 디니
디니안녕하세요. 데이터 플랫폼 팀의 디니입니다.
여러분 혹시 도서관에서 가서 책을 찾아보신 경험이 있으신가요? 방대한 도서관에서 원하는 책을 찾으려면 책의 제목, 저자, 분류 기호 같은 정보가 매우 중요합니다. 이런 정보가 없다면 책을 찾기가 많이 힘들어질 겁니다.
데이터 분석, 머신러닝을 위해 회사의 데이터베이스에서 원하는 데이터를 찾으려고 할때도 비슷한 일이 발생합니다. 어느 데이터가 어디에 있는지, 이 데이터는 무슨 의미인지에 대한 안내가 없으면 데이터를 이용하기가 불편할 것입니다. 이런 문제를 해결하기 위해 데이터의 위치와 의미를 한눈에 보게 돕는 플랫폼이 “데이터 디스커버리 플랫폼”(DDP, Data Discovery Platform)입니다.
앞으로 3부에 걸쳐 쏘카의 데이터 디스커버리 플랫폼 도입기를 소개하려고 합니다. 그중 1부인 이 글에서는 데이터 디스커버리의 개념과 데이터 디스커버리 플랫폼은 왜 필요한지, 쏘카는 어떤 기준으로 데이터 디스커버리 플랫폼을 선택했는지를 담으려고 합니다. 다음과 같은 분들이 읽으시면 도움이 되리라고 생각합니다.
- 사내 데이터 디스커버리 플랫폼 도입에 관심이 있는 분
- Datahub, Amundsen 등의 데이터 디스커버리 플랫폼을 PoC 하고 있는 개발자
- 쏘카가 데이터 디스커버리 및 메타데이터 관리를 어떻게 하고 있는지 궁금하신 분
목차는 이렇습니다. 각 제목을 클릭하시면 해당 부분으로 이동합니다.
- 데이터 디스커버리란 무엇인가요?
- 데이터 디스커버리 플랫폼이 왜 필요한가요?
- 데이터 디스커버리 플랫폼 비교 분석 : Datahub VS Amundsen
- 최종 결정 : Datahub 결정 이유
- 마무리 & 다음 편 예고
1. 데이터 디스커버리란 무엇인가요?
데이터 디스커버리의 정의
데이터 디스커버리(Data Discovery)란, “원하는 데이터를 쉽고 빠르게 찾을 수 있다” 의 개념입니다. 빅데이터 시대라는 흐름에 맞게, 회사에도 많은 양의 데이터가 여러 형태로 존재하게 되었습니다. 그리고 많은 사람이 데이터를 생산 및 소비하고 시간이 지나게 되면서 히스토리 파악도 점점 복잡해지기 시작합니다. 이런 상황에서 데이터 디스커버리는 데이터 이용자에게 “어떤 데이터”가 “어디에” “어떻게 존재”하는지에 대한 정보를 편리하게 제공합니다.
이런 데이터 디스커버리에는 “메타데이터”라는 개념이 중요합니다. 메타데이터는 간단히 말해서 테이블 정보, 컬럼 정보, 코멘트, 테이블을 만든 사람(오너), 테이블 사이의 관계(데이터 리니지) 등을 말합니다. 이러한 메타데이터를 잘 관리하는 것이 데이터 디스커버리의 핵심 역할입니다.
데이터 디스커버리의 중요성
데이터를 적극적으로 활용하는 기업은 데이터 디스커버리의 존재에 따라 업무 효율성이 크게 달라집니다. 사내에 많은 직원들이 데이터를 활용해 데이터 분석, 머신러닝, 데이터 기반 기획 등을 하고 있습니다. 각자의 목적에 맞는 데이터가 “어디에 있는지”, “이 데이터가 어떤 의미인지”를 파악하는 데에 대부분의 시간을 소요하게 된다면, 업무 효율성이 매우 떨어지게 될 겁니다.
데이터 디스커버리를 도입하여 잘 관리한다면 이런 비효율성을 피할 수 있습니다.
데이터 디스커버리 플랫폼의 정의
데이터 디스커버리를 가능하게 하는 플랫폼입니다. 웹 UI 환경을 제공하며, 데이터의 구조와 관계 등 메타데이터를 한 곳에서 쉽게 보고 검색할 수 있습니다(같은 이유로 데이터 디스커버리는 메타데이터 플랫폼이라는 용어로 쓰이기도 합니다) 대표적인 데이터 디스커버리 프레임워크는 다음과 같습니다.
2. 데이터 디스커버리 플랫폼이 왜 필요한가요?
도입 효과 - Data Discovery의 관점
쏘카에서는 데이터 분석가, PM, 마케터 등 여러 직군이 업무에 데이터를 활용합니다. 하지만 데이터가 다양한 형식으로 존재하고 비개발 직군 입장에서는 DB에 직접 접근하는 것도 어려움이 있습니다. 기존에 스키마에 대한 정보를 알려주는 어드민이 있었지만, 유지보수가 되고 있지 않았습니다. 이런 이유로 “어떤 데이터를 어디서 찾아야 하는지” 혹은 “이 테이블의 데이터가 어떤 의미인지” 에 대한 질문을 기존에는 슬랙 채널을 이용해 받곤 했습니다. 이런 방식은 히스토리 파악도 쉽지 않고, 답변하는 사람의 시간을 많이 사용하게 됩니다.
 데이터의 의미를 찾아 헤매는 브라운
데이터의 의미를 찾아 헤매는 브라운
 데이터의 의미를 찾아 헤매는 정
데이터의 의미를 찾아 헤매는 정
데이터 디스커버리 플랫폼을 도입하면 개발에 대한 도메인이 없더라도 간편한 UI를 통해서 메타데이터를 확인할 수 있습니다.
도입 효과 - Data Governance의 관점
데이터 거버넌스란 데이터를 효과적으로 관리하기 위한 일련의 보안, 품질, 규정 등과 관련된 체계를 말합니다. 여러 사람이 데이터를 생산하고 소비할 수록 데이터 거버넌스의 관점은 중요해집니다. 데이터 디스커버리 플랫폼을 도입하면 기존에 흩어져서 관리되던 테이블 스키마, 코멘트가 중앙 관리될 수 있습니다.
이러한 여러 이유들 때문에 쏘카는 데이터 디스커버리 플랫폼을 도입하기로 결정했습니다.
3. 데이터 디스커버리 플랫폼 비교 분석 : Datahub vs Amundsen
PoC 과정 소개
디스커버리 플랫폼을 선정하기 전, 공식 문서 등의 지원이 풍부하고 일반적으로 많이 쓰이는 Datahub와 Amundsen을 직접 배포하고 테스트하며 비교하는 PoC 과정을 거쳐보기로 했습니다.
사용성, UI, 문서화, 권한, 인증 등 다양한 측면에서 비교해 보았는데, 이 글에서는 그중 중요한 콘셉트를 간추려서 소개해 보겠습니다.
