 디니
디니안녕하세요, 데이터 플랫폼 팀의 디니입니다.
이번 글은 ‘쏘카의 데이터 디스커버리 플랫폼 도입기’ 3부작 중 2편입니다. 1편 : 데이터 디스커버리 플랫폼 도입기 - 데이터 디스커버리란?에서는 데이터 디스커버리의 개념과 쏘카가 데이터 디스커버리 플랫폼으로 Datahub를 선택하게 된 의사결정 과정을 소개했습니다.
2편에서는 Datahub를 GKE 환경에 배포한 과정과 데이터 디스커버리 플랫폼에 필요한 추가 기능들을 어떻게 구현하였는지에 대해 소개하려고 합니다. 다음과 같은 분들이 읽으시면 도움이 되리라고 생각합니다.
- 메타데이터 플랫폼 도입에 관심이 있는 개발자
- 클라우드 환경에 메타데이터 플랫폼 배포하는 과정에 관심이 있는 사람
- 쏘카 데이터 플랫폼팀 업무에 관심이 있는 사람
목차는 다음과 같습니다.
-
1.1. 무엇을 해야 하나요?
1.2. 고려해야 할 부분
-
2.1. GKE 배포
2.2. CloudSQL DB migration
2.3. Keycloak 인증
-
3.1. 메타데이터 주입 방법
3.2. 메타데이터 주입 정책 결정
3.3. 메타데이터 주입 과정 자동화 (with Airflow)
3.4. 메타데이터 추출 과정의 권한 축소
1. 문제 정의
1.1. 무엇을 해야 하나요?
- Datahub를 사내 클라우드 환경에 안정적으로 배포합니다.
- Datahub에 메타데이터 주입 파이프라인을 자동화합니다.
1.2. 고려해야 할 부분
- 쏘카는 데이터 소스로 MySQL(운영)과 BigQuery(분석)를 사용하고 있습니다. 두 데이터 소스의 특성을 고려한 메타데이터 주입 파이프라인이 필요합니다.
- 플랫폼 상의 데이터가 유실 위험 없이 안전하게 저장되어야 합니다.
- 인증된 사용자만 플랫폼에 접속할 수 있어야 합니다.
- CI/CD 파이프라인을 이용한 배포 자동화가 되어야 합니다.
2. Datahub on GKE 배포 과정
먼저 Datahub를 어떻게 사내 클라우드 환경에 안정적으로 배포했는지 알아보겠습니다.
Datahub는 오픈소스 기반으로 매우 빠르게 업데이트되고 있습니다. 해당 배포는 6개월 전에 이루어진 것으로, 현재 Datahub 배포 및 metadata ingestion 과정과는 다소 차이가 있을 수 있습니다. 이 점 양해 부탁드립니다.
2.1. GKE 배포
쏘카 데이터 엔지니어링 그룹의 쿠버네티스 환경은 GCP(Google Cloud Platform)의 GKE(Google Kuberentes Engine)를 사용하고 있습니다. 또한 대부분의 애플리케이션을 Helm Chart를 이용하여 클러스터에 배포하고 있습니다. Datahub 역시 공식 Helm Chart를 제공하고 있으며, 총 2벌의 차트로 구성되어 있습니다. Datahub Helm Chart 구성은 다음과 같습니다.
