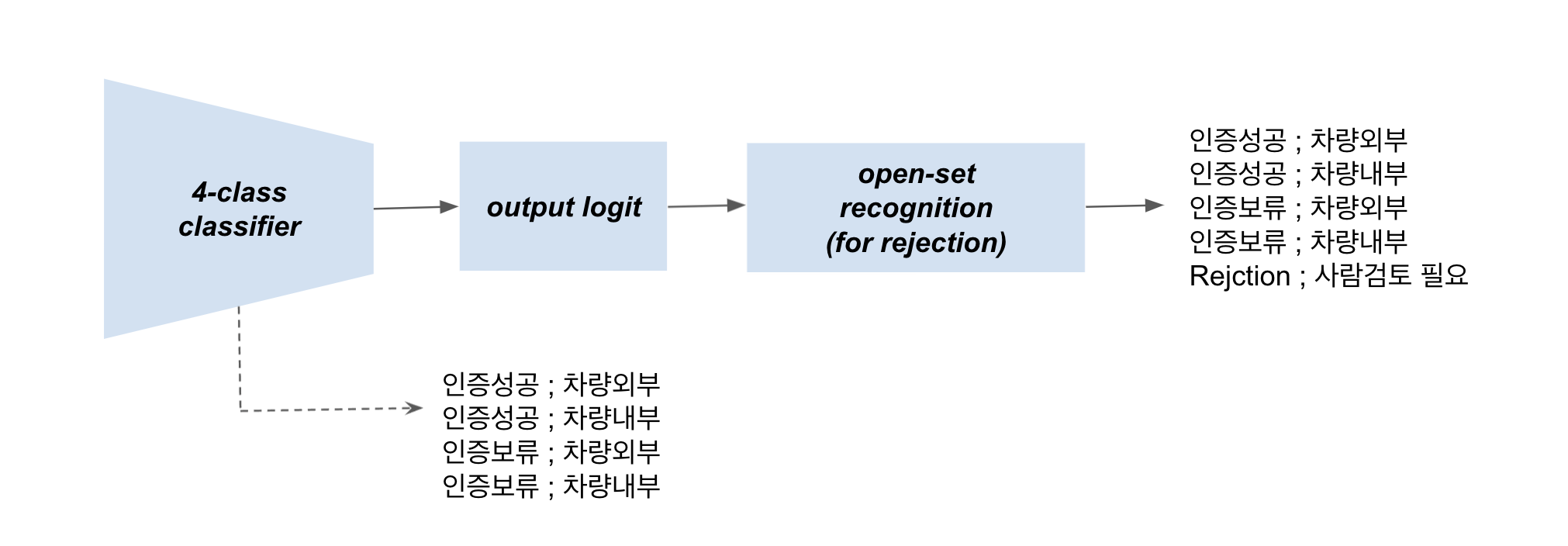
저희 데이터 모델링 팀에서는 2020-2021, 약 2년간 적재된 고객 수행 세차 건 이미지 데이터를 분석하여 세차 여부를 검토하는 4개의 패턴을 발견할 수 있었습니다. 이에 따라 세차 여부를 분류해 주는 모델을 만들고, 분류가 애매한 이미지들을 매니저의 검토가 필요하도록 별도로 Isolate(격리)해주는 모델을 설계했습니다.
분류 레이블은 크게 “인증 성공”과 “인증 보류” 2개로 나뉘고 구체적으로는 아래처럼 4개로 나뉩니다. 인증 성공과 보류로 거품이 묻어있는 외관이나 기계 세차장 내부에서 찍은 사진은 세차 인증으로 보고, 차량 외관만 찍은 사진이나 일반 차량 내부 사진들은 세차 인증 보류 클래스로 분류했습니다.
