 토마스
토마스쏘카에서 개발한 딥러닝 기반 차량 파손 탐지 모델을 시스템에 반영하는 과정에 대해 작성한 글입니다. 딥러닝 기반 차량 파손 탐지 모델에 대한 내용이 궁금하시면 Semantic Segmentation을 활용한 차량 파손 탐지 딥러닝 모델 개발기을 참고하시면 좋을 것 같습니다.
목차
배경
차량을 대여할 때 가장 먼저 하게 되는 일이 무엇일까요? 여러 가지가 있겠지만 우선 차량에 손상이나 긁힘이 없는지를 꼼꼼히 살펴봅니다. 나중에 반납할 때 손상이 발견되면 해당 건의 책임을 물 수 있어 곤란을 겪게 되는 상황이 발생할 수도 있습니다. 그래서 차량을 구석구석 살펴본 뒤, 이미 손상이 있는 부분은 사진을 찍어놓기도 합니다.
쏘카 역시 차량을 운행하기 전에 사용자가 각 부분의 사진을 찍어 전송하는 과정이 있습니다. 그럼 이러한 차량의 사진들은 어떠한 방식으로 처리되고 있을까요? 3개월 전만 하더라도, 쏘카의 차량 검수팀은 사용자가 전송한 차량 사진들을 한 땀 한 땀 눈으로 확인하며 손상 유무를 판정했습니다. 하루에 업로드되는 사진이 8만 장 정도 되니 전수조사를 하는 데에 어려움이 많았고, 다른 업무들에 우선순위가 밀려 샘플 조사도 쉽지 않은 상태였습니다.
이에 따라, 이미지를 확인하고 차량의 손상을 판정하는 과정에 대한 자동화 방안을 찾아보게 되었고, DL(Deep Learning)을 이용하여 차량 손상을 판정하는 모델을 개발하여 이를 운영하는 시스템을 구축하는 프로젝트가 시작되었습니다.
딥러닝 모델을 서빙하기 위한 시스템은 어떻게 구성할까?
딥러닝 모델을 개발할 때는 Input과 Output이 비교적 명확한 편입니다. 이미지를 분석하여 차량 파손을 탐지하는 모델의 경우에는 Input으로 차량 이미지(JPG, PNG 등)를 받고, Output으로 차량의 파손과 관련된 정보(파손 종류, 파손 확률 등)와 파손 영역이 표시된 결과 이미지를 생성하게 됩니다.
그런데 딥러닝 모델을 실제 시스템과 결합하여 사용할 때에는 고려할 사항들이 좀 더 많아지고 복잡해지게 됩니다.
사용자가 찍어 올리는 차량 이미지를 딥러닝 모델을 구동하는 머신에 다운로드 받아야 하고, 판정 결과는 시스템이 원하는 장소에 파일로 저장하거나 또는 데이터베이스에 저장하기도 합니다. 딥러닝 모델을 운영하려면 시스템 성능도 중요하게 고려해야 하는데, 이미지를 판정하는 처리량(시간당 몇 장의 이미지를 판정할 수 있는가)이 실제 이미지 업로드 양을 감당할 수 있어야 하기 때문입니다.
쏘카의 경우, 차량 파손 판정 DL 모델을 서빙하기 위해 고려할 사항은 다음과 같았습니다.
- 현재 차량 검수 운영 방식 (전반적인 프로세스 확인)
- 모델이 판정해야 하는 이미지의 수량 (시간당 처리량 판단)
- 어떻게 이미지를 모델에 전달할 것인가?
- 이미지 판정 결과는 어떻게 전달할 것인가?
- 전체 시스템의 동작 상태를 확인할 수 있는 방법은?
위와 같은 고려 사항과 요구 사항들을 만족시키기 위해, 딥러닝 모델 서빙을 위한 다양한 방안들에 대해 리뷰했습니다. 현재 각 클라우드 플랫폼들이 제공하는 모델 서빙 시스템 중 대표적인 것으로 Kubeflow, SageMaker, AutoML 등이 있습니다. 이와 같은 서비스들은 모델의 학습부터 배포, 서빙에 이르기까지 모든 기능을 제공하는 End-to-End platform입니다.