datahub: Datahub 애플리케이션에 필요한 요소들 설치 (Frontend, GMS 등)prerequisites: Datahub에 필요한 사전 요소들을 설치 (MySQL, Kafka, ElasticSearch, Neo4j 등)
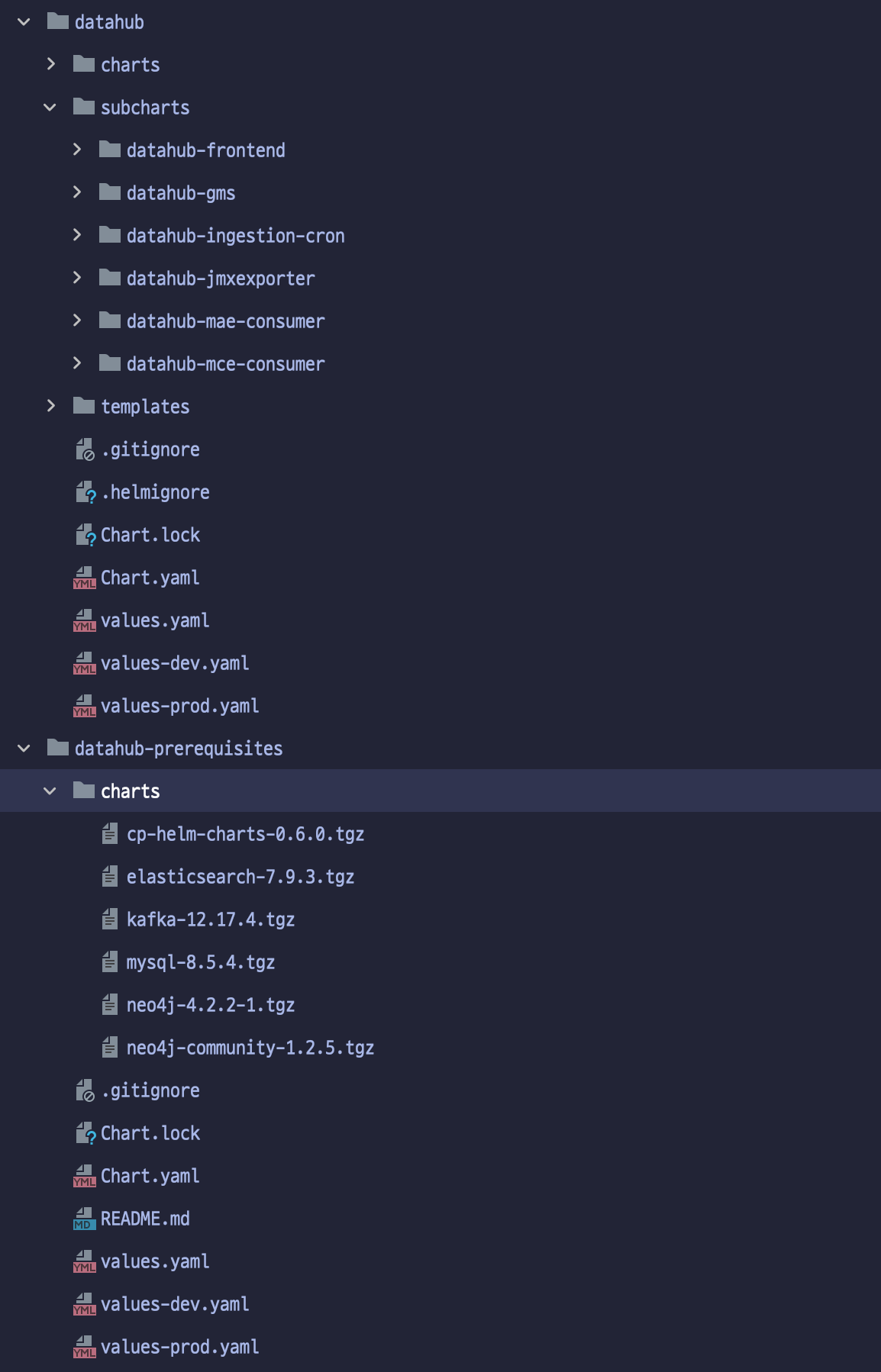 Datahub 차트 구조
Datahub 차트 구조
공식 Datahub Helm Chart의 Ingress를 쏘카의 환경에 맞게 수정한 뒤 배포하였습니다. 또한 원활한 테스트를 위해 개발 클러스터, 운영 클러스터에 각각 배포하였습니다.
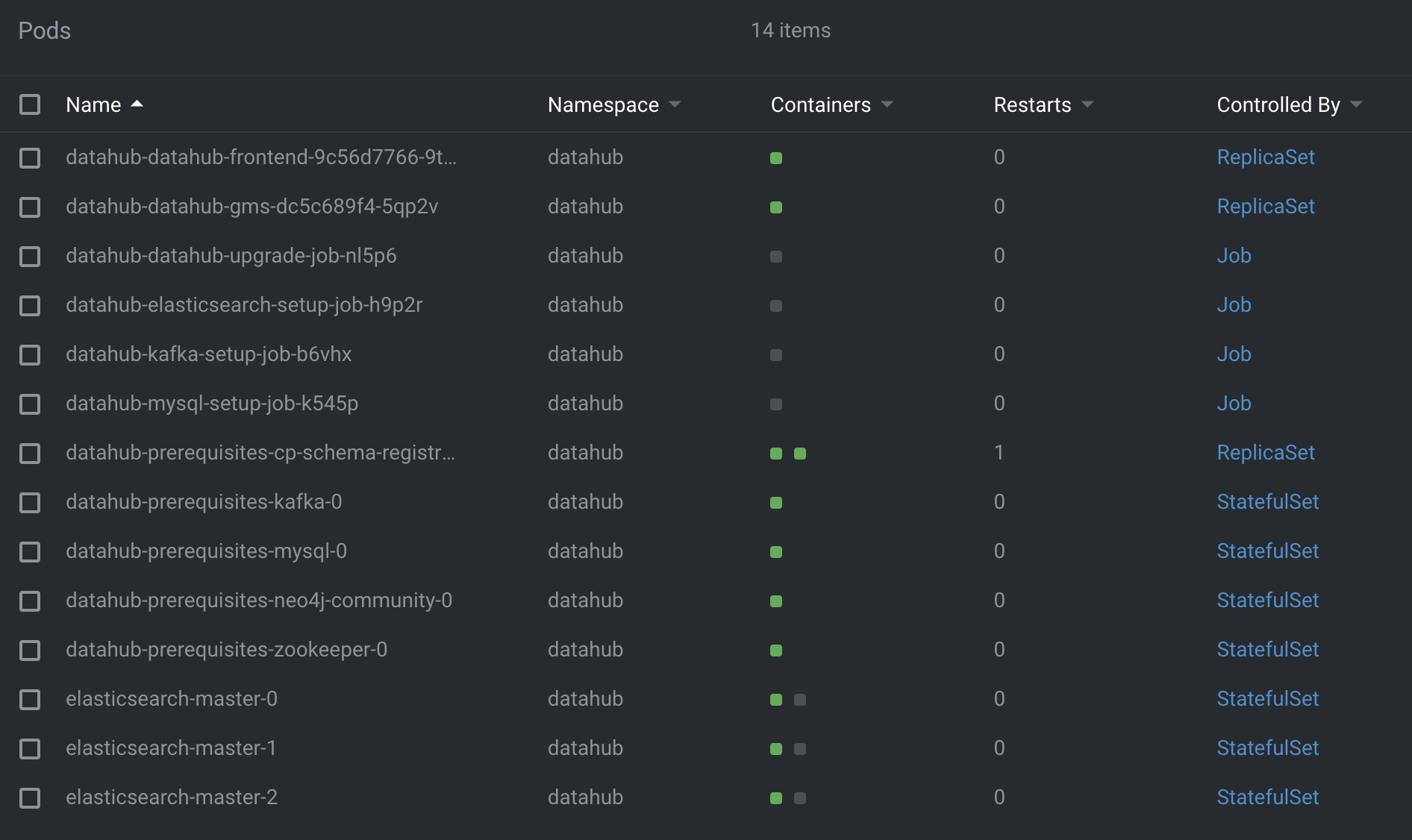 Datahub 최초 배포 시 Pod 상태
Datahub 최초 배포 시 Pod 상태
2.2. CloudSQL DB migration
Datahub는 자체 DB(storage)로 MySQL Pod을 사용합니다. 물론 PVC(PersistentVolumeClaim)이 붙어있긴 했지만, 앞으로 Datahub 애플리케이션 상에서 쌓일 데이터가 점점 늘어날 것이며 데이터의 내용 또한 중요하기 때문에, 앞으로의 확장성과 만에 하나라도 있을 유실 가능성을 방지하는 방향으로 아키텍처를 고민했습니다. 결국에는 MySQL Pod 대신 외부 데이터베이스로 GCP CloudSQL Instance를 연결하기로 결정했습니다.
구체적으로는 다음 과정으로 진행했습니다.
- CloudSQL DB (혹은 새로운 Instance) 생성
- (Optional) 사용자 생성
- Datahub가 CloudSQL 가리키게 하기
기존 Datahub의 Helm Chart는 SQL Host로 MySQL Pod을 가리키고 있습니다. 위에서 만든 CloudSQL DB를 가리키게 하기 위해서 Helm Chart를 다음과 같이 수정합니다.
# charts/datahub/values.yaml
sql:
datasource:
host: <cloudsql_host_address>:<port>
url: "jdbc:mysql://<cloudsql_host_address>:<port>/<cloudsql_db_name>?verifyServerCertificate=false&useSSL=true&useUnicode=yes&characterEncoding=UTF-8&enabledTLSProtocols=TLSv1.2"
hostForMysqlClient: <cloudsql_host_address>