Datahub VS Amundsen 비교 분석
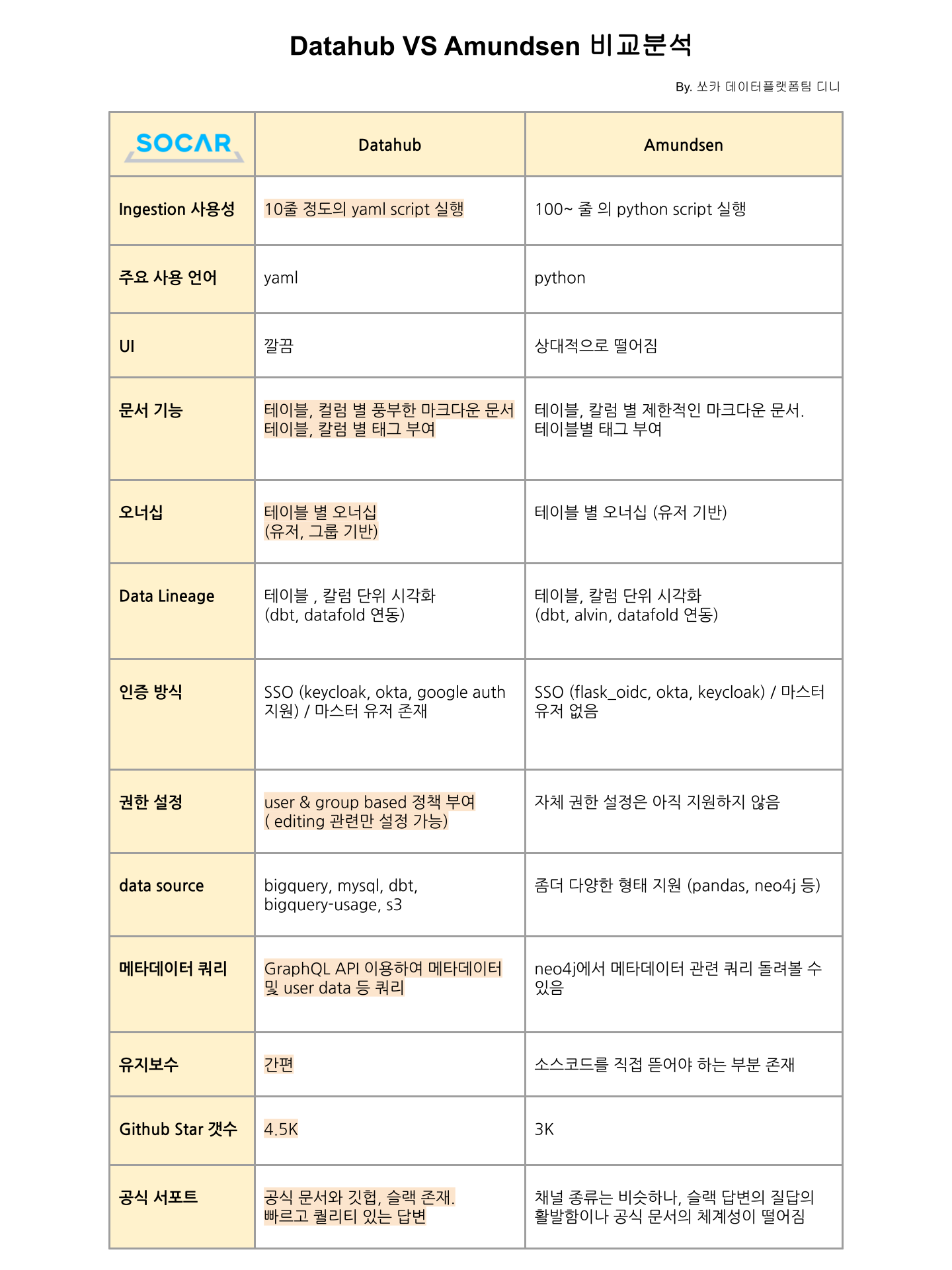
1) 구조
두 플랫폼의 구조에는 다음과 같은 공통점이 있습니다.
- React 기반 Frontend
- Elasticsearch 기반 Search Engine
- Neo4j 기반 Graph DB
- MySql 기반 Storage
차이점은 Datahub는 데이터를 주입할때 Kafka를 사용하고 Amundsen은 ETL 라이브러리를 통한 크롤링 방식을 사용하는 점입니다. 메타데이터 플랫폼 프레임워크의 히스토리를 살펴봤을 때, Amundsen 은 Monolith 방식인 반면 Datahub는 Event-based 방식입니다. 메타데이터 플랫폼의 히스토리에 대해서 좀더 궁금하신 분들은, LinkedIn의 엔지니어링 블로그에 작성된 DataHub: Popular metadata architectures explained 글을 보시는 것을 추천합니다.
2) 메타데이터 주입 방식
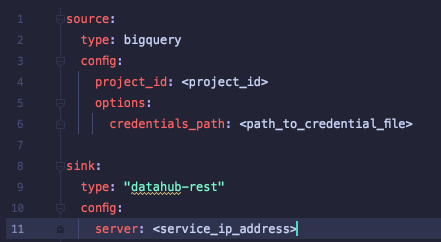
- Datahub는
yaml파일을 실행하여 메타데이터를 주입합니다.datahub CLI를 이용하여 yaml 파일을 실행합니다.- 연결하는 데이터 소스에 따라 Datahub 라이브러리에 따라오는 연결 플러그인 설치가 필요합니다.