그런데, 이처럼 전 과정에 걸쳐 다양한 서비스를 지원하는 만큼 빠른 시간에 사용방법을 습득하여 입맛에 맞게 적용하기에는 약간의 허들이 존재합니다. 또한, 이러한 플랫폼 중의 일부는 현재 빠른 속도로 업데이트가 진행되고 있어서 실제 서비스에 투입하기에는 약간 불안정한 것도 사실입니다.
그래서 저희 쏘카 데이터 엔지니어링팀에서는 딥러닝 모델을 안정적으로 서빙하는 것에 포커스를 두고, 빠른 시간에 설계 및 개발을 완료하여 사내 시스템과 통합하는 것이 목표입니다. 몇 번의 논의와 수정을 거쳐 최종적으로 결정된 시스템은 아래 그림과 같습니다.
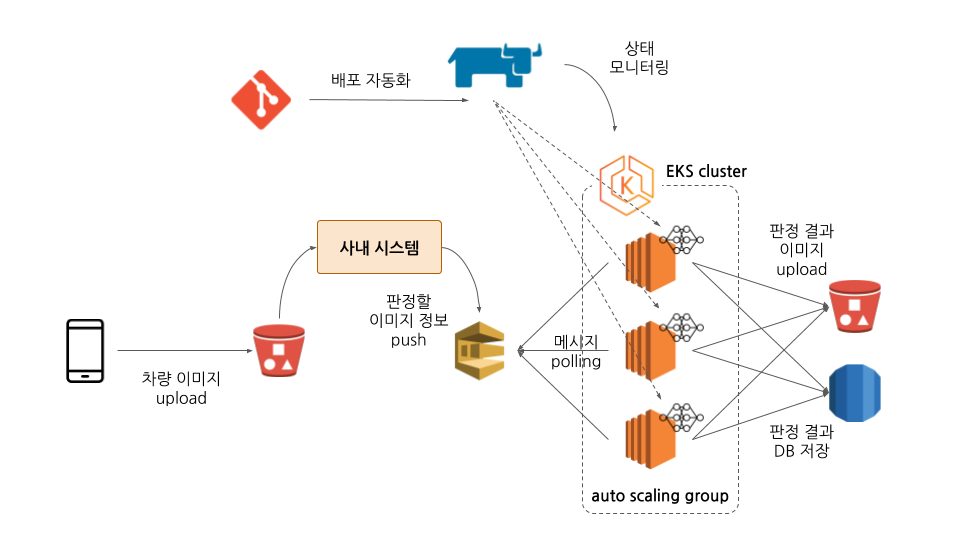 그림 1. 전체 시스템 구성도 - AWS SQS + Kubernetes + Git + Rancher + S3, DB
그림 1. 전체 시스템 구성도 - AWS SQS + Kubernetes + Git + Rancher + S3, DB
그럼, 이어서 위 그림에 표현된 각각의 모듈 및 시스템 구축 방법에 대해 좀 더 자세히 설명하도록 하겠습니다.
Serving Architecture
이 후 설명하는 내용은 사내 시스템 부분을 제외한 모델 서빙 시스템 관련 내용입니다. 사내 시스템과 관련된 내용은 향후 기회가 있을 때 쏘카 개발본부에서 자세히 소개드리는 것으로 하겠습니다.
이미지 수집: S3
차량을 대여한 사용자가 스마트폰으로 찍어서 업로드하는 사진은 S3에 저장됩니다. 이렇게 저장된 사진들은 사내 시스템을 담당하고 있는 개발본부에서 관리합니다. 각각의 이미지는 인증을 통해 CloudFront로 접근 가능합니다.
사내 시스템과 모델간의 인터페이스: AWS SQS
사내 시스템과 차량 손상 판정 모델의 커플링을 최소화하기 위해 외부 시스템과 모델 간의 인터페이스는 AWS SQS로 결정했습니다. 인터페이스로 메세지큐를 사용하는 장점은 여러 가지가 있는데 이번 케이스에서는 다음과 같은 사항들이 고려되었습니다.