port: <port>
driver: "com.mysql.jdbc.Driver"
username: <username>
password:
secretRef: <별도로 생성한 secret 이름>
secretKey: <별도로 생성한 secret 키>
# charts/datahub/subcharts/datahub-gms/values.yaml
sql:
datasource:
host: <cloudsql_host_address>:<port>
url: "jdbc:mysql://<cloudsql_host_address>:<port>/datahub?verifyServerCertificate=false&useSSL=true"
driver: "com.mysql.jdbc.Driver"
username: <username>
password:
secretRef: <별도로 생성한 secret 이름>
secretKey: <별도로 생성한 secret 키>
실제로는 민감한 정보들을 Helm Chart에 직접 명시하지 않고 다음처럼 별도의 Secret으로 생성하여 참조하였습니다.
sql:
datasource:
host:
secretRef: mysql-secrets
secretKey: mysql-host
url:
secretRef: mysql-secrets
secretKey: mysql-url
hostForMysqlClient:
secretRef: mysql-secrets
secretKey: mysql-hostForMysqlClient
port: "3306"
driver: "com.mysql.jdbc.Driver"
username:
secretRef: mysql-secrets
secretKey: mysql-username
password:
secretRef: mysql-secrets
secretKey: mysql-password
Secret yaml 파일은 다음과 같습니다.
apiVersion: v1
kind: Secret
metadata:
name: mysql-secrets
namespace: datahub
type: Opaque
data:
mysql-host: <data>
mysql-hostForMysqlClient: <data>
mysql-password: <data>
mysql-root-password: <data>
mysql-url: <data>
mysql-username: <data>
최종적으로 정상 작동을 테스트합니다. 예를 들어, Datahub UI 상에서 데이터를 수정한 뒤 해당 CloudSQL DB에서 동일한 데이터가 업데이트되는지 확인합니다.