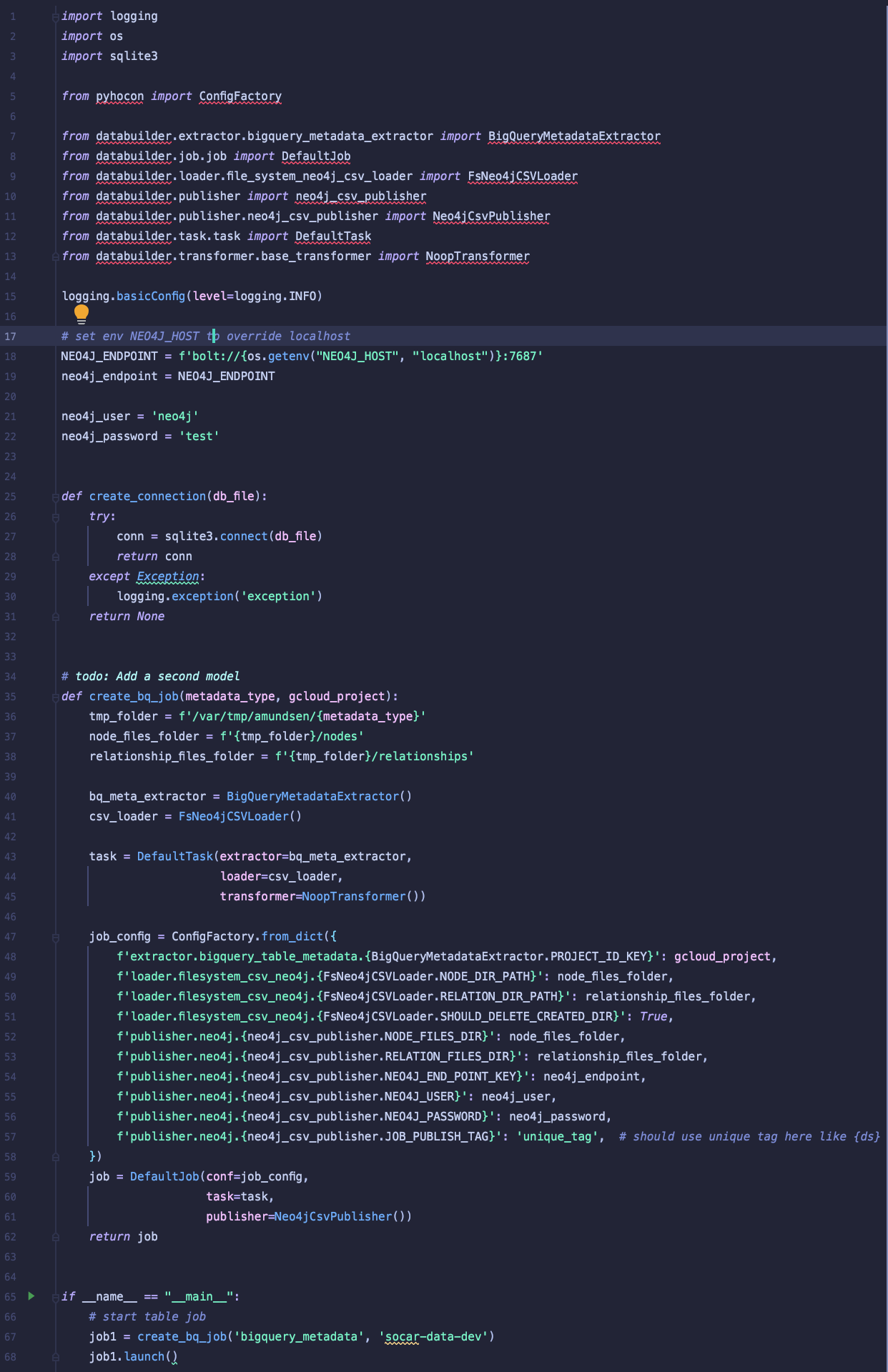
- Amundsen은
python파일을 실행하여 메타데이터를 주입합니다.- 기본적으로
amundsen databuilder라는 Python 라이브러리 (ETL framework) 를 사용하며, Extract, Transform, Load 각 과정에 여러 자체 모듈을 끌어와서 사용하는 방식입니다. - 이 외에도 종종 여러 디펜던시(Dependancy)가 필요했습니다.
- 기본적으로
 |
 |
|---|---|
| Datahub - BigQuery 데이터 주입 script | Amundsen - BigQuery 데이터 주입 script |
흥미로운 점은 같은 기능을 수행할 때 Datahub와 Amundsen의 script 길이 차이였습니다. Datahub는 10줄 내외의 직관적인 yaml 코드로 가능한 반면, Amundsen의 script는 기본적으로 50 줄 이상이었습니다. 개인적으로 스크립트가 긴 만큼 섬세한 커스텀이 가능하거나 필요하다는 생각은 들지 않았고 오히려 읽기 무겁다는 생각이 들었습니다(공식 깃헙에 있는 샘플이 400줄이었습니다)