- 1) 쉽고 빠른 인터페이스의 구축 및 사용
- 2) 향후 검수 시스템의 변경 또는 차량 손상 판정 모델의 변경 시 상호간의 영향 최소화
- 3) 이미지 처리량의 변화에 따른 유연한 Scaling 지원
1) 쉽고 빠른 인터페이스의 구축 및 사용
- AWS SQS는 특별한 설정 없이 기본 설정으로 사용해도 별 문제가 없으며, Queue에 메시지를 전송하는 방법 또한 간단합니다.
- 아래 이미지는 AWS SQS를 생성할 때 입력하게 되는 페이지인데, 대기열 이름을 작성하고 맨 아래쪽 대기열 생성 버튼만 누르면 Queue가 생성됩니다. 구성하려는 서비스에 따라 대기열 유형을 결정하고, 대기열 속성의 값들을 적당히 조정하면 됩니다.
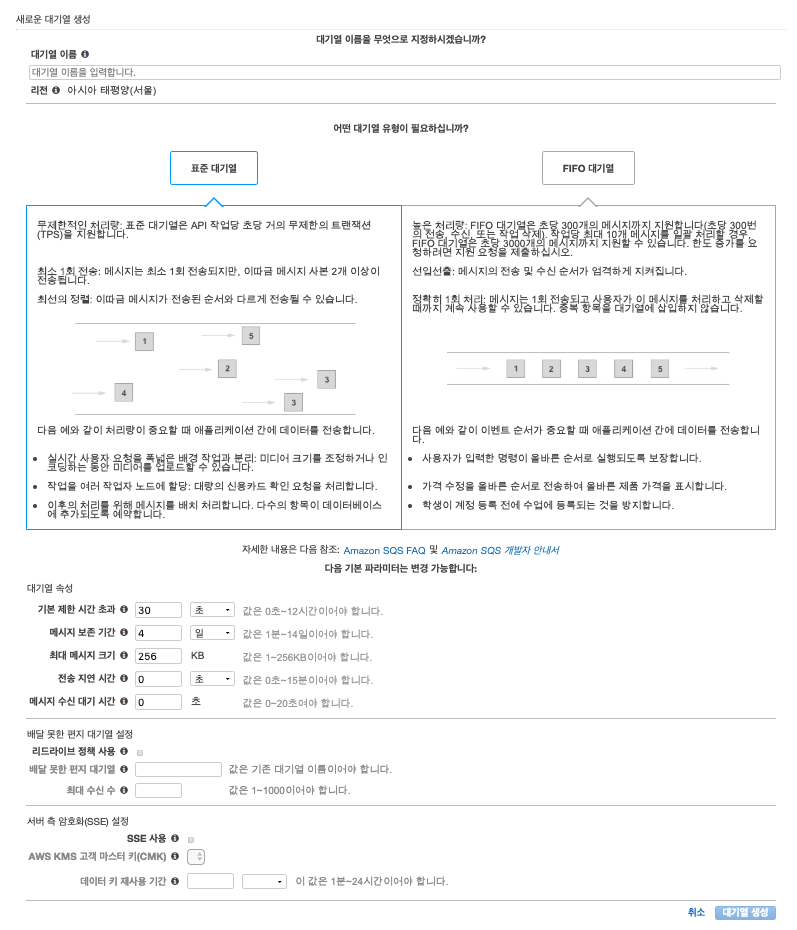
- Queue에 메시지를 전송하고, 메시지를 받아오기 위해서는 Python의 boto 라이브러리를 사용하면 됩니다. 메시지 Send, Receive, Delete는 아래 코드에서처럼 boto 라이브러리 함수를 호출하여 구현할 수 있습니다 (실 서비스 적용 시에는 개발 환경에 따른 예외 처리 방안들을 포함하여 구현해야 합니다).