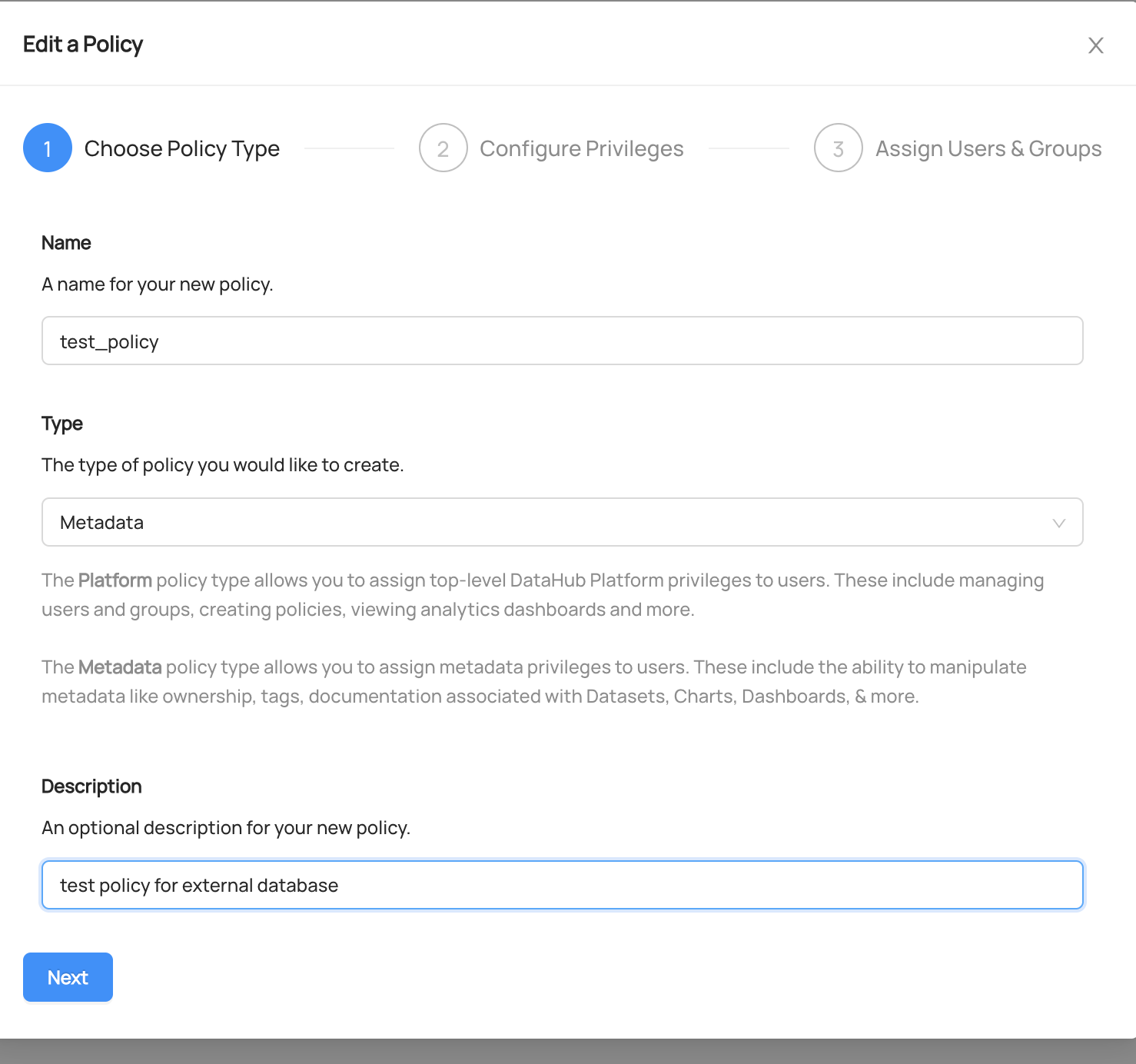 test_policy라는 정책을 생성해 보았습니다.
test_policy라는 정책을 생성해 보았습니다.
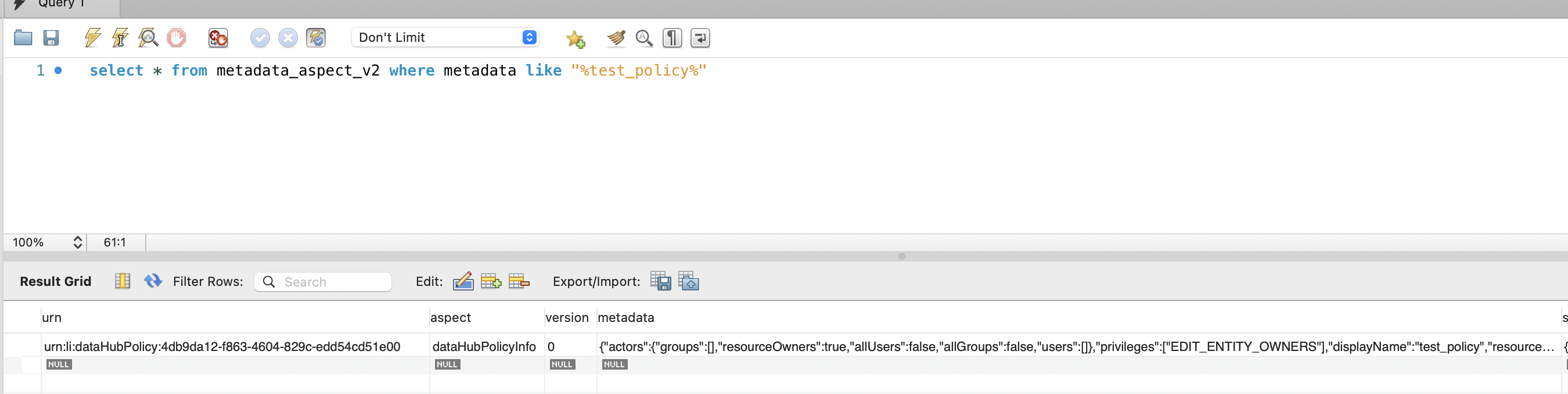 CloudSQL DB에서 동일한 데이터가 확인됩니다.