(1) 인증 성공 : 외부에서 촬영한 거품 묻은 차량 이미지
(2) 인증 성공 : 내부에서 촬영한 기계 세차중인 이미지
(3) 인증 보류 : 세차 완료된 깨끗한 차량 이미지
(4) 인증 보류 : 일반 차량 내부 이미지

아래처럼 명확한 분류 기준이 없는, 즉 사람이 검토해 줘야 할 애매한 경우에는 Rejection하도록 모델을 설계했습니다. 여기서 Rejection이란 4개의 분류 레이블 어느 것에도 속하지 않는 애매한 이미지가 들어올 경우, 완전히 다른 클래스인 Rejection 클래스로 분류하는 것을 의미합니다. 저희는 아래와 같이, 우리가 분류하고자 하는 스킴에서 벗어나는 데이터들을 Out-of-distribution 데이터라고 부르겠습니다.

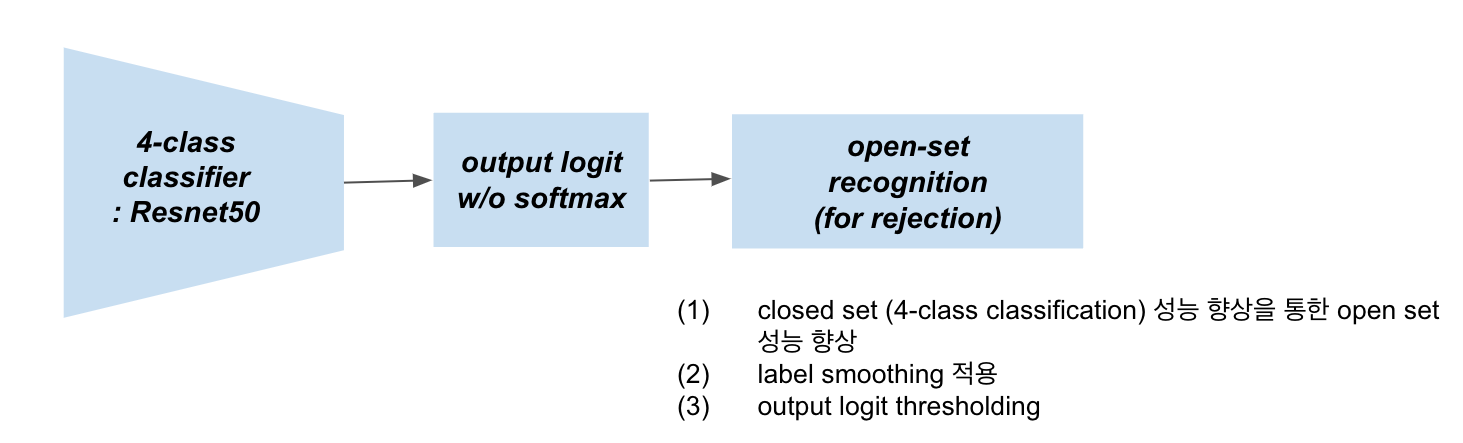
세차를 위해 잡은 전체적인 구조는 아래와 같습니다. 첫 번째로 Input으로 들어오는 데이터에 대해서 4-class Classification을 진행하고, 그 Output 값을 받아 Open-set Recognition을 적용하여 Rejection Class를 생성하는 형태로 보실 수 있습니다. 각 구조에 대한 자세한 설명은 3. 모델 적용기에서 자세한 다루겠습니다.
3. 모델 적용기
3.1. 모델 실험 과정
세차 인증 모델을 만들기 위해 저희는 2가지 방법으로 접근했습니다. 첫 번째 접근은 기본적인 Supervised Classifier 모델이었고, 두 번째 접근은 Image Retrieval 활용하는 방식이었습니다.
Image Retrieval은 간단하게 생각하면, Training set의 이미지 Feature 들을 데이터베이스에 저장해두고, 입력으로 들어오는 이미지와 가장 비슷한 이미지 k개를 뽑아주는 방식의 접근입니다. 이 방식은 Place Recognition이나 Map Matching에서 많이 활용하는 접근 방법입니다. 세차 인증 시에도 결국 비슷한 차량의 부분들을 다른 View로 사진을 찍어 올라오게 되는 형태이므로 비슷한 접근으로 풀 수 있을 것이라고 생각했습니다.