import boto3
import json
import logging
import os
class SqsHelper():
def __init__(self, aws_sqs_url):
self.aws_sqs_url = aws_sqs_url
aws_access_key = os.getenv('AWS_ACCESS_KEY_ID')
aws_secret_key = os.getenv('AWS_SECRET_ACCESS_KEY')
aws_region = os.getenv('AWS_REGION')
self.sqs = boto3.client("sqs",
region_name=aws_region,
aws_access_key_id=aws_access_key,
aws_secret_access_key=aws_secret_key)
def send_message(self, message_body):
response = None
try:
# for standard queue (not FIFO)
response = self.sqs.send_message(QueueUrl=self.aws_sqs_url,
MessageBody=message_body)
except Exception as e:
logging.getLogger(LOGGER_NAME).error("send_message() error [%s]", e)
finally:
return response
def receive_message(self):
self.receipt_handle = None
message_body_json = None
try:
sqs_response = self.sqs.receive_message(QueueUrl=self.aws_sqs_url,
AttributeNames=["All"],
MaxNumberOfMessages=1,
VisibilityTimeout=90,
WaitTimeSeconds=0)
if sqs_response is not None:
message = sqs_response["Messages"][0]
self.receipt_handle = message["ReceiptHandle"]
message_body = message["Body"]
message_body = message_body.replace("\'", "\"")
message_body_json = json.loads(message_body)
except KeyError:
# do nothing - there is no message
logging.getLogger(LOGGER_NAME).debug("receive_message() error [%s]", e)
except Exception as e:
logging.getLogger(LOGGER_NAME).error("receive_message() error [%s]", e)
finally:
return message_body_json
def delete_message(self):
try:
if self.receipt_handle is not None:
self.sqs.delete_message(QueueUrl=self.aws_sqs_url,
ReceiptHandle=self.receipt_handle)
except Exception as e:
logging.getLogger(LOGGER_NAME).error("delete_message() error [%s]", e)
- 본 프로젝트에서 메시지는 간단한 JSON 형태로 구성하여 전송했으나, 초당 처리량이 수십, 수백건으로 증가하는 것을 대비하여 Protocol Buffers를 고려하는 것도 좋습니다. Protocol Buffers를 사용하면 메시지의 특성에 따라 드라마틱하게 메시지 전송량과 처리속도를 향상시킬 수 있습니다.
2) 향후 검수 시스템의 변경 또는 차량 손상 판정 모델의 변경 시 상호간의 영향 최소화
- Queue를 통해 전달하게될 메시지 구조만 협의되면 이후 작업은 메시지를 Push 하거나 Pull 하기만 하면 됩니다.
- 본 시스템은 모델에 판정을 의뢰할 사내 시스템은 판정 대상 이미지의 URL과 기타 정보를 메시지로 묶어 SQS에 Push하면 되고, 판정 모델 쪽은 SQS를 Polling 하면서 요청된 메시지를 받아와 판정 작업을 처리하고 결과를 업데이트하면 됩니다.
3) 이미지 처리량의 변화에 따른 유연한 Scaling 지원
- AWS SQS는 처리량 제한이 없습니다. 다 받아줍니다.
- 다만 메시지 저장 제한 기간이 있으므로, 그 기간 안에 Queue의 메시지를 꺼내가면 됩니다. Push되는 메시지가 많아지는 경우에는 Pull하는 모델의 처리량을 늘려주면 되는데 모델 처리량을 늘리는 방법에 대해서는 잠시 후 설명하도록 하겠습니다.
Model Serving : AWS S3 + Agent(Python Application / Docker) + Kubernetes
손상 판정 모델의 작업은 이미지를 Input으로 받고, 판정 결과가 표시된 이미지와 관련 정보들을 Output으로 리턴합니다. 모델이 판정 작업에 집중하는 동안, 사내 시스템과 여러 작업들을 수행하기 위한 서빙 시스템이 필요합니다. 본 프로젝트에서는, 이러한 서빙 시스템을 Agent로 지칭하도록 하겠습니다.
Agent의 주요 담당 업무는 아래와 같습니다.
- 1) 손상 판정 모델을 초기화
- 2) AWS SQS로부터 메시지를 Pull하고, 모델에 이미지를 전달
- 3) 모델의 판정 결과를 사내 시스템에 전달
- 4) 모델 및 Agent의 상태를 확인하고 로그 저장
Agent는 Python으로 작성하였고, Docker Image로 빌드했습니다. 차량 손상 모델은 PyTorch를 사용하여 개발되었고, Python 코드를 사용 시 다양한 Cloud 플랫폼의 API를 사용하는 것도 쉬우므로 자연스럽게 Python을 선택했습니다.