CloudSQL DB에서 동일한 데이터가 확인됩니다.
2.3. Keycloak 인증
Datahub이 배포되고 나면, 인증된 사용자만 애플리케이션에 접속되어야 합니다. Datahub는 Okta, Keycloak 등 여러 SSO를 지원합니다. 쏘카에서 이미 Keycloak을 이용하고 있기 때문에 Keycloak을 사용하기로 결정했습니다.
Datahub에 Keycloak 로그인을 적용하는 방법은 간단했습니다. Helm Chart의 values.yaml파일에서 frontend 부분에 몇 줄의 설정만 넣어주면 가능했습니다.
datahub-frontend:
...
extraEnvs:
- name: AUTH_OIDC_ENABLED
value: "true"
- name: AUTH_OIDC_CLIENT_ID
value: your-client-id
- name: AUTH_OIDC_CLIENT_SECRET
value: your-client-secret
- name: AUTH_OIDC_DISCOVERY_URI
value: your-provider-discovery-url
- name: AUTH_OIDC_BASE_URL
value: your-datahub-url
또한 다음과 같은 다양한 설정을 쉽게 정의할 수 있었습니다.
# User and groups provisioning
# OIDC 로그인 시, Datahub 상에 유저 없으면 자동 생성 여부
AUTH_OIDC_JIT_PROVISIONING_ENABLED=true
# OIDC 로그인 시, Datahub 상에 유저가 이미 존재해야 로그인 성공하는지 여부
AUTH_OIDC_PRE_PROVISIONING_REQUIRED=false
# OIDC의 그룹 정보를 Datahub에 연동
AUTH_OIDC_EXTRACT_GROUPS_ENABLED=true
AUTH_OIDC_GROUPS_CLAIM=<your-groups-claim-name>
3. 메타데이터 주입 과정
이렇게 Datahub를 클라우드 상에 안정적으로 구축했습니다. 하지만 아직 데이터 디스커버리 플랫폼으로서의 기능을 하지는 못합니다. 데이터 소스에서 실제로 메타데이터를 가져와서 플랫폼에서 보여줘야 하고, 이렇게 메타데이터를 가져오는 과정(=metadata ingestion)이 자동화되어야 합니다.
3.1. 메타데이터 주입 방법
Datahub에서는 recipe라고 불리는 yaml 파일을 datahub CLI로 실행하여 메타데이터를 주입합니다. 다음은 BigQuery에서 메타데이터를 가져오는 recipe 파일의 기본 예시입니다.
source:
type: bigquery
config:
project_id: <project_id>
options:
credentials_path : ${GOOGLE_APPLICATION_CREDENTIALS}
sink:
type: "datahub-rest"
config:
server: ${DATAHUB_GMS_ADDRESS} # datahub 애플리케이션의 backend 서버
source: 데이터 소스, 즉 “데이터를 어디서 가져오는지” 정의합니다.sink: “데이터를 어디에 저장하는지” 를 정의합니다. Datahub 어플리케이션에 올릴 수도 있고, 콘솔에 출력할 수도 있고, 파일로 저장할 수도 있습니다.
이 형식을 바탕으로 데이터 소스를 바꿀 수도 있고 여러 설정을 적용할 수도 있습니다. 파일을 실행할 때는 datahub ingestion -c "<파일_이름>"으로 실행합니다.
3.2. 메타데이터 주입 정책 결정
먼저 “어떤 데이터 소스”에서 메타데이터를 “얼마나 자주” 가져올 건지 결정해야 합니다.
쏘카에서는 주요 데이터 소스로 MySQL Aurora(운영)와 BigQuery(분석)를 사용하고 있습니다. 하지만 이 데이터 소스의 모든 테이블을 가져올 필요는 없었습니다. 예를 들면 DB에 따라서 개인 정보 관련 민감한 데이터들도 있고, 분석 DB 쪽에는 굳이 전사에 공유될 필요는 없는 임시 테이블들도 다수 존재했습니다. 따라서 각 데이터 소스 별 DB의 목록을 사전에 정하고, 해당 DB의 메타데이터를 주입하기로 했습니다.
