 세레나
세레나쏘카에서 2019년 하반기에 딥러닝 기반의 차량 파손 탐지 모델을 개발했습니다. 이 포스트를 통해 왜 차량 파손 탐지 모델을 만들게 되었는지, 어떤 고민들을 거쳐 요구사항을 설정하였는지, 어떤 기술들이 사용되었는지 등 프로젝트의 전반적인 내용을 소개하는 글입니다.
목차
- 차량 파손 탐지 모델을 만들게 된 배경
- 문제 해결 방식
- 문제 접근 방식 정의 - Semantic Segmentation
- 데이터 정의 및 준비 - 입력 데이터와 출력 데이터
- 사용한 모델의 구조
- 모델 학습(Training) 과정
- 모델 Inference(Prediction) 후처리
- 실제 데이터 검증 시 생긴 문제
- 성능 평가
- 실제 데이터에 적용 예시
- 추후 발전 방향
- Reference
차량 파손 탐지 모델을 만들게 된 배경
먼저 사용자가 쏘카 앱을 통해 쏘카를 대여하고 운행하는 과정을 알아보겠습니다.
- 1) 사용자가 차량을 이용할 쏘카존을 선택합니다.
- 2) 원하는 시간을 선택하고,
- 3) 원하는 차량을 선택하게 됩니다.
- 4) 약속한 이용 시간이 가까워지면 선택한 쏘카존에 방문해, 차량의 상태를 확인합니다.
- 이때 사용자는 차량의 당시 외관 사진을 앱 내에 업로드해야 합니다.
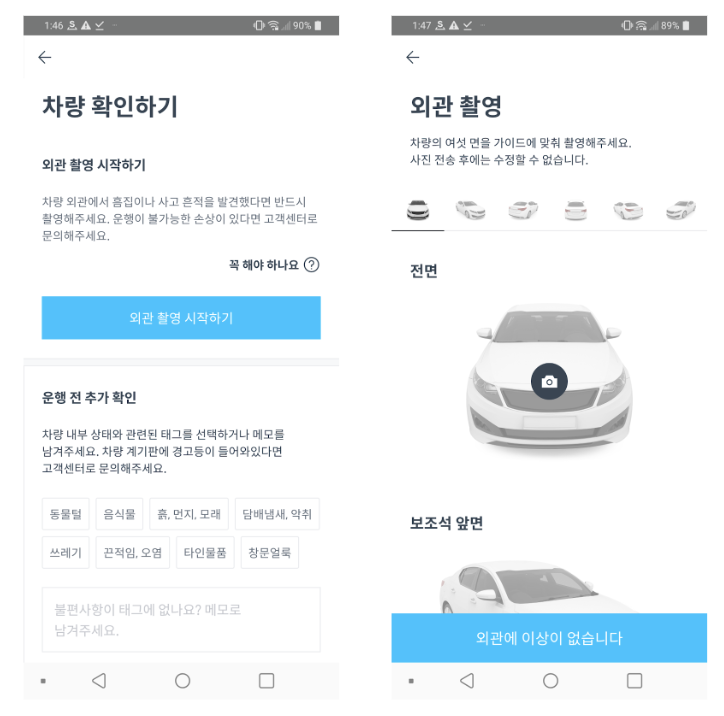
- 5) 문제가 없는 경우, 운행을 시작합니다.
발생할 수 있는 문제
쏘카는 카셰어링 업체로, 고객에게 차량을 대여하는 회사입니다. 따라서 차량은 쏘카의 가장 중요한 자원이기 때문에, 차량의 파손 상태를 꾸준히 모니터링하는 것은 반드시 해야 할 일 중 하나입니다.
차량의 파손에 대한 히스토리를 가장 잘 제공하는 데이터는 고객이 차량 후 상태 확인 과정에서 업로드하는 차량의 외관 이미지라고 판단해 이 데이터를 활용하기로 결정했습니다.
- “여기에 이만큼 파손이 있으니, 정비소에 맡겨라.”의 의미가 될 수도 있고,
- “내가 차를 받기 전에 이미 파손이 있었다. 내가 긁은 거 아니다.” 의 의미가 될 수도 있겠습니다.
- 즉, 차량의 파손 정도, 위치, 시점 등 히스토리가 고스란히 담겨있는 데이터로 활용될 수 있습니다.
하지만 기존 업무 프로세스는 업무 담당자분들이 차량 외관 이미지를 직접 검수했습니다. 직접 확인하기 때문에 많은 시간이 소요됐기 때문에 이 작업은 회사와 담당자에게 굉장히 큰 업무 부담으로 다가왔습니다.
- 일평균 7-8만장, 최대 11만장의 차량 외관 이미지가 업로드되기 때문에 검수할 분량이 꽤 있습니다.
검수에 착수할 사진이 많기 때문에 충분한 리소스 투입이 어려웠습니다. 그리고 이미지 데이터가 차량의 파손 상태를 모니터링하는 용도보다, 파손 신고 시 업무 담당자의 파손 시점 추적에 주로 사용되었습니다.
파손 시점 추적은 담당자가 직접 차량의 외관 이미지를 현재부터 과거로 추적하며 파손 시점을 찾아내는 식으로 진행되었습니다.
문제 해결 방식
위에도 언급했듯이, 차량 외관 이미지 데이터를 파손 시점 추적 용도로만 주로 사용하기에는 아쉬운 점이 존재했습니다.
결국 차량 외관 이미지를 적극적으로 활용하지 못한 이유는 업무 리소스를 할당하기에 부담이 크기 때문인데, “반드시 검수 작업을 수기로 진행해야 하는가?”에 대한 의문이 들었습니다.
- “반드시 사람이 눈으로 봐야만 검수를 할 수 있는 걸까?”
- 이러한 고민들 끝에, 딥러닝 모델을 이용한 차량 파손 탐지 자동화 프로젝트를 진행했습니다.
- 주어진 차량 이미지 내의 파손 영역과 파손의 종류를 자동으로 판단하는 딥러닝 모델의 구현을 프로젝트의 목표로 설정했습니다.
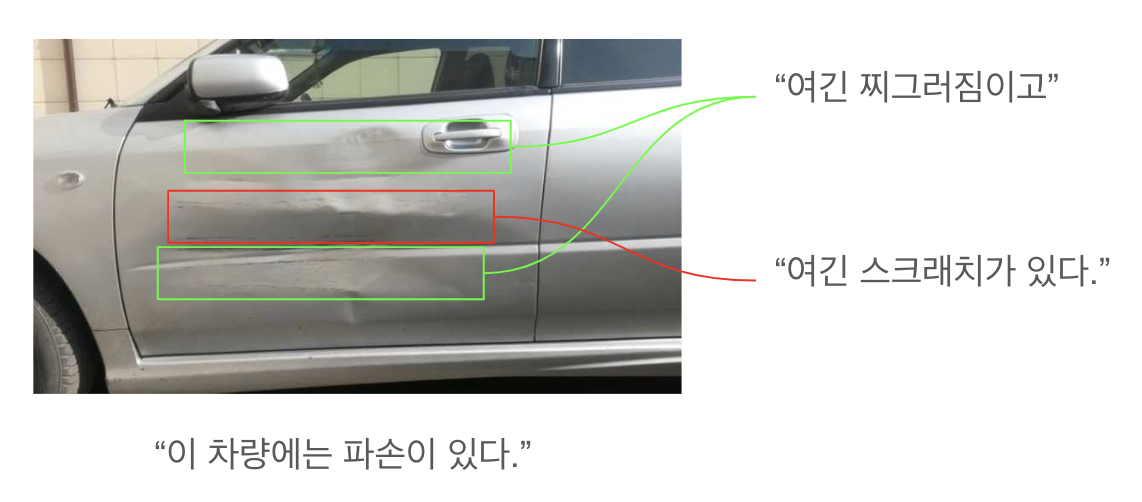
프로젝트의 목적을 정의했고, 조금 더 구체화할 부분은 다음과 같습니다
- 딥러닝 분야의 다양한 문제 접근 방식 중, 어떤 Task인지?