각 ingestion 소스코드는 Datahub 공식 Github Repository 와 Amundsen 공식 Repository 에서 좀더 자세히 확인할 수 있습니다.
3) UI
개인 차가 있을 수 있으나, 팀원들의 의견으로는 Datahub가 훨씬 깔끔하고 보기 편하다는 의견이 많았습니다. Datahub UI는 공식 데모 사이트에서 더 확인하실 수 있습니다. (Amundsen은 따로 데모 사이트를 제공하지 않습니다)
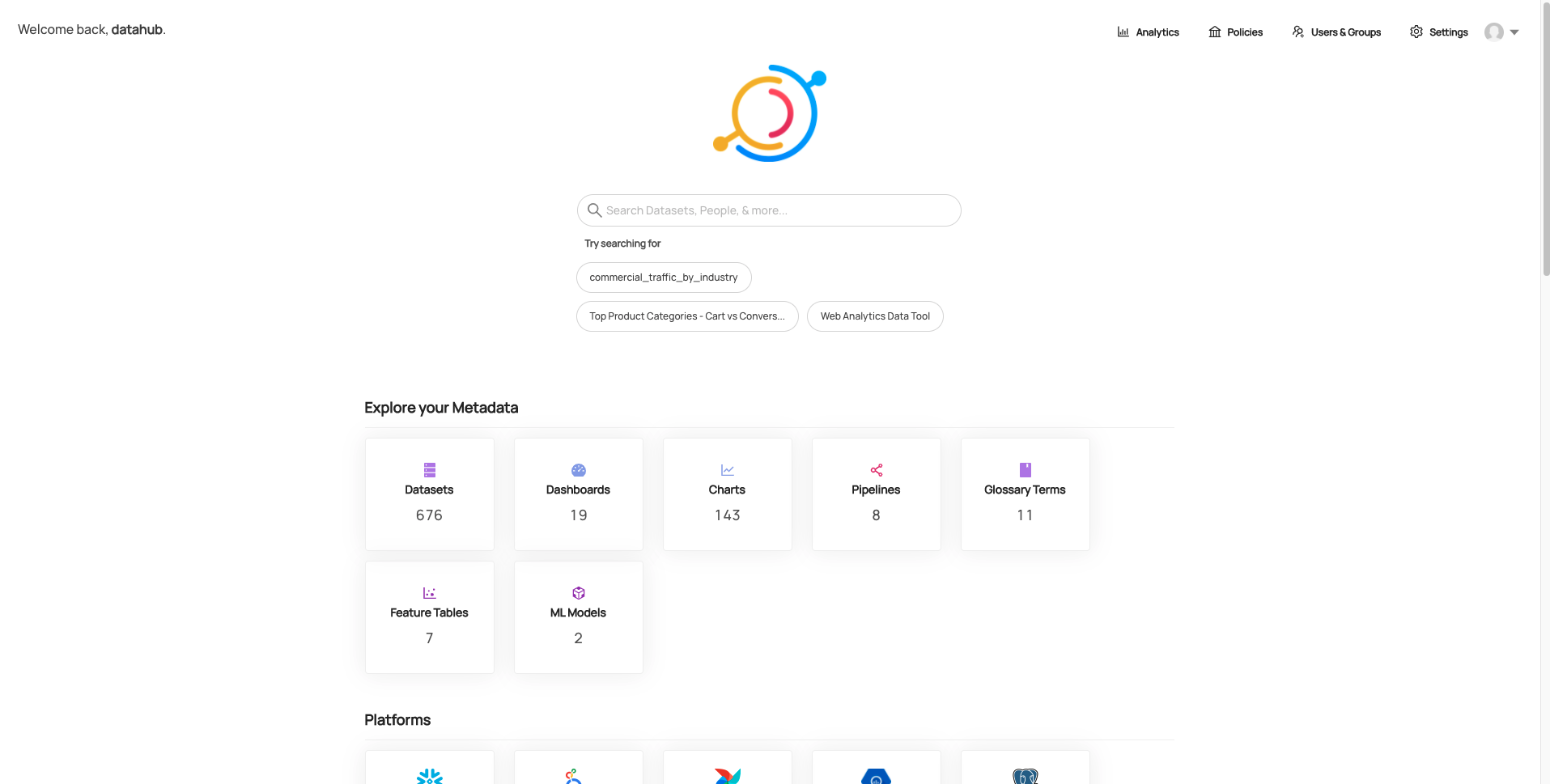 Datahub - 메인 UI
Datahub - 메인 UI
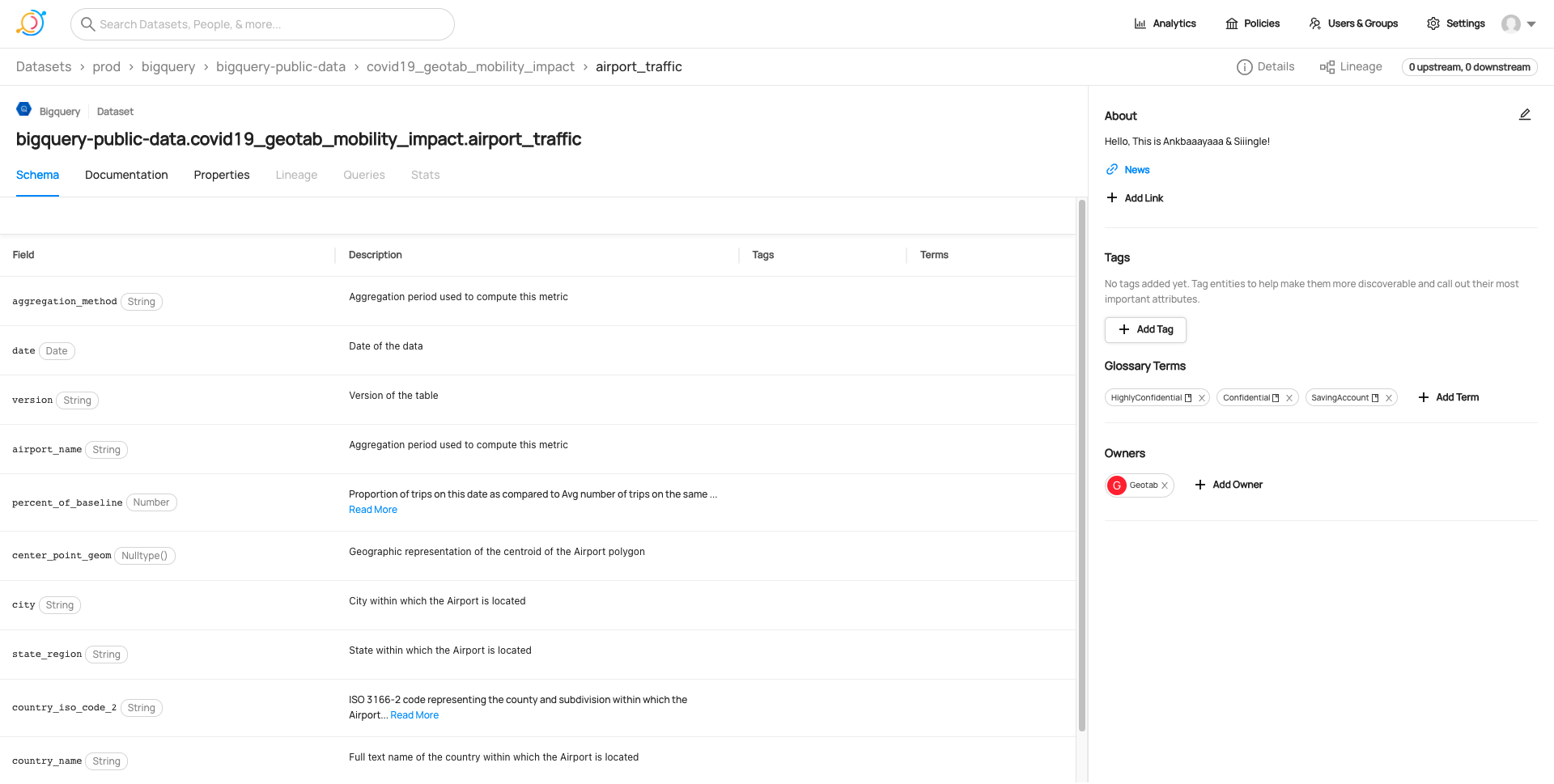 Datahub - 상세 UI
Datahub - 상세 UI
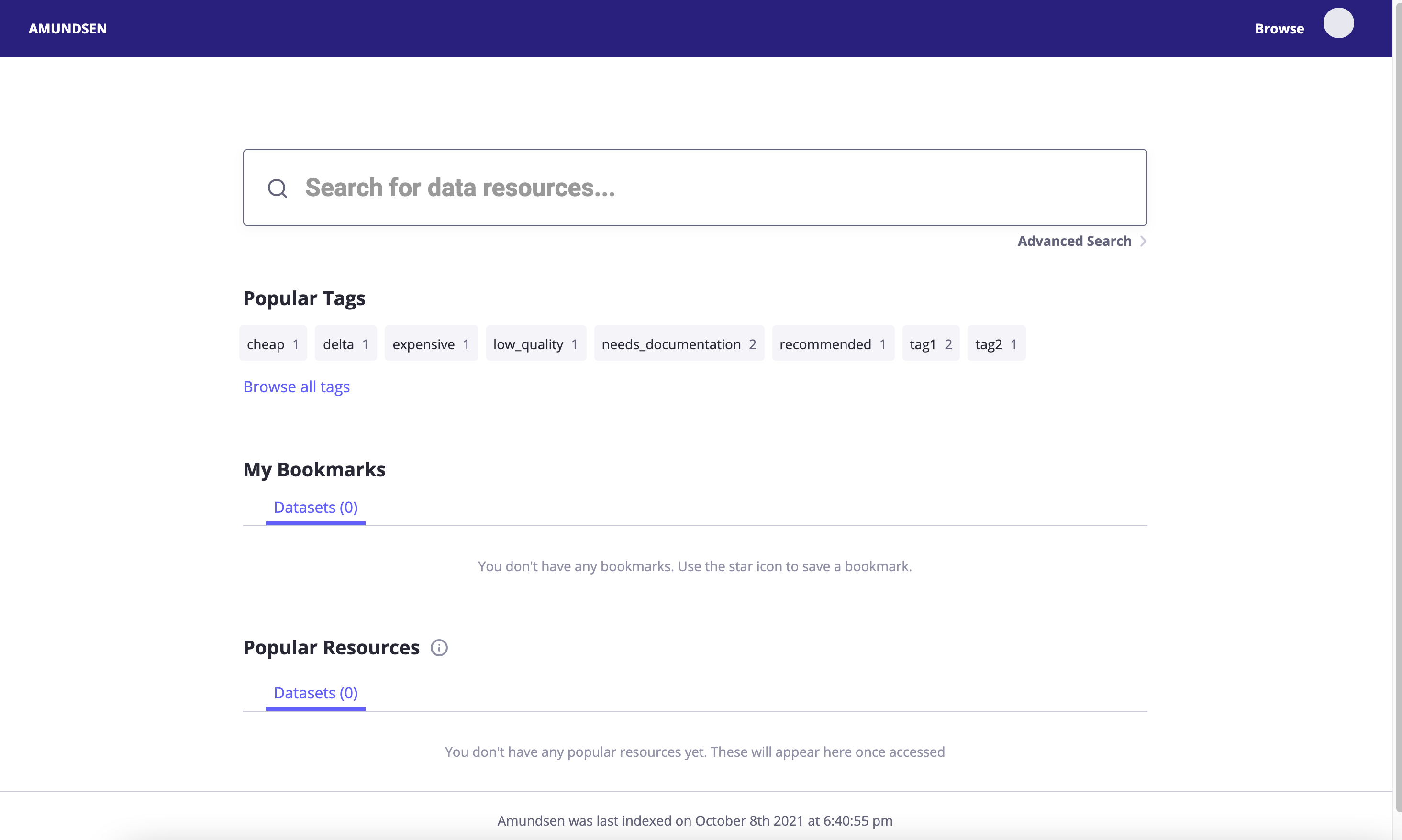 Amundsen - 메인 UI
Amundsen - 메인 UI
Amundsen - 상세 UI
4) 문서 기능
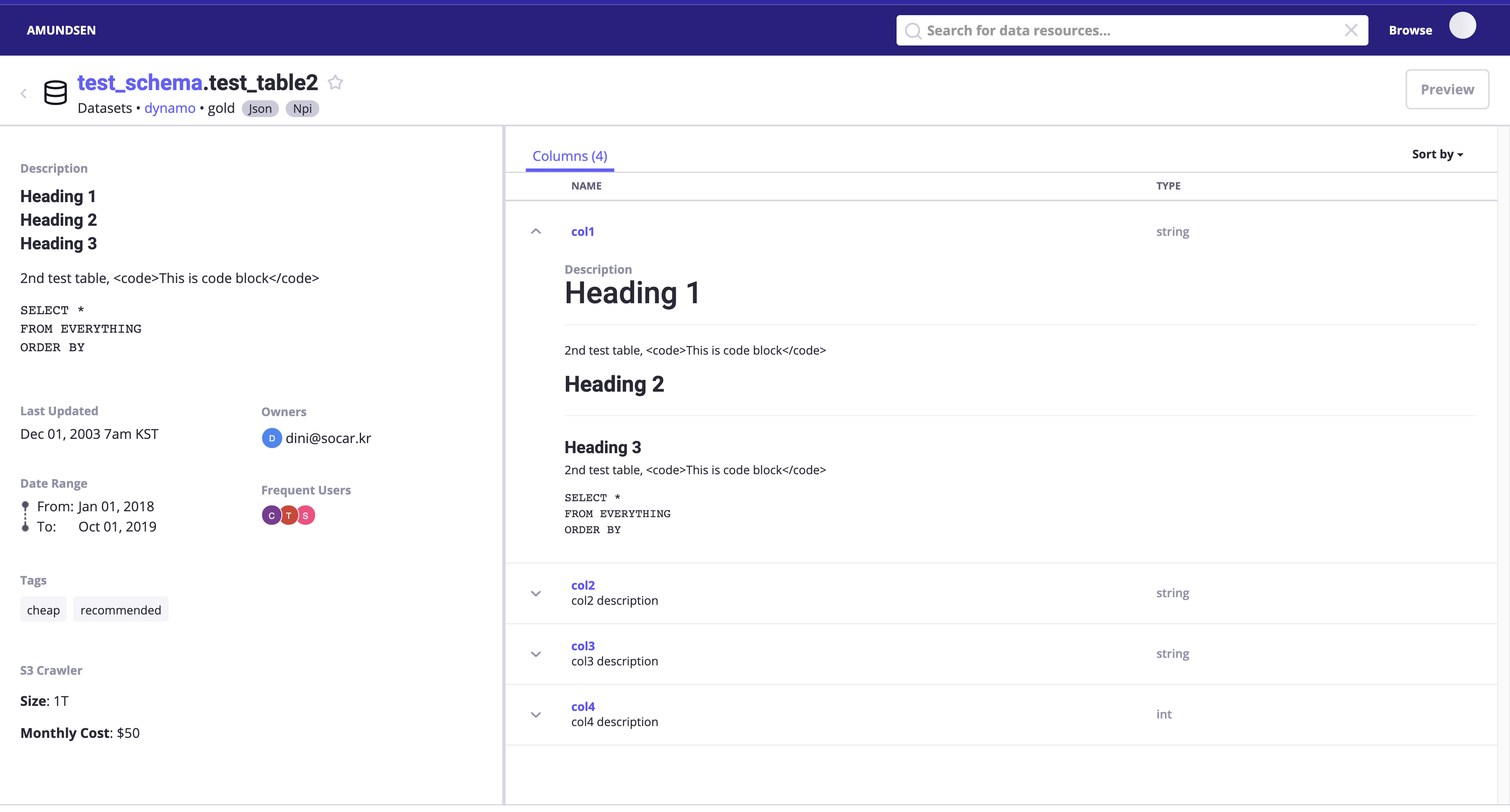