참고로, 다음과 같이 Table 혹은 DB의 이름을 regex pattern으로 감지하여 선택적 메타데이터 주입이 가능합니다. (물론 데이터 소스마다 방법이 약간 다를 수 있습니다 - 예시는 BigQuery입니다.)
source:
type: bigquery
config:
schema_pattern:
allow: # 허용하는 dataset 패턴
- "my_dataset"
table_pattern:
allow: # 허용하는 table 패턴
- "^my_project.my_dataset.my_good_table\$"
deny: # 허용하지 않는 table 패턴
- "^my_project.my_dataset.my_bad_table\$"
include_views: false
그러면 얼마나 자주 가져와야 할까요? 매일매일 필요에 따라 테이블이 생겨났다가 사라지기도 하고, 테이블의 칼럼이 추가되거나 변경되는 일도 있을 것입니다. 하지만 이런 변화들을 꼭 실시간으로 봐야 할 필요는 없다고 생각했습니다. 하루에 한 번 정도 업데이트한다면, 리소스도 효율화하고 사내 데이터 현황을 파악하는 데 충분하다고 결정을 내렸습니다.
3.3. 메타데이터 주입 과정 자동화 (with Airflow)
이렇게 하루에 한 번 메타데이터 주입을 결정하고 난 뒤, 메타데이터 주입을 어떻게 자동화했는지 알아보겠습니다.
하루에 한 번 Batch 단위의 주입이라면 Airflow DAG로 간단하게 구현할 수 있었습니다. 데이터 소스에서 메타데이터를 주입하는 Task를 만들고, 하루 한 번만 돌려주면 됐습니다. 그런데 이 작업에는 datahub 패키지를 설치해야 하는 의존성이 필요합니다.
데이터 플랫폼 팀에서는 이런 경우 Airflow에 직접 의존성을 설치하지 않고, 필요한 의존성을 담은 Docker Image를 실행하는 KubernetesPodOperator를 만들어 해결하고 있습니다. 이렇게 하면 DAG 가 아무리 많아도 DAG 간 사용하는 라이브러리나 환경의 의존성 충돌을 방지할 수 있습니다.
 메타데이터 주입 흐름
메타데이터 주입 흐름
작성한 Dockerfile은 다음처럼 간단합니다.
# datahub-ingestion 이미지를 이용합니다.
FROM linkedin/datahub-ingestion:v0.8.20
# 미리 정의한 recipe 파일을 복사해 가져옵니다.
COPY datahub-ingestion-bigquery /datahub-ingestion-bigquery
# datahub CLI를 이용하여 recipe를 실행합니다.
CMD ["ingest", "-c", "/datahub-ingestion-bigquery/recipe_bigquery.yaml"]
datahub-ingestion-bigquery 안에는 recipe 파일이 들어 있습니다.
 datahub-ingestion-bigquery 디렉터리 구조
datahub-ingestion-bigquery 디렉터리 구조
3.4. 메타데이터 추출 과정의 권한 축소
어떻게 하면 최소한의 권한으로 메타데이터를 추출할 수 있을까?
Datahub는 메타데이터를 끌어오는 모든 대상 DB에 SELECT 권한을 허용해야 메타데이터 추출이 가능하도록 만들어져 있습니다. 예를 들면 MySQL DB에 3000개의 DB가 있다고 가정할 때, Datahub의 서비스 계정은 3000개의 DB에 대해 모두 권한이 있어야 하는 것입니다.
하지만 이 권한을 단독 솔루션에 부여하기에는 보안상 너무 무겁다고 판단했습니다. 그래서 어떻게 하면 최소한의 DB에 접근하면서 같은 기능을 구현할 수 있을지가 큰 고민거리였습니다.
Information Schema에서 직접 뽑아내 보자
당시 데이터 엔지니어링 팀 팀장(이시고 지금은 그룹장이신) 토마스가 아이디어를 주셨습니다.
 file을 이용하여 메타데이터 상태를 저장하는 흐름
file을 이용하여 메타데이터 상태를 저장하는 흐름
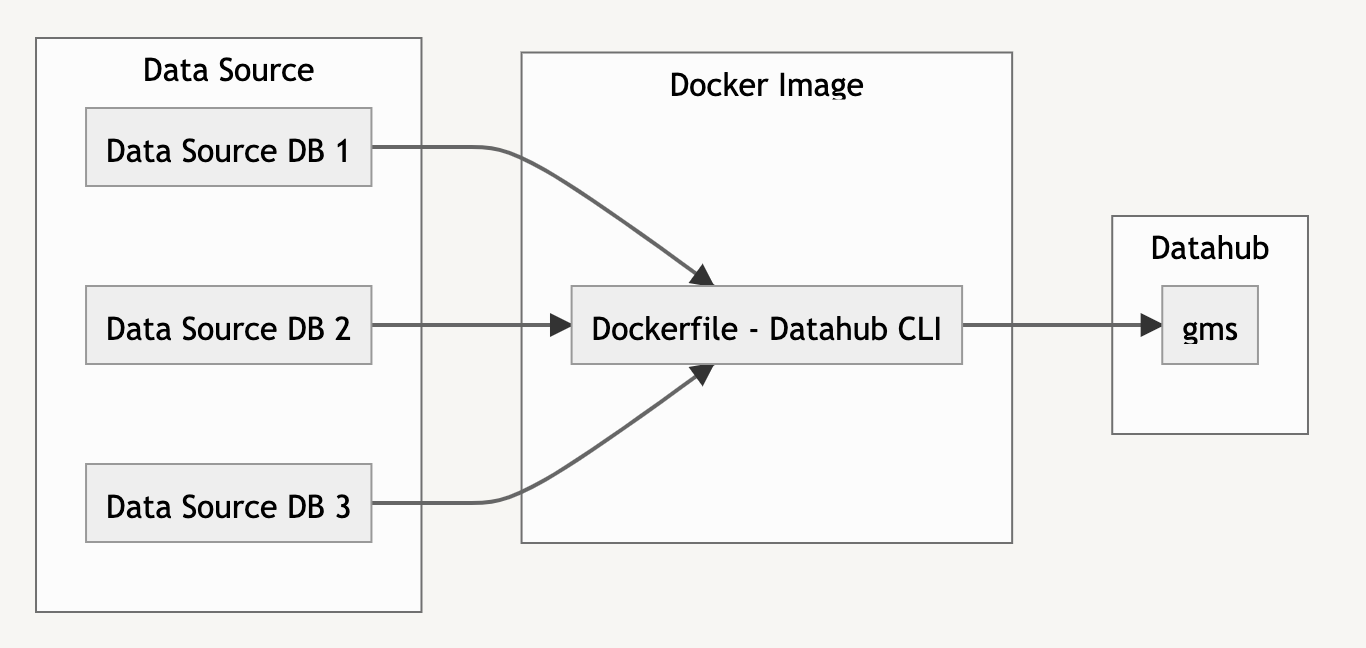
Datahub에는 데이터 소스의 메타데이터를 특정 형태의 json file로 변환하여 저장하는 기능이 있습니다. 또한 같은 형식의 json file을 기반으로 메타데이터를 Datahub 플랫폼에 주입하는 것도 가능했습니다. 그리고 해당 파일 형식을 확인해 본 결과 information_schema에서 대부분(사실 모두) 가져올 수 있는 정보였습니다.
그러면 information_schema에서 정보를 가져와서 file 형식을 맞춰 만들어주는 기능을 개발하고, 그 file을 기반으로 Datahub에 메타데이터를 주입하면 되지 않을까? 하는 생각이 들었습니다.