또 Inference 시에 Data-shift에 좀 더 유리할 것이라고도 생각했습니다. 예를 들어 “세차 기계 안에서 차 내부를 찍은 사진”과 “비가 많이 오는 날 차 내부를 찍은 사진”을 생각해 보면, 후자의 경우 Training Set에 없었다면 기본 분류 모델은 이 사진을 세차 완료로 잘못 분류할 수 있습니다. Image Retrieval로 이 문제를 풀게 되면 Feature Vector가 다르게 생성되기 때문에 다른 클래스로 분류하게 될 수 있을 거라고 생각했습니다.
저희는 Image Retrieval 모델 중에서 Place Recognition 문제에서 높은 성능을 보였던 NetVLAD 모델을 저희 데이터에 맞게 변형하여 사용했고 Classification 모델로는 Resnet50을 사용했습니다.
그리고 실험 결과는 다음과 같았습니다.
| NetVLAD | NetVLAD (w. self-supervision) | Supervised Classifier | Supervised Classifier (w. self-supervision) | |
|---|---|---|---|---|
| test set acc | 0.8694 | 0.8444 | 0.9583 | 0.9555 |
| test set precision | 0.8773 | 0.8604 | 0.9608 | 0.9565 |
| test set recall | 0.8759 | 0.8548 | 0.9576 | 0.9550 |
| test set f1-score | 0.8740 | 0.8556 | 0.9591 | 0.9557 |
이 실험을 통해 저희는 Imagenet Pretrained Supervised Classifier를 Baseline으로 사용하기로 결정했고, 2가지 Takeaway도 같이 정리해 볼 수 있었습니다.
(1) Retrieval 보다 Supervised Classifier 사용했을 때가 성능이 더 좋다
- 대부분 Retrieval로 푸는 문제들을 보면 공통된 픽셀 값을 가지는 곳, 즉 이미지 내에서 같은 객체가 있는 곳을 Landmark로 보고 같은 곳이라고 판단해 이 부분들을 매칭하는 방식을 사용합니다.
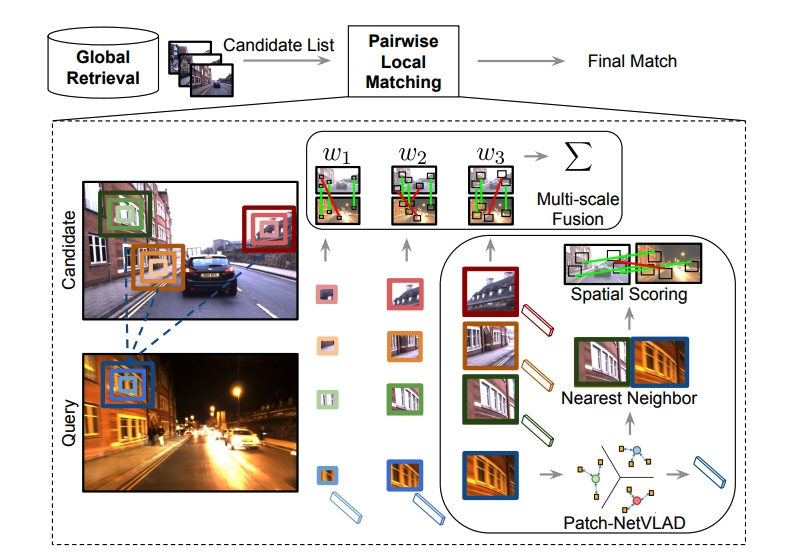 Patch Net-VLAD에서 비슷한 Object가 있는 부분을 보고, 같은 Place라고 예측하는 이미지
Patch Net-VLAD에서 비슷한 Object가 있는 부분을 보고, 같은 Place라고 예측하는 이미지
- 하지만 저희가 사용하는 사진의 경우는 같은 Class 내에서 같은 Object를 공유하는 형태가 아닙니다. 아래 사진과 같이 같은 “세차 보류 : 차량 내부” 사진이라도 핸들이 등장하는 경우도 있고 차량 시트 쪽이 등장하는 경우도 있기 때문에 Feature Space 상에서 유사하다고 판별하기 어려웠습니다. 따라서 Motivation은 괜찮았지만 데이터 특성상 좋은 성능을 내기 힘들었습니다.