1) 손상 판정 모델을 초기화
- Agent가 시작되면 S3에 저장된 모델의 Weight 값들을 다운로드하고, 모델의 내부 상태를 초기화 하게 됩니다.
- 차량 손상 판정 모델이 사용하는 내부의 Network Layer가 7개여서 각각 학습된 Weight들을 모아보면 크기가 상당히 큽니다. 해당 Weight들을 Docker Image에 포함하게 된다면 Image가 너무 커질 뿐만 아니라, 향후 Weight 값이 재학습으로 인하여 수정되는 경우 Docker Image를 다시 빌드해야 하는 불편함이 있습니다.
- 이에 따라, Weight 값들은 분리하여 저장하고 Agent가 시작되는 시점에 해당 Weight들을 다운로드받아 사용합니다.
2) AWS SQS로부터 메시지를 Pull하고, 모델에 이미지를 전달
- 모델을 초기화한 후, Agent는 AWS SQS로부터 판정 대상 이미지의 정보가 저장된 메시지를 1개씩 Pull하여, 메시지를 파싱한 후, 모델에 이미지 정보(URL)를 전달합니다.
3) 모델의 판정 결과를 사내 시스템에 전달
- 모델은 이미지를 분석하여 차량의 손상 여부를 판정한 뒤, 손상 영역을 표시한 이미지와 관련 정보들을 Agent에 리턴합니다. 현재 이미지 분석에 소요되는 시간은 장당 3~10초 정도 소요되는데 손상 여부에 따라 판정시간이 조금씩 달라지게 됩니다.
- Agent는 전달받은 결과 이미지를 S3에 저장하고, 관련 정보는 데이터베이스에 저장합니다. 결과 이미지와 데이터베이스의 정보는 사내 시스템에서 관리하는 차량 검수 자동화 시스템에서 사용하게 됩니다.
4) 모델 및 Agent의 상태를 확인하고 로그 저장
- Agent는 작업 간 각종 로그를 생성하여 모델의 상태와 Agent 자체의 상태를 기록하게 되는데 이러한 정보는 Fluentd를 사용해 수집한 후, S3에 저장하고 있습니다.
여기까지 외부 시스템과 차량 손상 판정 모델을 연동할 수 있는 기본 시스템(Agent)은 마련된 상태입니다. 이제 이 Agent를 병렬적으로 운영하여 처리량을 높이는 방법에 대해 설명하도록 하겠습니다.
이미 짐작하시겠지만 Agent는 SQS에 쌓여있는 메시지를 능력껏 받아서 열심히 처리하는 구조이고, Agent가 추가로 하나 더 구성되면 자연스럽게 처리량은 두 배가 됩니다. 이는 각각의 이미지를 판정할 때, 판정 작업간 의존성이 없고, Queue에 저장된 작업의 순서가 특별히 고려될 필요도 없기 때문입니다. 따라서 Agent가 늘어날수록 처리량도 비례하여 늘어납니다.
실 운영에서는 평일과 주말의 차량 이미지 수가 많은 차이를 보이고 있고, 업로드되는 시간대도 주간, 야간, 새벽에 따라 편차가 큰 관계로 Agent의 수를 유연하게 운영할 수 있다면 가장 효과적일 것입니다. 이를 위하여 본 프로젝트에서는 Kubernetes를 사용하고 각각의 Node는 Spot Instance로 지정하였으며, Pod 배포시 Resource Limit을 설정하여 작업량에 따라 유연하게 Scaling이 적용되도록 했습니다.
현재 운영중인 설정에서는 작업이 없을 때 Node 1대에 Agent Pod이 2개가 배포되어 대기하고 있다가, SQS에 메시지가 쌓이기 시작하면 Node 5대에 Pod이 14개 배포될 때까지 Auto Scaling이 동작합니다. 이후, SQS 메시지를 모두 처리하게 되면 다시 처음의 상태로 Node와 Pod의 수가 조정됩니다.