- 어떤 데이터를 사용할 것인지?
- 어떤 구조의 모델을 사용하여 문제 해결 목표를 달성할 것인지?
문제 접근 방식 정의 - Semantic Segmentation
본격적으로 프로젝트 시작 전, 프로젝트가 어떤 Task인지 정의했습니다.
딥러닝을 이용한 이미지 처리 분야에서 가장 자주 다루게 되는 Task는 다음과 같습니다.
1. Classification
- 입력으로 주어진 이미지 안의 객체(Object)의 종류(Class)를 구분하는 Task입니다.
- 예시) MNIST 데이터 세트의 경우, 0부터 9까지 총 10가지의 숫자들을 각각의 Class로 구분.
2. Localization
- 입력으로 주어진 이미지 안의 객체가 이미지 안의 어느 위치에 존재하는지 위치 정보를 판단하는 Task입니다.
- 위치 정보의 형태는 주로 Bounding Box를 많이 사용합니다.
3. Object Detection
- 일반적으로 Classification과 Localization을 동시에 수행합니다.
- 입력으로 주어진 이미지 안의 객체 위치(Localization)와 해당 객체의 종류(Classification)를 출력하는 Task입니다.
4. Segmentation
- Segmentation은 픽셀을 대상으로 한 Classification 문제로 접근할 수 있습니다.
- 입력으로 주어진 이미지 내에서 각 픽셀이 어떤 클래스에 속하는지 분류합니다.
- 각 픽셀의 분류된 클래스는 모델이 생성한 결과물인 예측 마스크 (mask)에 픽셀 단위로 기록됩니다. 만일 특정 픽셀이 어떤 클래스에도 해당하지 않는 경우, Background 클래스로 규정해 0을 표기하는 방식을 사용합니다.
- 분할의 기본 단위를 무엇으로 설정하느냐에 따라, Segmentation의 세부 문제를 나눌 수 있습니다.
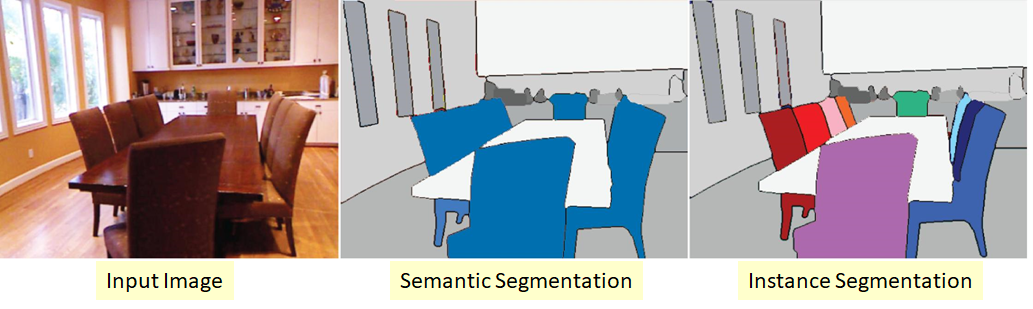
- Instance Segmentation
- 분할의 기본 단위를 사물로 설정한 분할 문제입니다.
- 만일 두 개 이상의 사물이 동일한 클래스에 속하더라도, 서로 다른 사물에 해당하면 이들은 서로 다른 예측 마스크값을 가집니다.
- Semantic Segmentation
- 분할의 기본 단위를 클래스로 설정한 분할 문제입니다.
- 만일 두 개 이상의 사물이 동일한 클래스에 해당하면 이들은 서로 같은 예측 마스크값을 가집니다.
다시 정리하면 모델은 주어진 차량 이미지 내의 파손 영역과 파손 종류를 픽셀 단위로 분류해야 합니다.
이미지 단위가 아닌 픽셀 단위로 “이 픽셀이 파손에 해당하는가?”에 대한 판별이 필요하기 때문에 Segmentation 문제에 속하며, 서로 떨어져 있는 파손 영역이라도 동일한 종류의 파손일 경우 클래스에 기반하여 하나의 동일한 예측 마스크값을 가져야 합니다.
이러한 점들을 고려했을 때, 모델이 수행해야 하는 행위를 기술적으로 분류 시, Semantic Segmentation에 속한다고 설정할 수 있습니다.
데이터 정의 및 준비
입력 데이터와 출력 데이터
머신러닝/딥러닝 모델 학습에 필요한 데이터의 구조는 입력 데이터와 출력 데이터, 즉 Feature와 Label로 구분할 수 있습니다.
입력 데이터는 분석의 대상이 되는 데이터로, 알파벳 X로 표기합니다. 이는 독립변수, 설명변수라는 용어로 사용되기도 하며, 해당 포스트에서는 Feature라는 용어로 표현하겠습니다.
출력 데이터는 문제 해결을 위해 예측의 결과로 나타나는 데이터로, 알파벳 Y로 표기합니다. 이는 종속변수라는 용어로 사용되기도 하며, 해당 포스트에서는 Label 또는 Target이라는 용어로 표현하겠습니다.
데이터 측면에서 정의가 필요한 점들은 다음과 같습니다.
- 이미지 단위의 파손 존재 여부 (이미지 전체에서 파손이 존재하는지)
- 픽셀 단위의 파손 클래스 분류
- 스크래치 (Scratch) : 차량에 스크래치가 난 영역
- 찌그러짐 (Dent): 차량이 찌그러진 영역
- 이격 (Spacing): 차체 패널이 벌어져 들뜸, 틈이 생긴 영역
- 해당 없음 (Background): 파손이 존재하지 않는 영역
따라서 입력 데이터(Feature)는 차량 이미지가 될 것이며, 출력 데이터(Label)는 이미지 단위 파손 존재 여부와 픽셀 단위 파손 클래스 분류가 됩니다.
사용자가 쏘카 앱 내에서 업로드한 이미지 중 육안으로 파손의 여부를 확실하게 판단할 수 있는 이미지 2,000장에 대해 Label을 정의했고, 형식은 다음과 같습니다.