(2) Self-Supervised Learning 보다 Imagenet-pretrained Weight을 사용했을때 성능이 더 좋다
- 저희는 Upstream Weight을 설계할 때 Self-Supervised Weight을 사용하는 경우와 Imagenet-pretrained weight을 사용하는 경우의 두 가지 성능도 같이 비교해 보았습니다
- 일반적으로 Domain Specific한 형태의 이미지에서는 Self-Supervision을 사용한 성능이 더 좋아야 했지만, 저희는 그렇지 않았습니다. 그 이유는 Self-Supervised Learning을 학습한 데이터에 있었습니다
- Self-Supervision Weight의 Training 데이터로 차종 분류 문제를 풀 때 사용했던 이미지를 사용했고, 해당 문제를 풀 때 좋은 성능을 냈던 Weight을 가져와서 사용했습니다. 하지만 세차 인증을 위해서는 “깨끗한 외부 사진” 뿐만 아니라 “거품이 있는 외관”과 같은 Fine-grained 한 특징까지 알아야 하므로 해당 Weight으로는 좋은 성능을 내지 못했습니다.
- 더 좋은 성능을 내고자 했다면, 우리가 지금 풀고자 하는 Fine-grained 한 문제를 푸는 도메인을 잘 이해하고 있는 모델로 Self-Supervised Learning 모델을 학습한 Weight을 사용했었어야 합니다.
3.2. Rejection 모델 개발
이제 Baseline Classifier를 다 만들었다면, Inference 시에 들어오는 Out-of-distribution 데이터, 즉 저희가 Classification 스킴 이외의 데이터가 들어온다면 이를 어떤 클래스로도 포함하지 않고 reject 하여 담당 매니저에게 검수를 요청하기 위한 모델을 개발해야 합니다.
예를 들어, 세차 인증을 위해 고객분들이 영수증을 찍어 업로드하시는 경우가 생각보다 많습니다. 이를 모델로 판단하기 위해서는 OCR로 영수증으로부터 텍스트를 읽어내고 다시 판단하는 과정을 거쳐야 하지만, 일단 지금 단계에서는 Out-of-distribution으로 판단하고, Reject 한 이후에 담당 매니저에게 검토를 요청하는 방식을 취하기로 결정했습니다.
Rejection으로 들어가는 이미지는 다음과 같습니다. 영수증 사진이라 사람이 봐도 (세차 여부를 판단하기) 애매한 사진들 혹은 세차장 내부에서 찍은 사진인 것 같으나 역시나 애매한 사진들에 해당됩니다.