- Datahub
- 테이블 별 / 컬럼 별 태그 부여가 가능합니다.
- 테이블 별 / 컬럼 별 풍부한 마크다운 문서 작성이 가능하고, 원본 소스의 Description을 보존합니다.
- Amundsen
- 테이블 별 태그 부여가 가능합니다.
- 역시 테이블 별 / 컬럼 별 마크다운 제한적인 문서 작성이 가능하고, 원본 소스의 Description을 보존하지 않습니다.
중요한 점은 플랫폼 UI 상에서 테이블 혹은 컬럼의 설명을 수정했을 때 원본 소스의 Description을 따로 확인할 수 있는지의 여부였습니다. Datahub는 다음과 같은 방식으로 Original Description을 동시에 보여주지만, Amundsen은 이런 기능이 없습니다. 또한 Datahub는 원본 Description과 UI 상 Description이 별개로 버전 관리가 되고 있어서, 한쪽의 수정이 다른 쪽에 영향을 끼치지 않았습니다.
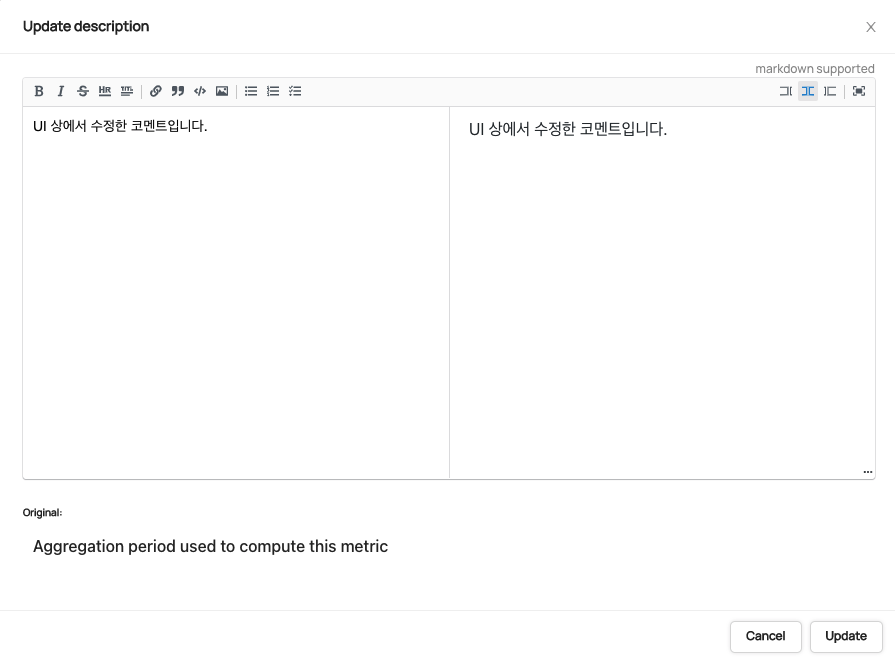 Datahub - UI 상에서 수정하더라도 “Original”(원본 코멘트)이 함께 표기됩니다.