- image_id: 이미지 파일명
- damage_level: 이미지 단위 파손 존재 여부. 파손이 존재할 경우 1, 파손이 존재하지 않을 경우 0
- regions: 파손 영역 단위 파손 클래스 분류
- 데이터 관리의 편리함을 위해 픽셀 단위로 정의하는 mask 방식이 아닌, 영역 단위로 정의하는 polygon 방식을 채택했습니다. 학습 시, 해당 polygon 정보를 픽셀 단위 mask로 변환해 이용했습니다.
- points: 해당 파손 영역의 외곽선 좌표 배열
- class_name: 해당 파손 영역의 종류
- 0: 해당 없음 (Background)
- 1: 스크래치 (Scratch)
- 2: 찌그러짐 (Dent)
- 3: 이격 (Spacing)
{"image_id": "20190218_12985_20129968_2e0da3c3e2ace9c780abb1eeb060d43f.jpg",
"damage_level": 1,
"regions": [
{
"points": [
[245.0, 260.0], [285.0, 228.0], [333.0, 211.0], [390.0, 209.0],
[448.0, 216.0], [538.0, 184.0], [594.0, 174.0], [595.0, 204.0],
[524.0, 220.0], [475.0, 240.0], [464.0, 291.0], [453.0, 366.0],
[424.0, 415.0], [379.0, 448.0], [312.0, 456.0], [271.0, 442.0],
[221.0, 377.0]
],
"class_name": 1,
}
]
}
Dataset 분리
이렇게 정의된 데이터를 이용 목적에 따라 분리했습니다. 전체 2,000개 데이터를 학습용 데이터(Training Set), 검증 및 모델 선택용 데이터(Validation Set), 실제 테스트용 데이터(Test Set)로 나누었고, 그 비율은 8:1:1로 설정했습니다.
데이터 세트 분리 시, 특정 데이터 세트에 데이터가 편향되는 것을 막기 위해 Stratified Split을 사용했습니다.
데이터가 편향되는 것은 찌그러진 파손에 해당하는 이미지 대부분이 Validation set에만 포함되어 있으면 학습시 해당 특징이 모델에 충분히 반영되지 못하는 경우를 의미합니다.
해당 프로젝트에서는 파손 클래스와 전체 이미지 면적 대비 파손 영역이 차지하는 면적 비율이 편향되지 않도록 설정해 Training Set, Validation Set, Test Set으로 분리했습니다.
모델 정의
U-Net 모델과 구조
해당 프로젝트에서는 Semantic Segmentation Task 수행을 위하여 U-Net with EfficientNet 모델을 사용했습니다.
- U-Net이란?
- U-Net은 Semantic Segmentation Task 수행에 널리 쓰이는 모델 중 하나입니다.
- 네트워크 형태가 알파벳 U와 비슷하다고 하여 붙여진 이름으로, 의생명공학 이미지 Segmentation을 위해 개발된 모델입니다.
- 모델의 구조는 다음과 같습니다.
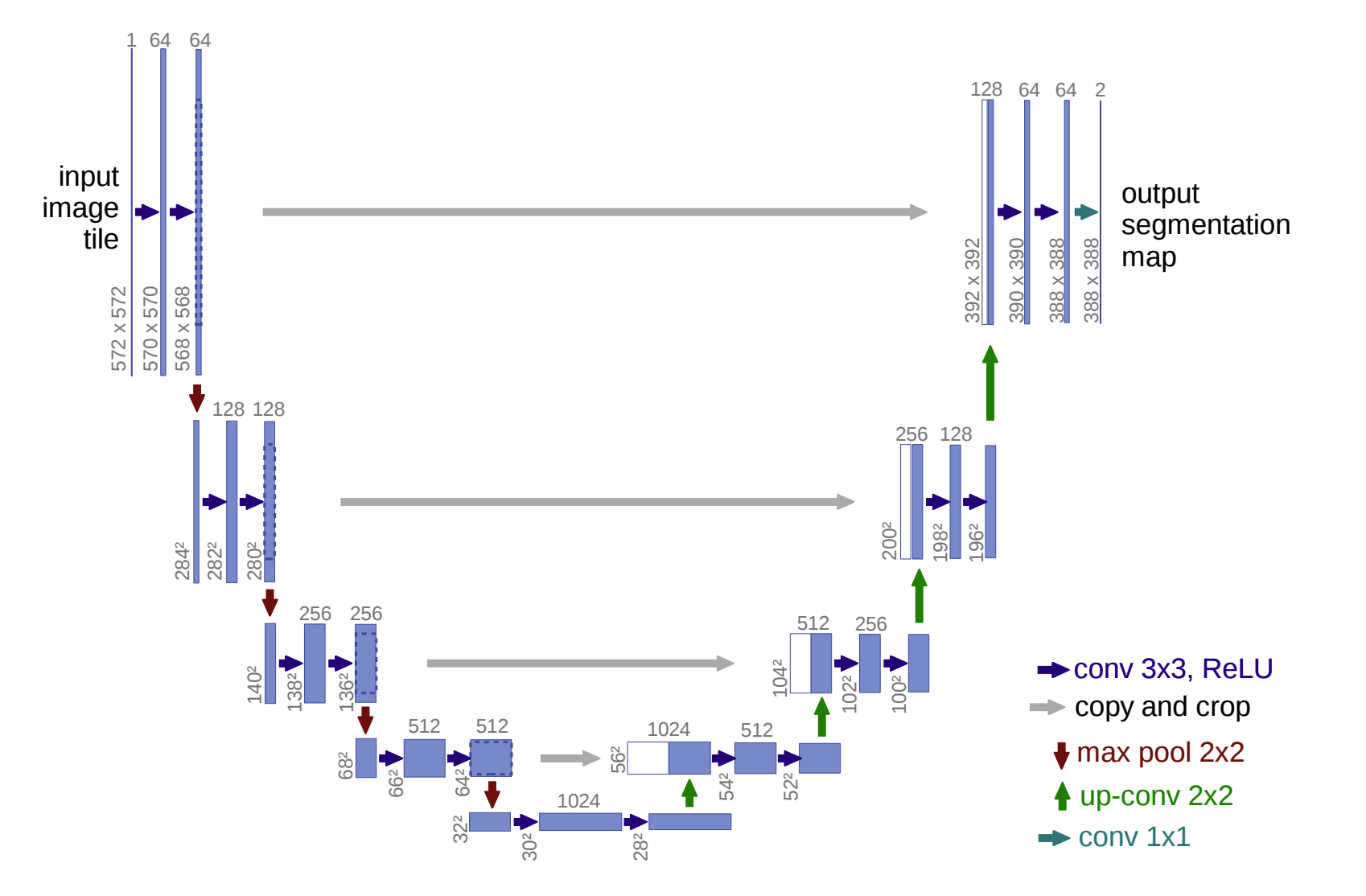
- U-Net의 장점
- U-Net은 기존의 Segmentation 모델의 문제점을 해결할 수 있습니다
- 1) 빠른 속도
- 기존 Segmentation 모델의 단점이었던 느린 연산 속도를 개선했습니다.