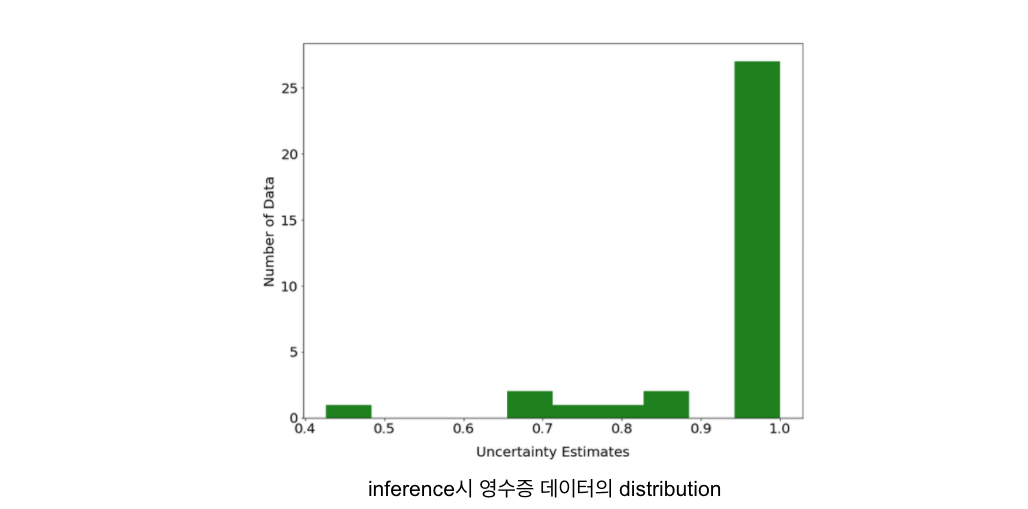
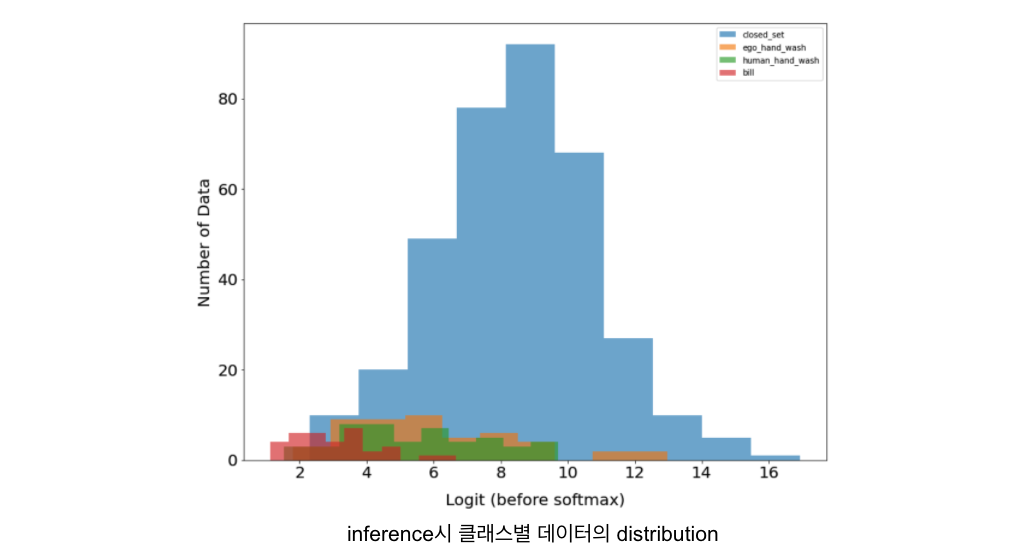
이번에도 저희는 두 가지 접근 방법을 사용했는데요, 첫 번째 방법은 모델 Output의 Certainty를 활용하여 Threahold로 Out-of-distribution 데이터를 골라내는 방식이고, 두 번째 방법은 Open-set Recognition 접근 방법을 사용했습니다. 우선 첫 번째 방법으로 inference된 영수증 데이터들의 distribution을 확인해 본 그림은 아래와 같습니다. 아주 높은 Certainty로 다른 In-of-distribution으로 예측하고 있으므로 이 데이터를 Threaholding으로 Reject 하기는 매우 어려워 보입니다. 이뿐만 아니라, 다른 애매한 사진들, 즉 사람의 판단이 필요한 데이터들이 들어왔을 때도 Calibration Problem 때문에 높은 Certainty로 다른 클래스로 분류해버리는 문제가 생겼습니다.
따라서 두 번째 방법인 Open-set Recognition으로 넘어가게 되었는데요, 이 방법의 접근 방법을 다음처럼 크게 두 가지로 떠올려볼 수 있는데요,
- 모델의 Output Logit 값을 이용해서 판단하는 방식
- Generative Model을 활용하여 Reject 될 만한 Out-of-distribution을 일부러 만들어 이를 분류하는 모델을 추가적으로 개발하는 방식
저희는 좀 더 직관적이고 컴퓨팅 리소스가 덜 소모되는 1번 방법을 사용하기로 했습니다. 또 SOTA로 분류되는 OpenHybrid, PROPOSER보다 더 간단하고 결과적으로도 더 좋은 “Simple and Effective”한 논문인 open set reocognition : a good closed-set classifier is all you need를 참고하여 저희 상황에 맞게 변형하여 실험 옵션을 구성해 보고자 했습니다.
- 첫 번째 실험에서의 Calibration 문제를 해결하고자 Label Smoothing의 Parameter를 조정해가면서 실험했고
- Softmax 전의 Logit 값을 사용하여 Thresholding 하는 실험을 진행했습니다.