 metadata ingestion AS-IS 흐름
metadata ingestion AS-IS 흐름
 metadata ingestion TO-BE 흐름
metadata ingestion TO-BE 흐름
그래서 앞부분은 python script로 개발하고, file을 기반으로 메타데이터를 주입하는 부분은 기존 Datahub 프레임워크를 그대로 이용했습니다.
# 파이썬 이미지를 이용합니다.
FROM python:3.8
COPY datahub-ingestion-mysql /datahub-ingestion-mysql
WORKDIR /datahub-ingestion-mysql/src
USER root
# datahub를 포함한 필요한 의존성을 설치합니다.
RUN pip install --no-cache-dir mysql-connector-python==8.0.27 && pip install --no-cache-dir --upgrade acryl-datahub==0.8.20
# information_schema에서 메타데이터를 추출하는 python script를 실행하고, datahub CLI로 Datahub 플랫폼에 주입합니다.
CMD python main.py ; datahub ingest -c recipe_mysql_prod.yaml
main.py의 내용은 다음과 같습니다.
# main.py
import json
import os
from get_info_from_query import get_json_result
from make_and_execute_query import execute_query
from mysql.connector import Error, connection, errorcode
from templates import json_table_template
user = os.environ.get("USER")
password = os.environ.get("PASSWORD")
host = os.environ.get("HOST")
pattern_conditions = {
"schema_pattern_allowed": json.loads(os.environ.get("PATTERN")),
"schema_pattern_denied": [],
"table_pattern_allowed": [],
"table_pattern_denied": [],
}
def get_metadata_from_info_schema(user: str, password: str, host: str, pattern_conditions: str) -> None:
try:
cnx = connection.MySQLConnection(
user=user,
password=password,
host=host,
database="information_schema",
port="3306",
)
cursor = cnx.cursor()
table_and_column_result, constraint_result = execute_query(
cursor=cursor, pattern_conditions=pattern_conditions
)
json_result = get_json_result(
table_and_column_result,
constraint_result,
json_table_template=json_table_template,
)
with open("metadata.json", "w+") as f:
f.write(json_result)
cursor.close()
cnx.close()
except Error as err:
if err.errno == errorcode.ER_ACCESS_DENIED_ERROR:
print(err)
print("Something is wrong with your user name or password")
elif err.errno == errorcode.ER_BAD_DB_ERROR:
print("Database does not exist")
else:
print(err)
if __name__ == "__main__":
get_metadata_from_info_schema(user, password, host, pattern_conditions)
information_schema에서는 Table 정보, Column 정보, Constraint (Primary Key 등) 정보 등 여러 가지 정보를 추출합니다. 예를 들어 Column 정보는 다음과 같은 쿼리로 추출합니다. 이렇게 실행한 쿼리 결과를 Datahub에서 이용하는 json 형식에 맞게 바꿔줍니다.