- 속도 개선이 가능했던 이유는, 이미지를 인식하는 단위(Patch)에 대한 Overlap 비율이 적기 때문입니다.
- 기존의 모델에서 많이 사용되었던 Sliding Window 방식의 경우, 이전 Patch에서 검증이 끝난 부분을 다음 Patch에서 다시 검증하게 됩니다. 이는 일종의 연산 낭비라고 볼 수 있습니다.
- U-Net의 경우, 이전 Patch에서 검증이 끝난 부분을 다음 Patch에서 중복하여 검증하지 않기 때문에, 연산의 낭비가 없고 이로 인해 향상된 속도를 얻을 수 있습니다.
- 2) Context와 Localization의 늪에서 탈출
- Segmentation Network는 클래스 분류를 위한 인접 문맥 파악(Context)과 객체의 위치 판단(Localization)을 동시에 수행해야 합니다. 각 성능은 Patch의 크기에 영향을 받는데, 이때 Trade-Off 관계를 가지게 됩니다.
- Patch의 크기가 커지면 더 넓은 범위의 이미지를 한 번에 인식할 수 있어 Context 파악에는 탁월한 효과를 보이지만, 많은 Max-Pooling을 거치며 Localization 성능에는 부정적인 영향을 미치게 됩니다.
- 반대로 Patch의 크기가 작아지면 Localization 성능은 좋아지나, 인식하는 범위가 지나치게 협소해져 Context 파악 성능에 좋지 않은 영향을 미칩니다.
- U-Net은 다층의 Layer의 Output을 동시에 검증해서 이러한 Trade-Off를 극복합니다.
- U-Net with EfficientNet
- U-Net의 구조는 알파벳 U의 왼쪽 절반에 해당하는 Contracting Path와 오른쪽 절반에 해당하는 Expanding Path의 2가지 Path로 분리할 수 있습니다.
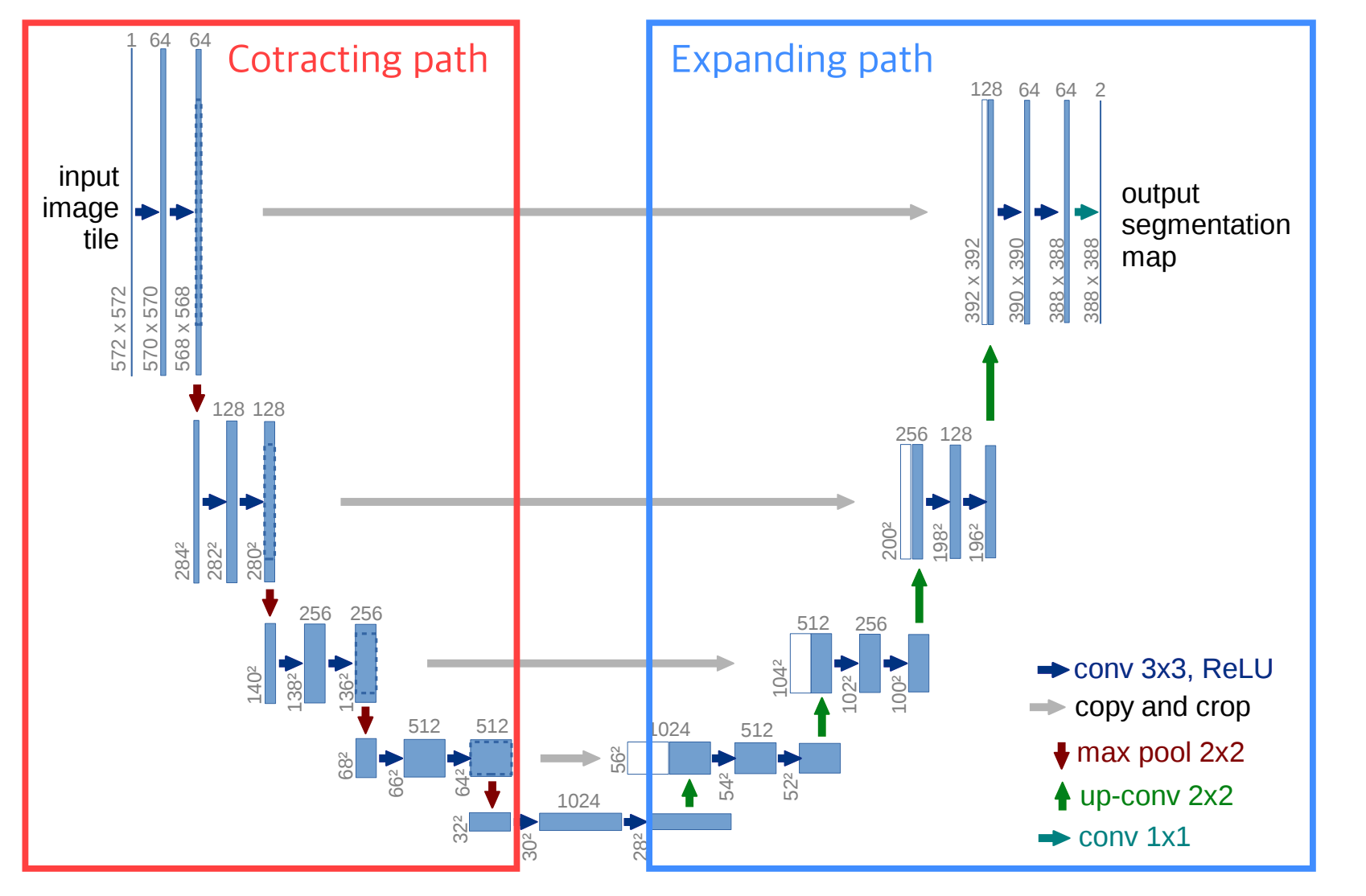
- 1) Contracting Path
- Contracting Path는 Encoder의 역할을 수행하는 부분으로 전형적인 Convolution Network로 구성됩니다.
- Contracting Path는 입력을 Feature Map으로 변형해 이미지의 Context를 파악합니다.
- 이 경우에 Contracting Path의 앞단에 이미 잘 학습된 모델을 Backbone으로 사용해 학습 효율과 성능을 높일 수 있습니다. 주로 ResNet 등의 모델을 사용합니다.
- 해당 프로젝트에서는 ImageNet 데이터 세트로 학습된 EfficientNet을 Contracting Path의 Backbone으로 사용했습니다.
- 2)Expanding Path
- Expanding Path는 Decoder의 역할을 수행하는 부분으로, 전형적인 Upsampling + Convolution Network로 구성됩니다.
- 즉, Convolution 연산을 거치기 전 Contracting Path에서 줄어든 사이즈를 다시 복원하는(Upsampling) 형태입니다.
- Expanding Path에서는 Contracting을 통해 얻은 Feature Map을 Upsampling하고, 각 Expanding 단계에 대응되는 Contracting 단계에서의 Feature Map과 결합해서(Skip-Connection Concatenate) 더 정확한 Localization을 수행합니다.
- 즉, Multi-Scale Object Segmentation을 위하여 Downsampling과 Upsampling을 순서대로 반복하는 구조입니다.