Datahub - UI 상에서 수정하더라도 “Original”(원본 코멘트)이 함께 표기됩니다.
5) 오너십
- Datahub는 테이블에 유저 / 그룹 단위로 오너십을 지정할 수 있습니다.
- Amundsen은 테이블에 유저 단위로만 오너십을 지정할 수 있습니다.
6) 데이터 계보(Data Lineage)
데이터 계보(Data Lineage)란 데이터의 흐름을 시각화한 개념으로 특정 테이블이 어떤 테이블들을 참조하는지, 데이터가 어디에서 와서 어디로 흘러가는지를 편리하게 알 수 있습니다.
Datahub와 Amundsen 모두 dbt* 등을 연동하여 데이터 계보를 시각화 할 수 있습니다. (최근에는 Datahub에 dbt 없이 BigQuery 자체에서도 데이터 계보를 가져오는 기능이 추가되었습니다)
*dbt : 데이터 ETL 과정에서 T(Transform) 과정을 효율화하는 도구입니다. dbt 를 이용하면 SQL 쿼리 모듈화, 테스트, 계보 확인을 편하게 할 수 있습니다.
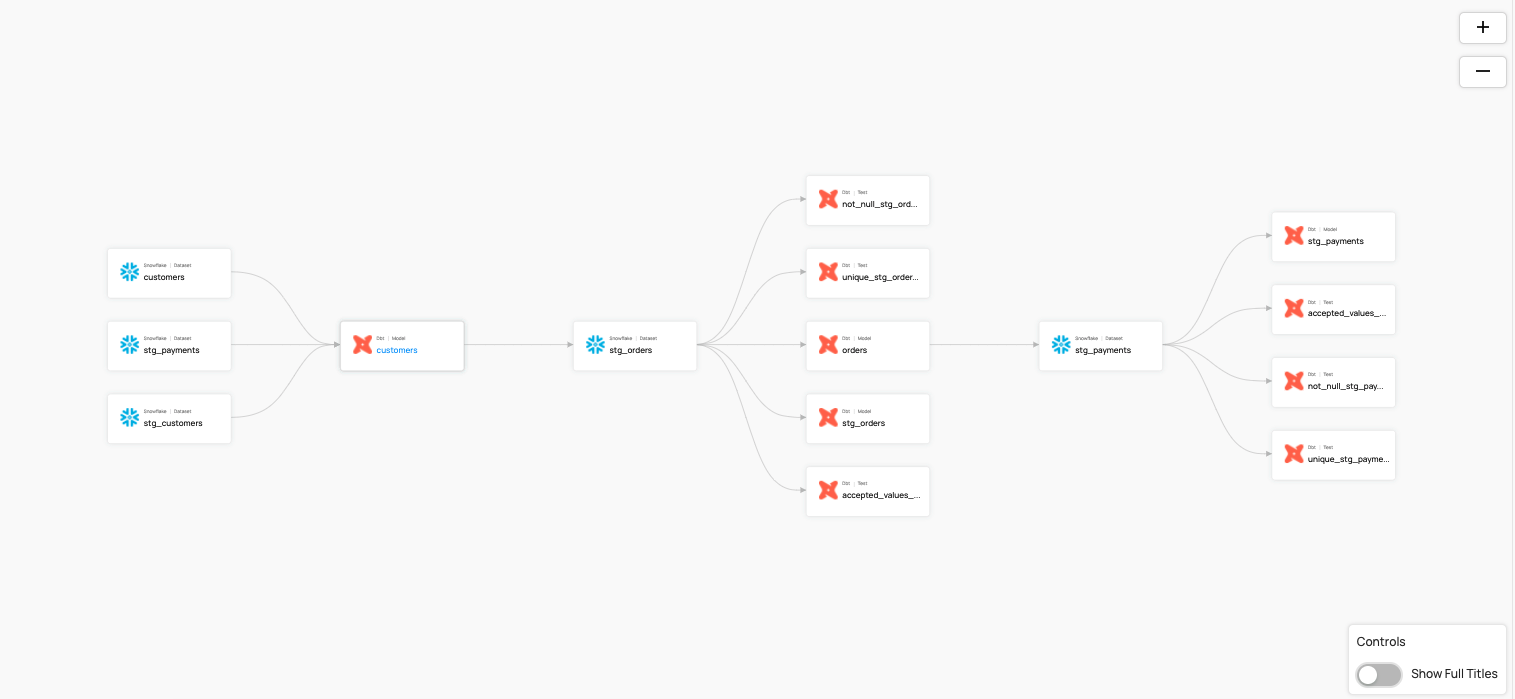 Datahub - 데이터 계보
Datahub - 데이터 계보
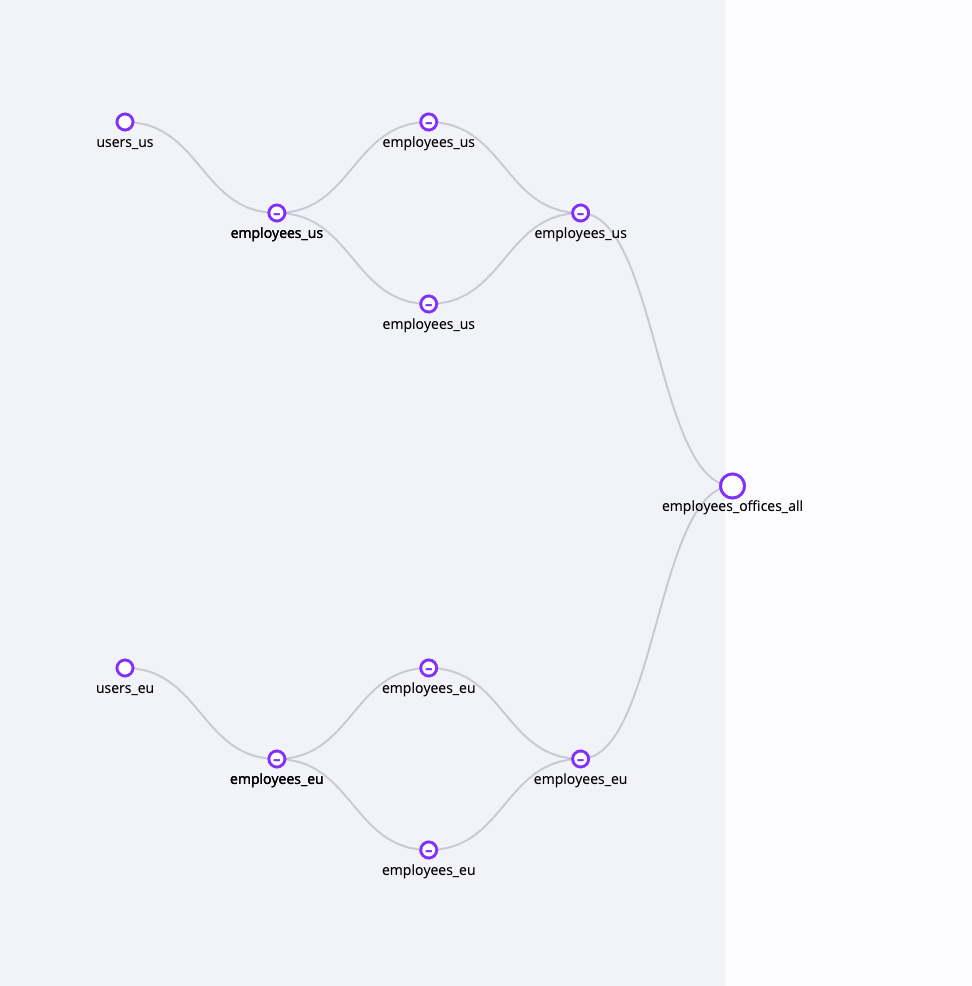 Amudsen - 데이터 계보 (출처 : https://medium.com/alvin-ai/data-lineage-in-amundsen-powered-by-alvin-df50cd40944c)
Amudsen - 데이터 계보 (출처 : https://medium.com/alvin-ai/data-lineage-in-amundsen-powered-by-alvin-df50cd40944c)
7) 인증 및 권한
- Datahub는 SSO 지원 및 세부적인 권한 설정이 가능합니다.