# python script 중 information_schema에서 column info를 뽑아내는 부분
def get_column_info_query(pattern_clause) -> str:
column_info_query = f"""
SELECT Concat(table_schema, '.', table_name) AS schemaName,
column_name,
column_comment,
data_type,
column_type,
is_nullable,
column_key
FROM information_schema.columns
{pattern_clause}
ORDER BY schemaname,
ordinal_position;
"""
return column_info_query
최종 테스트
이렇게 기능을 구현한 뒤 프로젝트에 같이 참여하시고 계시는 DBA 제이든과 직접 테스트를 해보았습니다. 마지막으로 MySQL 계정 권한에 변경이 필요했습니다.
-
AS-IS : 모든 DB에 대해 SELECT 권한
-
TO-BE : 모든 DB에 대해 REFERENCE 권한
CREATE USER '<username>'@'XX.XX.%' IDENTIFIED BY '<password>'; GRANT References ON *.* TO '<username>'@'XX.XX.%';
결과적으로 원하는 DB의 모든 메타데이터를 가져와서 Datahub에 주입하는 데에 성공했습니다.
 기능 구현 내용
기능 구현 내용
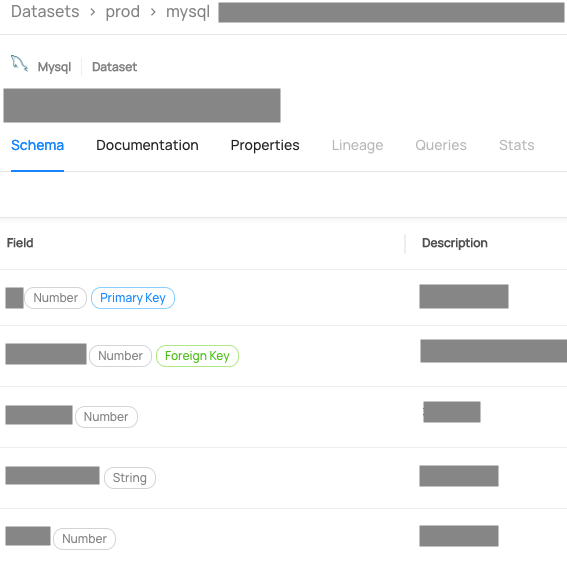 축소된 권한으로 모든 정보를 가져올 수 있습니다.
축소된 권한으로 모든 정보를 가져올 수 있습니다.
이 기능 개발로 쏘카의 DB에 접근하는 Datahub 계정의 권한이 크게 축소되어 내부 정보보호 규칙에 맞게 보안을 개선할 수 있습니다. 그리고 Datahub 최종 도입 결정에 긍정적인 영향을 미쳤습니다.
4. 마무리
이러한 여러 과정 끝에, Datahub가 쏘카에 도입될 준비를 마쳤습니다. 현재는 이렇게 테스트 배포를 마치고 사내 공개를 위한 준비 작업을 하고 있습니다. 이 자리를 빌려 Datahub 도입에 힘써주신 모든 분들에게 감사드립니다.
입사하고 맡은 첫 프로젝트였는데 쏘카 데이터 플랫폼팀의 전반적인 인프라와 배포 흐름에 대해 알 수 있는 좋은 기회였습니다. 여담으로, 구현하면서 슬랙에서 질답을 너무 많이 한 나머지 커뮤니티 기여자로 Datahub 팀과 원격 인터뷰를 하는 기회도 얻었습니다 (!)
 인터뷰 기념품으로 준 Datahub 기념품 세트
인터뷰 기념품으로 준 Datahub 기념품 세트
 기념품과 함께 온 감사 메시지
기념품과 함께 온 감사 메시지
마지막으로 Datahub를 도입하려는 분들에게 팁을 드리자면 다음과 같습니다.
데이터 소스 특성에 따라서 메타데이터 파이프라인 구현 방법 정하기
- 데이터 소스와 업데이트 주기를 결정한 뒤 구현 방법을 결정하기를 추천합니다.
- 하루 한 번 정도의 Batch 작업이라면
Airflow DAG로도 충분합니다. - 최근에는 Datahub UI 상에서 Ingestion을 설정할 수 있는 기능도 나왔습니다. 장단점을 비교해 보고 결정하시면 좋을 것 같습니다.
DB 특성에 따라서 메타데이터 추출 로직 조정하기
- 권한에 민감한 DB라면 information_schema에서 바로 메타데이터를 뽑는 로직을 구현하는 방법이 있습니다.
Datahub 공식 Slack Workspace에 참여하기
- Ingestion, Deployment 등 다양한 주제별로 질답을 나눌 수 있는 채널이 있습니다.
- 거의 모든 질문에 빠르게 답이 달릴 정도로 커뮤니티가 활성화되어 있습니다. 적극적으로 참여하시면서 도움을 얻기를 추천드립니다.
다음 편에서는 실제로 데이터 디스커버리 플랫폼이 도입된 후의 운영 방식과 효과에 대해서 살펴보겠습니다.
긴 글 읽어주셔서 감사합니다.
데이터 플랫폼팀이 하는 업무가 궁금하시다면 데이터 엔지니어링 팀이 하는 일과 쏘카 데이터 플랫폼 엔지니어 채용공고를, 데이터 플랫폼 팀의 신입 온보딩 과정이 궁금하시다면 쏘카 신입 데이터 엔지니어 디니의 4개월 회고를 보시기를 추천드립니다.