U-Net을 선택한 이유
- 모델 선택 과정에서 고려 대상이 되었던 모델은 Semantic Segmentation 분야에서 가장 널리 사용되고 있는 U-Net 모델과 DeepLab V3 모델입니다.
- 일차적으로 두 모델의 성능을 정량적으로 나타내고 싶었으나, 각 모델이 개발된 목적이 달랐고, 논문에 성능 평가를 위해 사용된 지표가 일치하지 않아 정량적인 표현이 어려웠습니다.
- U-Net 모델의 경우 의학 이미지 Segmentation을 주목적으로 개발된 모델이고, 그에 따라 일반적인 논문에서 사용되는 Pascal VOC 2012, COCO 등의 지표가 아닌 EM Segmentation Challenge의 지표를 사용했기 때문입니다.
- 또, 만일 모델의 성능을 정량적으로 비교 가능했다고 해도, Pascal VOC 등 범용 데이터와 해당 프로젝트에서 다뤄야 하는 데이터의 특성이 아주 다르기 때문에, 해당 지표를 100% 의존해 모델을 선택하는 것은 바람직하지 않다고 생각했습니다.
- 따라서 비교를 위해 두 가지 모델에 대해 데이터 전처리, 하이퍼 파라미터 튜닝 등을 배제한 순수 베이스라인을 구현하였고, 프로젝트 샘플 데이터를 이용해 학습 및 성능을 평가했습니다.
- 베이스라인 성능 비교 결과 DeepLab v3은 mIOU 80.7, U-Net은 mIOU 92.2를 기록했습니다.
- 위의 성능 비교 결과를 통해 해당 프로젝트에선 U-Net을 이용한 Semantic Segmentation이 더 효과적이라 판단했고, 추후 개발 과정에서 U-Net을 사용했습니다.
모델 학습(Training) 과정
일반적인 머신러닝/딥러닝 모델 학습 과정은 다음 그림과 같습니다.
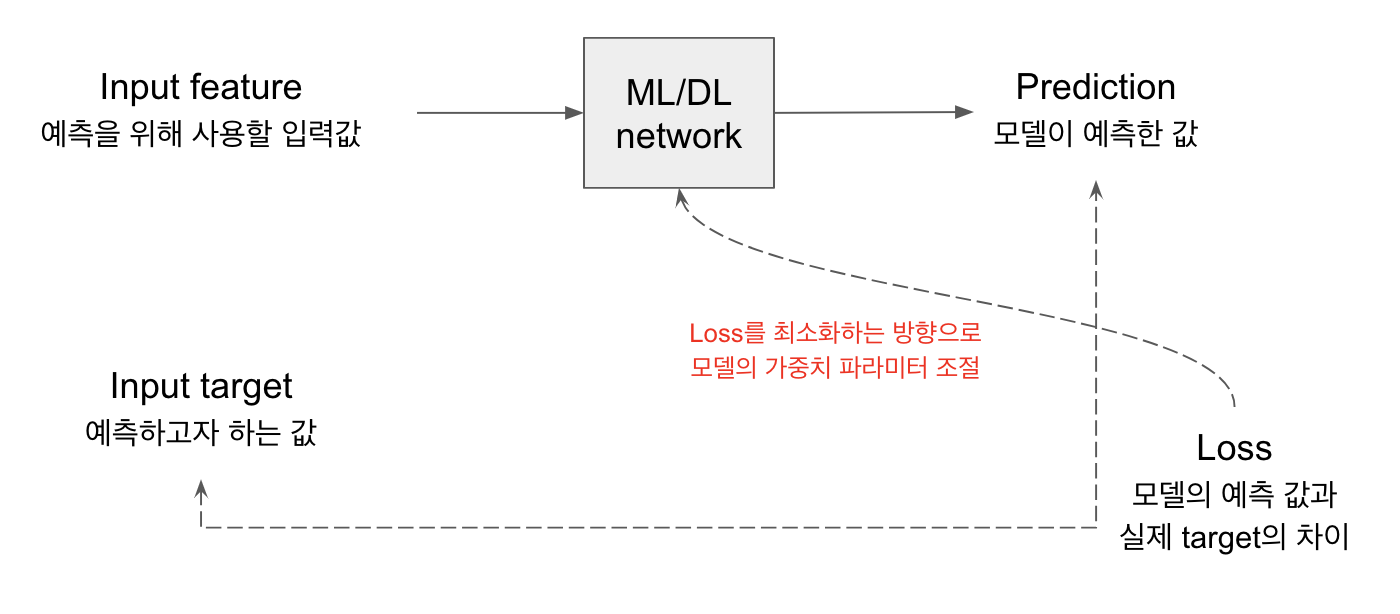
- Feature를 입력으로, 모델의 각 계층(Layer)의 파라미터와의 연산을 통해 예측값을 도출합니다. (Prediction)
- 모델이 예측한 값과 실제 값(Target)이 얼마나 차이가 있는지 (Loss) 계산합니다.
- 이 차이(Loss)를 최소화하는 방향으로 모델 각 계층의 파라미터를 조절하여 최적화하게 됩니다.
해당 프로젝트에서 사용한 모델의 학습 과정은 다음 그림과 같습니다.
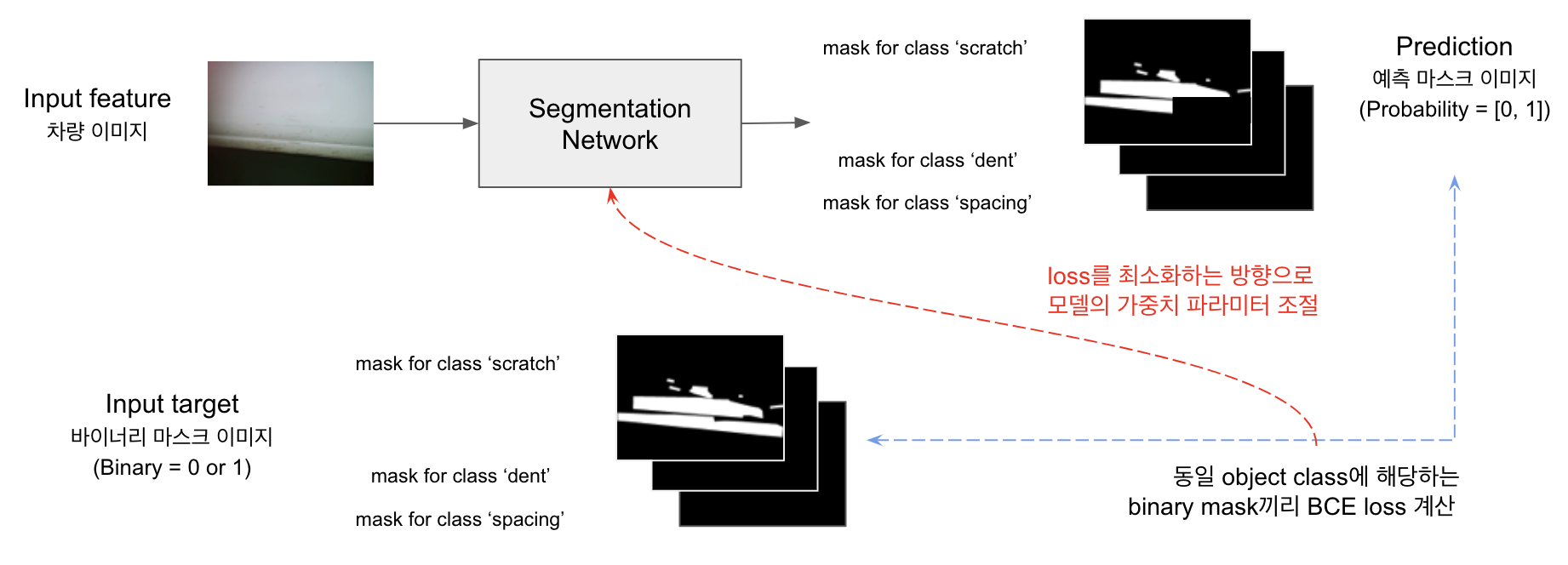
- Feature는 차량 이미지, Target으로는 마스크(Binary Mask Image)가 사용됩니다.