아래의 그림을 확인해 보면, 이 실험을 통해 어느 정도 Bill, 즉 Out-of-distribution으로 가장 대표적인 영수증 데이터가 Thresholding으로 94% 정도 필터링 될 수 있음을 확인했습니다. 영수증 이외에 Out-of-distribution으로 분류되는 다른 두 클래스의 경우(=Human-hand-wash, Ego-hand-wash)는 제대로 Thresholding은 되지 않았지만, “사람이 직관적으로 판단하기에” 제대로 된 Class에 분류되는 것을 확인했기에 큰 문제가 되지 않고 Rejection 모델을 만들 수 있었습니다.
아래는 저희가 최종적으로 적용한 전체 구조입니다.
3.3. 실무 적용 위한 External Validation
모델의 최종 성능은 accuracy 기준 98%를 달성했습니다.
마지막으로 실제 운영팀에서 세차 인증을 진행하는 단위로 External Validation을 수행해보았습니다.
- 한 고객당 평균 3장의 이미지를 업로드 (=하나의 예약 건)
- 예약 건별로 세차 인증일지, 보류 혹은 Rejection 예측
각 예약 건별로 한 장이라도 세차 인증 이미지가 들어있다면 해당 건은 세차 인증으로 분류했고, 전부 세차 보류라면 세차 보류로 분류했습니다. 또 Rejection으로 예측되는 이미지와 세차 보류의 이미지가 섞인 예약 건은 사람이 검수해 줄 수 있는 Rejection 클래스로 분류했습니다. 그리고 각 클래스마다의 Precision을 확인해 보았습니다.
모델이 “인증 성공”으로 분류한 건들의 97%는 실제로 사람도 인증을 해주고 있었습니다. 나머지 3%의 경우, 직접 이미지들을 확인해 보니, 월 3회 이상 세차 인증을 수행하여 쏘카 정책상 크레딧 지급이 불가능한 건들이었습니다. 즉 모델은 정확하게 판단했으나, 운영 정책상 사람이 인증해 주지 않은 부분이었기 때문에, 모델은 충분히 제 역할을 해주고 있다고 생각했습니다.
또 모델이 “인증 보류”로 분류한 건들의 72%는 실제로 사람도 인증 보류를 해주고 있었습니다. 나머지 28%의 경우는, 아래 사진처럼 운영 정책상으로는 맞지 않지만 인간의 시각으로 봤을 때 사람마다 다를 수 있었습니다. 즉, 매니저 재량에 따라 달라지는 부분이었습니다. 이외에 모델이 판단하기에 애매한 사진들 즉 영수증 사진, 세차장 직원과 함께 찍힌 차량 사진 등은 사람이 검토할 수 있도록 Rejection이 잘 되는 것까지 확인할 수 있었습니다.
4. 이 글을 마치며
이렇게 회사 구성원분들의 단순 작업을 효율적으로 줄이면서도 고객에게 빠른 세차 피드백을 제공하기 위한 세차 모델의 첫 번째 모델을 마무리하게 되었습니다. 실제로 다양한 데이터를 보면서 Data-centric AI가 정말 현업에서는 중요하게 작용한다는 것을 다시 한번 느끼게 되었고 또 다양한 접근 방식을 통해 성능이 개선되는 과정을 통해 저 또한 많이 성장했던 것 같습니다.
이제 실제로 도입하여 사용하는 분들의 피드백을 받아볼 예정이고, 이를 통해 모델 개선을 해볼 예정입니다. 이후 모델을 개선하는 과정은 추가 글로 공유드리겠습니다.
만약 AI팀에 관심이 생기셨다면 쏘카 AI팀의 Applied Research Scientist는 어떤 일을 하나요? 글을 참고해주세요 :)
5. 참고
- NetVLAD : https://arxiv.org/abs/1511.07247
- Patch NetVLAD : https://arxiv.org/abs/2103.01486
- Open-Set Recognition : good closed set is all you need : https://arxiv.org/abs/2110.06207