- SSO(Single Sing-On)로 Keycloak, Okta, Google Auth를 지원합니다.
- 사용자 / 그룹 단위로 정책 부여가 가능합니다. 현재는 View 관련 권한은 설정할 수 없고, 테이블이나 컬럼에 대한 설명, 오너, 태그 등을 수정할 수 있는 Edit 권한을 세부적으로 조정 가능합니다.
- Amundsen은 SSO을 지원하나 세부적인 권한 설정은 지원하지 않습니다.
- SSO 로 Keycloack, Okta, Flask_oidc를 지원합니다.
- Amundsen은 자체적인 권한 설정을 지원하지 않습니다.
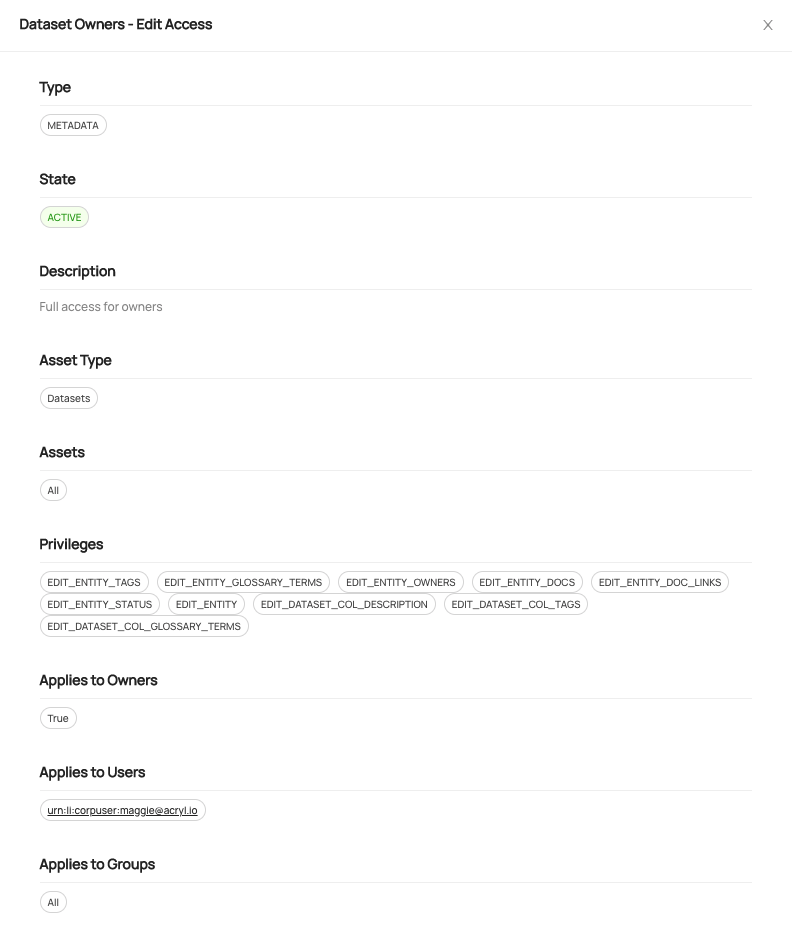 Datahub - 권한 및 정책 페이지
Datahub - 권한 및 정책 페이지
8) 데이터 소스 지원
- 두 플랫폼 모두 BigQuery, Mysql, dbt, AWS S3 등 대중적으로 쓰이는 데이터 소스를 지원합니다.
- Amundsen은 pandas, neo4j 등의 더 다양한 형태를 지원합니다.
9) 사용자 이용 통계
- Datahub는 시각화된 이용 분석 페이지가 따로 존재합니다.
- 자주 검색된 데이터 셋 / 자주 수행된 액션 등을 그래프로 확인할 수 있습니다. (데모 사이트에서 해당 페이지를 직접 확인하실 수 있습니다.)
- Amundsen은 단편적인 이용 통계를 제공합니다.
- 메인 화면에서 “인기 있는 데이터셋”을, 각 테이블마다 “해당 테이블을 자주 이용한 사용자”을 확인할 수 있습습니다.
- 따로 분석 페이지는 없습니다.