- 파손 영역별 좌표 형태(Polygon)로 주어진 입력 파일을 마스크 형식으로 가공합니다.
- 가공 방법은 다음과 같습니다.
- 파손 영역별로 분리된 좌표 형태를 마스크 형식으로 변환합니다. 이 과정을 통해 각 파손 영역별로 한 장의 2차원 마스크가 생성됩니다.
- 동일한 파손 클래스를 가지는 마스크들을 모아 한 장의 2차원 마스크로 병합합니다. (Logical OR 연산) 이 마스크는 0과 1로 이루어진 이진 마스크로, 1로 표시된 픽셀의 경우 해당 파손 클래스에 속하는 픽셀임을 뜻합니다.
- 위의 과정을 거쳐 하나의 파손 클래스당 한 장, 총 3장의 2차원 이진 마스크를 가지게 됩니다.
- 주어진 차량 이미지를 입력으로, Segmentation Network 내부 파라미터와의 연산을 통해 예측값이 출력됩니다.
- 출력되는 값은 Target과 동일한 형태로 3장의 2차원 예측 마스크의 형태를 가집니다.
- 출력되는 예측 마스크는 이진(Binary) 마스크가 아닌, 대응되는 입력 이미지의 픽셀별로 해당 파손 클래스에 속할 확률(Probability Score)을 나타내는 마스크입니다. 0 이상 1 이하의 확률값이 저장되게 됩니다.
- 각 파손 클래스마다 해당 클래스의 Target 마스크와 예측 마스크 사이의 오차를 계산합니다.
- 오차 계산을 위해 Binary Cross Entropy(BCE) 함수를 사용합니다.
- 이 오차를 최소화하는 방향으로 Segmentation Network의 내부 파라미터를 조정하며 최적화를 진행합니다.
모델 Inference(Prediction) 후처리
학습을 마친 모델을 이용해, 실제로 모델의 예측값을 얻는 과정을 Inference(Prediction)라고 합니다.
해당 프로젝트에서 사용한 모델의 Inference 과정은 다음 그림과 같습니다.
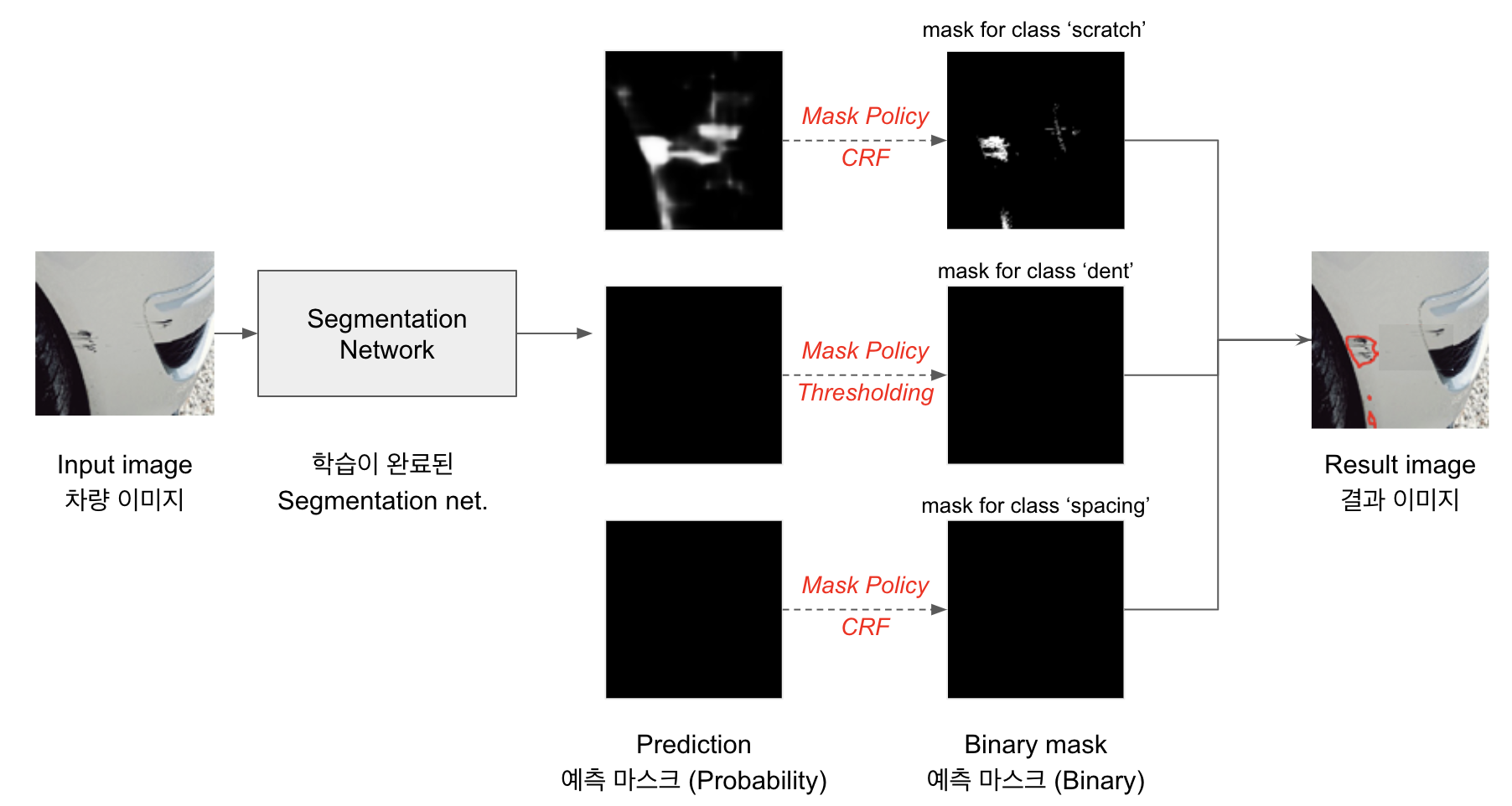
- 차량 이미지를 입력으로, 학습이 완료된 Segmentation Network 내부 파라미터와의 연산을 통해 모델의 예측값이 출력됩니다.