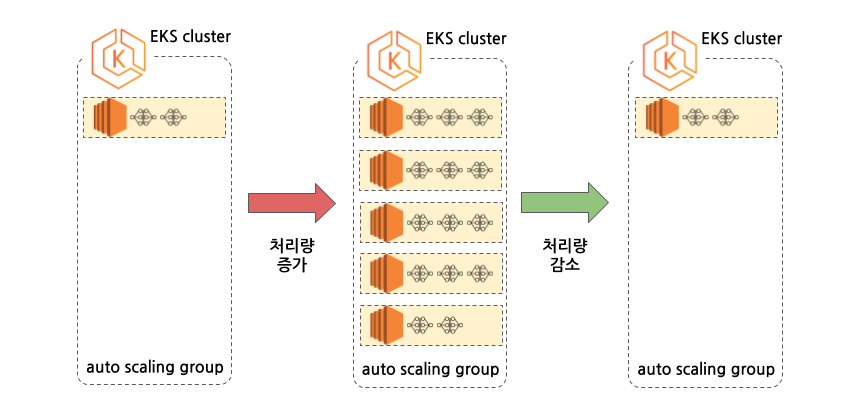
Kubernetes를 사용할 때의 또 다른 잇점은 Pod의 상태를 확인하여 이상이 있는 경우, Pod을 재배포하여 복구시키는 방법이 간편하다는 점입니다.
서빙 Agent의 경우, 사내 시스템과 인터페이스 되는 부분이 다양하므로 오류가 발생할 가능성이 있으며, 특히 내부의 손상 판정 모델이 리소스를 상당히 소모하는 과정에서 예기치 못한 오류를 일으킬 가능성도 있습니다. 일반적인 오류는 예외처리를 통해 문제를 해결할 수 있으나 Agent가 좀비상태가 되어 떠 있는 경우도 있을 수 있어, Kubernetes의 livenessProbe를 이용하여 Agent의 비정상 상태를 탐지할 수 있도록 했습니다.
Agent는 주기적으로 SQS를 Polling하고 메시지에 따라 이 후 작업을 진행하게 되는데 이 때 주기적으로 Heartbeat 파일을 생성하도록 구현했습니다. 그리고 Kubernetes는 이 Heartbeat 파일이 일정시간 이상 계속 업데이트가 되지 않는 상태이면, 해당 Agent를 제거하고 새로운 Agent(Pod)를 배포하도록 설정했습니다.
그리고 동작 중 발생하는 오류에 대해서는 슬랙 채널로 알림을 발송하도록 처리했습니다.
서빙 관련 배포 및 모니터링: Git + Rancher
엔지니어의 욕심은 끝이 없는 법. Kubernetes가 엔지니어의 삶을 편안하게 도와주긴 하지만 배포도 좀 더 간단하면 어떨까 생각을 해봅니다. 배포 및 모니터링을 위한 다양한 툴들이 있는데, 데이터 엔지니어링팀에서는 요즘 꽤 핫한 Rancher를 사용하는 것으로 결정하였습니다. 이미 개발본부에서 Rancher를 배포 및 모니터링에 적극 활용하고 있는 모습을 볼 수 있었기 때문에 팀에서도 별다른 고민 없이 채택할 수 있었습니다. 일단 사용해 본 결과로는 조금 보완할 점도 있긴 하지만, 전반적으로 만족하며 사용하고 있습니다. Rancher와 함께 Git을 연동하면 다음과 같은 운영상의 편리함이 있습니다.
- 1) Git에 소스를 push하면 docker image 빌드부터 Kubernetes 배포까지 한방에!
- 2) 복잡한 설정 없이 간편하게 Node와 Pod 상태 모니터링 및 로그 확인 가능
1) Git에 소스를 push하면 docker image 빌드부터 Kubernetes 배포까지 한방에!
- Git 브랜치는 master, release, develop로 구분하여 운영하고 있습니다.
- 각자의 기능 개발은 develop-xxxx 브랜치를 생성하여 작업하고 develop 브랜치에 리뷰 후 머지됩니다.