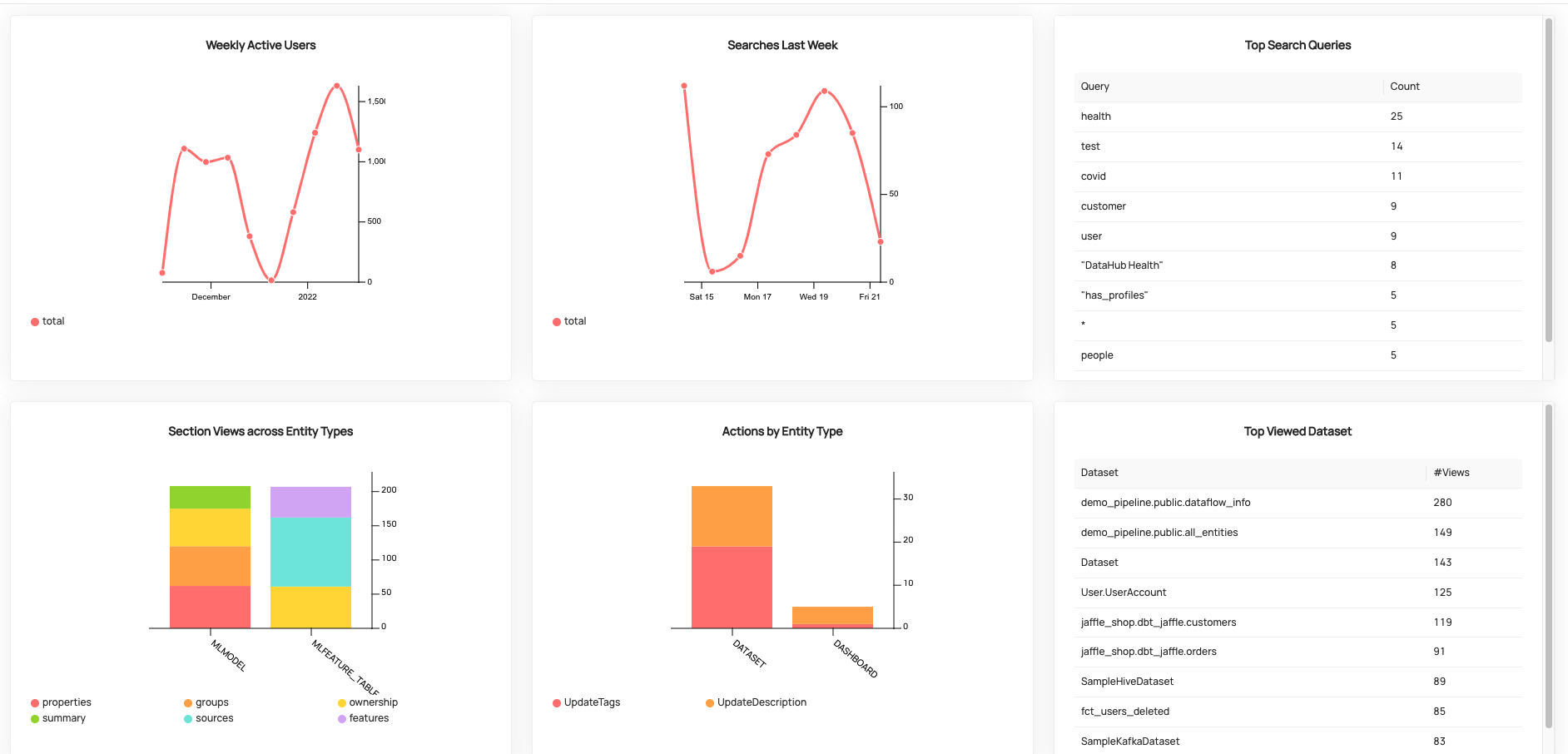 Datahub - 사용자 이용 통계 페이지
Datahub - 사용자 이용 통계 페이지
 Amundsen - 테이블을 자주 이용한 사용자
Amundsen - 테이블을 자주 이용한 사용자
10) 서포트
- 공식 Github Repository 의 Star 수를 비교했을 때 Datahub가 4.5K, Amundsen이 3K 로 Datahub 가 더 많은 Star를 보유하고 있었습니다.
- 두 플랫폼 모두 공식 슬랙, 웹사이트, Github repository 등의 다양한 채널을 지원했으나, 슬랙의 활성화(질문, 답변의 활발함)나 공식 문서의 체계성 측면에서 Datahub가 좀더 우세했습니다.
4. 최종 결정 : Datahub!
사용성의 편리함
가장 결정적인 이유는 사용성 차이였습니다. 사용성은 데이터 이용자와 플랫폼 개발자, 두 측면에서 생각할 수 있습니다.
데이터 이용자 측면에서는 위에서도 비교했듯이, Datahub가 문서화, 오너십, 권한, 통계, 데이터 계보 관점에서 더 다양하고 풍부한 기능들을 지원합니다. 이런 기능들이 실제로 도입됐을 때, 이용자가 원하는 데이터를 빠르게 찾고 쏘카의 데이터 디스커버리를 발전시키는 데에 더 많은 도움을 얻을 수 있을거라 판단했습니다.
플랫폼 개발자 측면에서도 메타데이터 주입 시 Datahub가 더 편리했습니다. 동일한 메타데이터를 주입한다고 가정했을 때 Datahub는 10 줄 내외의 yaml 파일로 가능한 반면, Amundsen은 100줄 이상의 Python Script가 필요했습니다. Amundsen Script가 긴 만큼 세세한 설정이 가능한지, 또 그런 세세한 설정이 가능하다고 해도 현재 상황에 필요한지를 고민해봤을 때는 의문점이 있었습니다. 따라서 메타데이터를 주입할 데이터 소스가 한정된 쏘카의 상황에는 Datahub 가 더 적절하다고 판단했습니다.
UI의 깔끔함
많은 사람이 이용하는 솔루션이나 플랫폼을 도입할때는 UI도 무시할 수 없다고 생각합니다. PoC시 Datahub UI가 훨씬 깔끔하다는 반응이 많았고, 매 버전마다 UI가 개선되고 있는 점도 Datahub으로 결정힌 이유 중 하나였습니다.
빠르고 풍부한 서포트
Datahub의 공식 슬랙 채널에는 현재 2,000명이 넘는 사람이 활동하고 있고, 주제별로 분리된 다양한 채널에서 질답과 오류 대응이 활발하게 이루어지는 편입니다. 또한 새로운 기능을 제안(Feature Request)하는 채널도 따로 있어서, 사용자의 피드백을 풍부하게 반영하려는 노력이 느껴졌습니다. 이 뿐만 아니라 최근 발생한 Log4j 취약점 사태에도 빠르게 해당 취약점을 보완한 패치가 반영되고, 모든 진행 상황이 슬랙을 통해 공유되었습니다.
개인적인 경험으로는 공식 채널에 질문을 올리면 답이 안달리는 경우가 거의 없었던 것 같습니다. 국내에 데이터 디스커버리 플랫폼 관련 자료가 많지 않고, 팀에 합류하지 얼마 되지 않은 신입 엔지니어의 입장에서는 이런 활발한 서포트가 있다는 것이 매우 중요했습니다. 여담으로 PoC 과정에서 Datahub 공식 슬랙에 질문을 100개정도 한 것 같은데, 이제는 사람들이 질문이 있으면 저를 호출합니다(!)
 디니 콜 1
디니 콜 1
 디니 콜 2
디니 콜 2
 디니 콜 3
디니 콜 3
5. 마무리 & 다음 편 예고
이렇게 쏘카는 데이터 디스커버리 플랫폼으로 Datahub를 선정하게 되었습니다. 다음 편에는 구체적으로 Datahub를 어떻게 사내 인프라 환경에 구축했는지, 메타데이터 주입 방식을 어떻게 자동화하고 효율화 했는지 설명하려고 합니다.
쏘카에서 신입 데이터 엔지니어가 어떤 일을 하는지 궁금하시다면, 쏘카 신입 데이터 엔지니어 디니의 4개월 회고에서 확인하실 수 있습니다(데이터 엔지니어링 팀이 데이터 엔지니어링 그룹으로 바뀌고 데이터 웨어하우스 팀, 데이터 플랫폼 팀, 모비딕 팀으로 세분화되었어요)
긴 글 읽어주셔서 감사합니다. 그러면 다음 편에서 만나요!