- 출력되는 예측값은 3장의 2차원 예측 마스크입니다.
- 예측 마스크의 각 픽셀은 대응되는 입력 이미지의 픽셀이 해당 파손 클래스에 속할 확률(Probability Score)을 저장하고 있습니다.
-
이 예측 마스크는 Mask Policy에 의해 0과 1의 이진 마스크로 변환됩니다. 0과 1 사이의 연속적인 확률값을 속한다, 속하지 않는다는 이산적인 클래스 정보로 변환하는 과정을 거칩니다.
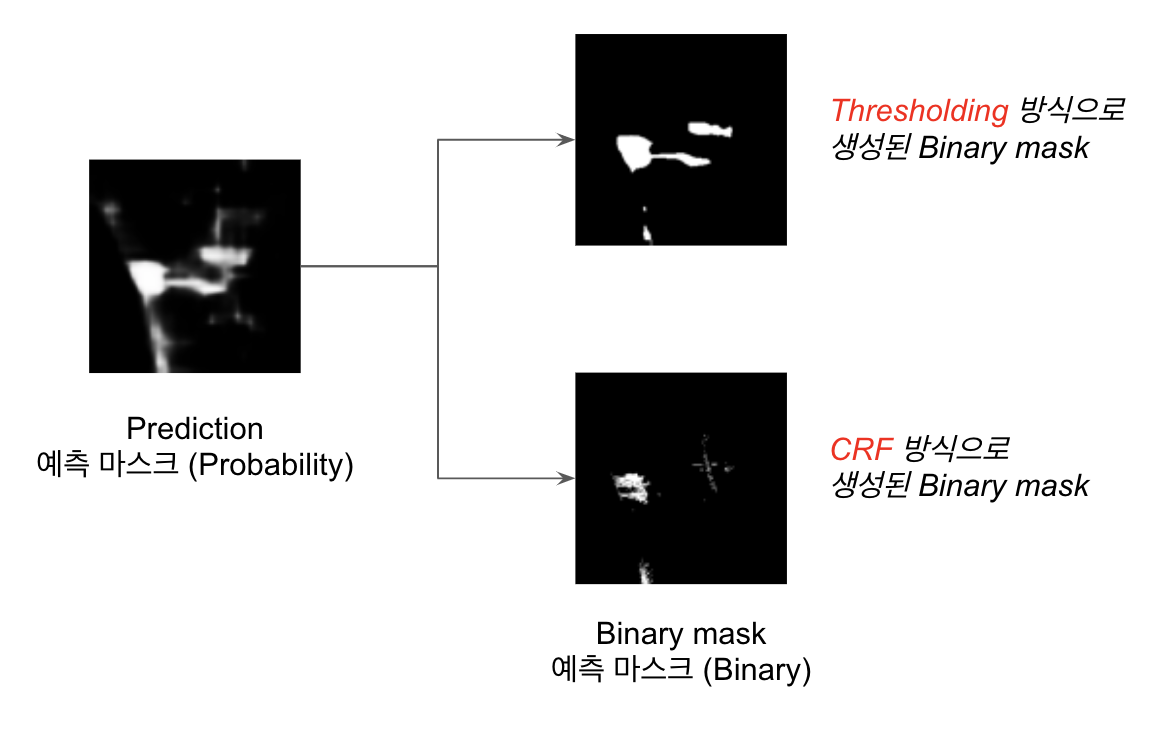
- 해당 프로젝트에서 고안해 사용한 Mask Policy는 각 파손 클래스 별 특성을 반영한 규칙입니다.
- 프로젝트에서 다룬 파손의 종류는 스크래치 (Scratch), 찌그러짐 (Dent), 이격 (Spacing) 총 3가지인데, 이 파손들의 속성이 서로 다르다고 생각했습니다.
- 스크래치와 이격의 경우, 세밀한 영역 경계 설정이 필요하고, 찌그러짐의 경우 비교적 넓은 면적으로 발생할 가능성이 높은 파손입니다.
- 따라서, 스크래치와 이격의 경우 세밀한 경계 설정이 가능한 CRF 후처리 방식을, 찌그러짐은 특정 확률값에 기반하는 Thresholding 방식을 선택했습니다.
- 각 파손 클래스마다 서로 다른 변환 정책을 적용함으로써 보다 각 파손의 속성이 반영된 이진 마스크를 생성합니다.
- 이렇게 변환된 이진 마스크를 이용해 파손 영역의 좌표를 구하고, 입력 이미지 위에 외곽선(Polyline)을 덧그려 이미지 검수 관리자가 확인하기 편리한 형태로 출력을 마칩니다.
실제 데이터 검증 시 생긴 문제
학습된 모델을 사용해 업로드되는 이미지를 검증한 결과, 보완해야 할 점들을 발견했습니다.
이는 크게 모델의 정확도에 대한 문제와 시간적인 제한에 대한 문제로 나눌 수 있었습니다.
- 1) 모델의 정확도에 대한 문제
- 실제 사용자 데이터를 입력으로 모델의 파손 판별 정확도를 정성적으로 검증한 결과, 실제 업무에 투입하여 사용하기에는 정확도가 떨어진다는 문제점을 파악했습니다.
- 이는 학습 시 이용된 데이터(Training Set)와 실제 사용되는 데이터 사이의 간극으로 인한 것으로 볼 수 있습니다. 모델의 학습을 위해 데이터를 수집하는 과정에서 “육안으로 파손 여부를 확실하게 판별할 수 있는” 차량 이미지 2,000장을 추려 사용했기 때문에, 다양한 환경에서 촬영된 이미지들의 특성이 모델에 충분히 반영되지 않았을 가능성이 높았습니다.
- 1-1) 앱 내에서 차량 외관 촬영 시 가이드라인이 존재하지 않아 사용자들이 사진을 촬영하는 방식이 제각각이었습니다.
- 멀리서 찍어 차량이 아닌 주차선이 이미지의 대부분을 차지하거나, 차량 루프를 촬영하는 과정에서 뒤편에 주차된 차량들이 빼곡히 촬영되거나, 뒤편의 건물이 촬영된 이미지들이 종종 있었습니다.

- 1-2) 어두운 곳에서 촬영된 차량 이미지에 취약점을 보였습니다.

- 2) 시간적인 제한에 대한 문제
- Semantic Segmentation을 수행하기 위하여, 모델은 픽셀 단위로 해당 픽셀이 각 클래스에 속할 확률을 예측해야 합니다.
- 이를 위해 모델의 구조가 굉장히 깊고 복잡해지는 것은 불가피한 일이며, 방대한 연산량으로 연산 속도 저하의 위험성이 있습니다. CPU 머신 위에서 실제 테스트 시, 차량 이미지 한장 당 약 15초의 처리 시간이 소요됩니다.
- 이는 하루 평균 7-8만장의 이미지를 처리해야 하는 업무 상황에 적절하지 못하다고 판단했습니다.