- 개발된 기능들이 모이게 되면 develop 브랜치의 내용이 release 브랜치로 Pull Request 요청에 의해 머지가 됩니다.
- Rancher에서는 설정된 Git 브랜치에 이벤트가 발생하면 빌드 Pipeline을 Trigger 할 수 있는 기능이 있습니다. 위와 같이 release 브랜치에 새로운 소스가 머지되면 해당 브랜치의 소스를 다운하여 Docker Image를 빌드하고 지정된 위치에 업로드 할 수 있도록 설정이 가능합니다. 쏘카에서는 release 브랜치 머지의 결과를 stage에 배포하도록 설정되어 있습니다.
- stage에 배포된 서빙 모델이 별도의 테스트를 통해 정상적으로 동작하는 것으로 확인되면 release 브랜치를 master 브랜치에 머지합니다.
- 이후, 새 버전에 해당하는 Tag를 달게 되면 해당 Tag로 Docker Image를 빌드하여 production에 배포하도록 설정했습니다. 운영상의 실수로 master 브랜치에 의도하지 않게 소스가 머지될 수도 있으므로 명시적으로 Tag를 작성하는 경우에만 production에 배포가 됩니다.
- 결과적으로 Git 관련 작업만으로 서빙 모델이 보다 간편하게 배포될 수 있는 구성이 가능합니다. 한가지 유의하실 점은, Tag가 변경되지 않으면 Rancher Pipeline에서 해당 Docker Image의 배포가 Skip 되므로 Image의 Tag는 수정이 되어야 합니다. 만약 latest 등의 Tag를 사용하는 경우에는, Rancher UI 상에서
Redeploy를 클릭하여 수동으로 재배포할 수 있습니다.
2) 복잡한 설정 없이 간편하게 Node와 Pod 상태 모니터링 및 로그 확인 가능
- Rancher는 간단한 설정만으로 Node, Pod 상태를 모니터링 할 수 있는 기능을 제공합니다.
- 보다 상세한 상태를 파악하기 위해서는 Prometheus, Grafana 등을 사용하여 모니터링 할 수도 있으나, 본 프로젝트에서는 Node가 Spot Instance로 동작하고 있어서 Node의 수가 가변적으로 운영되고 있고, 현재 동작중인 상태만 간단히 확인할 수 있는 정도면 되기 때문에 Rancher가 제공하는 기본 모니터링 기능만을 사용하여 운영중입니다. 아래 그림에서와 같이 CPU, Memory, Storage, Network 사용량 등을 한눈에 확인할 수 있습니다.
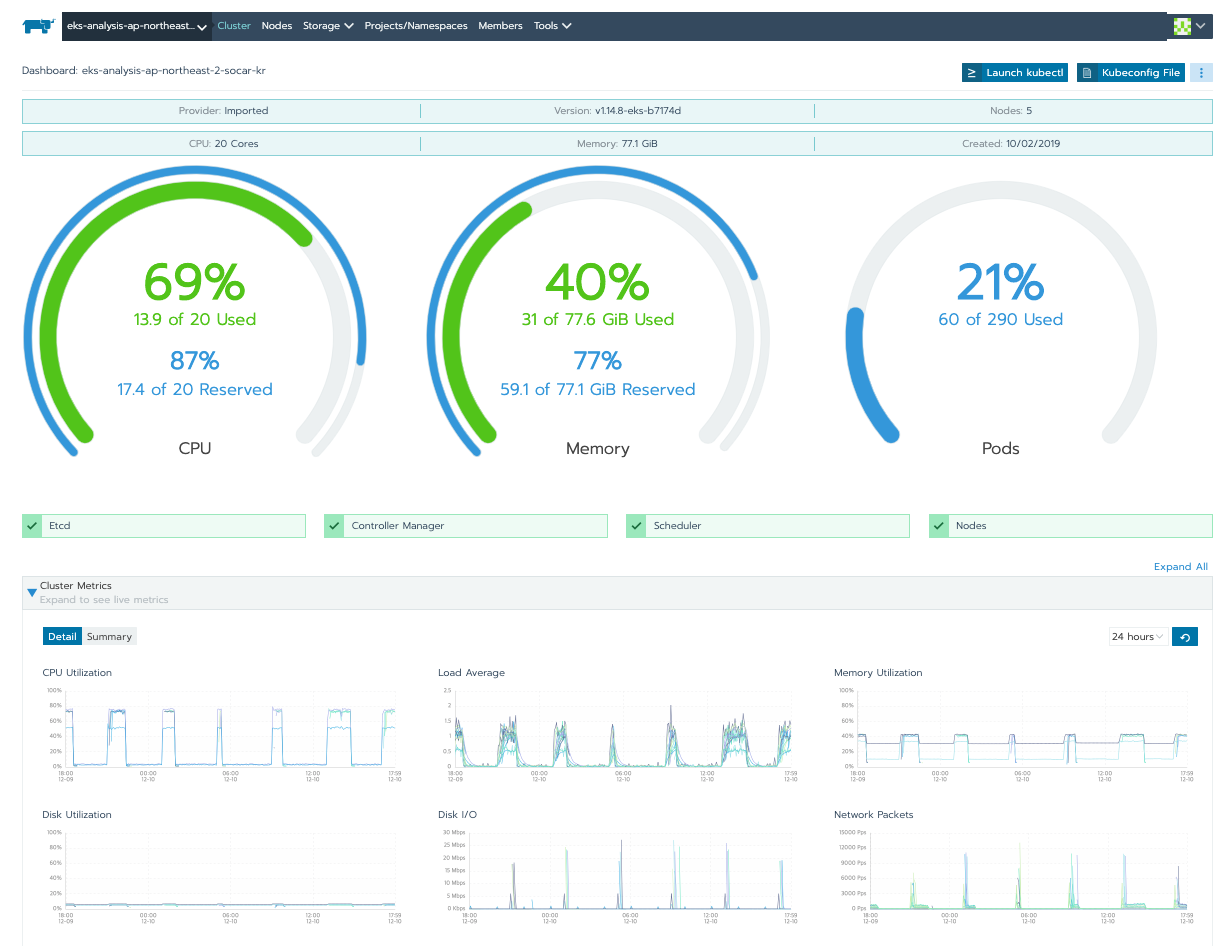
현재 서빙 시스템의 로그는 Fluentd를 이용하여 별도의 S3 버킷에 저장하고 있습니다. 실시간 로그를 확인하여 Pod의 상태를 보고 싶은 경우 Rancher UI 상에서 쉽게 확인 가능합니다. 아래 그림과 같이 stdout으로 기록되는 로그를 붙잡아서 볼 수 있으므로 서빙 시스템의 상태를 간단히 체크하거나, 버전이 업데이트 되어 배포되는 시점에 동작 상태를 실시간으로 확인하기에 좋습니다.
이제 큐가 비었습니다
DL 모델 서빙 시스템을 구축하기 위해 사용된 주요 서비스와 연동 방법들에 대해 간단히 정리해 보았습니다. 본문 내용을 세 줄로 요약한다면 아래와 같습니다.
- 검수 시스템과 모델은 커플링 최소화를 위해 AWS SQS를 이용하여 인터페이스 구축
- Kubernetes를 이용한 Scaling 및 안정성 확보
- Rancher와 Git을 이용한 배포 자동화 이제 8만장이 아니라 80만장도 처리 가능합니다!
약 한 달 정도의 기간내에 빠르게 서빙 시스템을 구축하는 것이 목표였으므로, 기존 쏘카의 시스템과 연동이 쉽고 가볍게 개발 가능한 수준의 시스템을 구성했습니다. 그로 인하여 더 깊이있는 내용을 고려하지는 못하였으나, 일단 원하는 목표는 만족스럽게 달성했다고 생각합니다.
현재 딥러닝 모델의 학습은 별도의 시스템에서 이루어지고, 이후 학습이 완료된 모델을 적용하는 단계부터 서빙 시스템이 구축된 상태입니다. 앞으로는 모델의 성능을 모니터링하며, 신규 차량 이미지들을 학습에 적용하여 모델의 성능을 지속적으로 개선할 수 있는 시스템으로 확장할 예정입니다.
끝까지 읽어주셔서 감사합니다.