- 이러한 문제점들을 해결하기 위해, 데이터 측면에서 보완할 수 있는 점과 모델 측면에서 보완할 수 있는 점으로 구분해 전체적인 틀을 수정했습니다.
문제점 보완
- 1) 데이터 측면에서의 보완 방법
- Data Augmentation을 사용했습니다.
- 어두운 곳에서 촬영된 이미지에 취약점을 보이는 문제점을 해결하기 위하여, Training Set에 무작위로 사진의 밝기와 대비를 변경하는 전처리를 가했습니다. (Random Brightness & Contrast Transformation)
- 2) 모델 측면에서의 보완 방법
- 먼저, 사용자들이 사진을 촬영하는 방식이 제각각이라는 점을 해결하기 위해 모델의 시작 부분에 Localization Network를 추가했습니다. 즉, 이미지 전체에서 차량이 존재하는 영역만을 Crop해 이후 모델의 입력으로 사용하겠다는 전략이었습니다. Localization Network는 COCO 데이터 세트로 미리 학습된 YOLO v3 모델을 사용했습니다.
- 모델의 연산량으로 인한 처리 속도 저하 해결을 위해 Global Damage Classifier를 추가하는 방법을 택했습니다. 실제로 쏘카 앱을 통해 업로드되는 이미지 중 손상이 존재하는 이미지는 소수이기 때문에, 굳이 모든 이미지를 깊은 Segmentation Network에 통과시킬 필요가 없다고 생각했습니다.
- Segmentation Network 바로 앞단에 이미지 단위의 파손 존재 여부를 0과 1로 예측하는 비교적 얕은 Classification Network를 추가했고, 이를 Global Damage Classifier라는 이름으로 칭하겠습니다.
- Global Damage Classifier의 예측 결과가 “이 이미지 내에는 파손이 없다. (=0, False)”로 정해진 이미지에 대해서는 더 이상의 Inference를 진행하지 않는 방법을 택했습니다. 이미지 내에 파손이 있다고 판단된 이미지에 대해서만 Segmentation Network 내의 연산을 통해 파손 영역 및 클래스 예측을 수행하게 됩니다.
- 파손이 존재하는 이미지 입장에서 보았을 때는 통과해야 할 모델이 하나 더 늘어난 셈이니 시간이 더 오래 걸리는 게 아닐까? 하는 의문이 들 수 있지만, 사용자가 제공하는 전체 이미지의 규모와 그 중 파손이 존재하는 이미지의 비중을 고려했을 때 전체 연산에 소요되는 시간을 눈에 띄게 줄일 수 있을 것으로 기대했습니다.
위의 수정 사항이 반영된 모델의 전체 구조 및 Inference 흐름도는 다음과 같습니다.
- 모델의 전체 구조
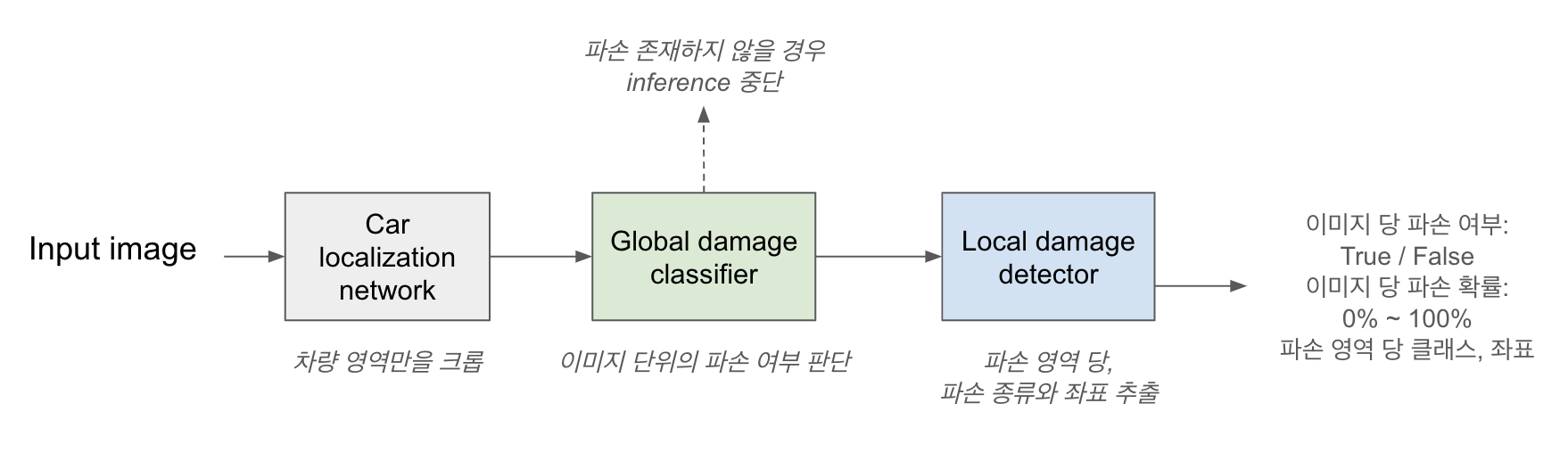
- 전체 Inference 흐름도
성능 평가
- 모델의 처리 속도
- 이렇게 완성된 모델은 GPU 머신 위에서 초당 약 5장의 이미지를, CPU 머신 위에서 초당 약 0.7장의 이미지를 처리할 수 있습니다.
- 모델의 정확도
- 성능 평가를 위해 분리해둔 200장의 Test Set 대상으로 계산된 결과입니다.
- Global Damage Classifier의 분류 성능: 96%의 Accuracy, 96%의 F1-score를 기록했습니다.
- Segmentation Network의 성능: Threshold 0.5 기준 96.7의 IoU를 기록했습니다.
- IoU란?
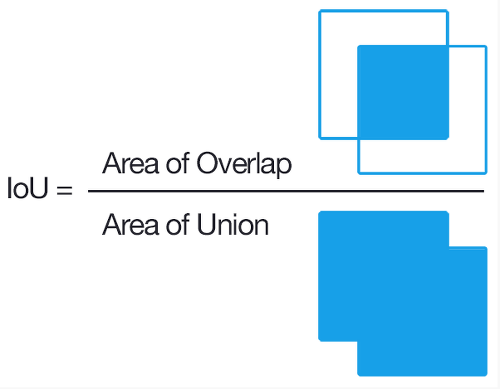
- Intersection on Union의 약자로, Segmentation Task 모델의 성능을 평가하는 지표입니다.
- IoU는 교집합 영역 넓이 / 합집합 영역 넓이로 계산되며, 이 때 Threshold 값은 한 픽셀이 특정 클래스에 속할 확률값이 몇 이상일 때 클래스에 속한다고 판단을 내릴지에 대한 경곗값입니다. 보편적으로는 Threshold 0.5 값을 기준으로 사용하나 이는 데이터, 모델의 특성 또는 달성해야 하는 목표에 따라 개발자가 조절 가능합니다.
실제 데이터에 적용 예시
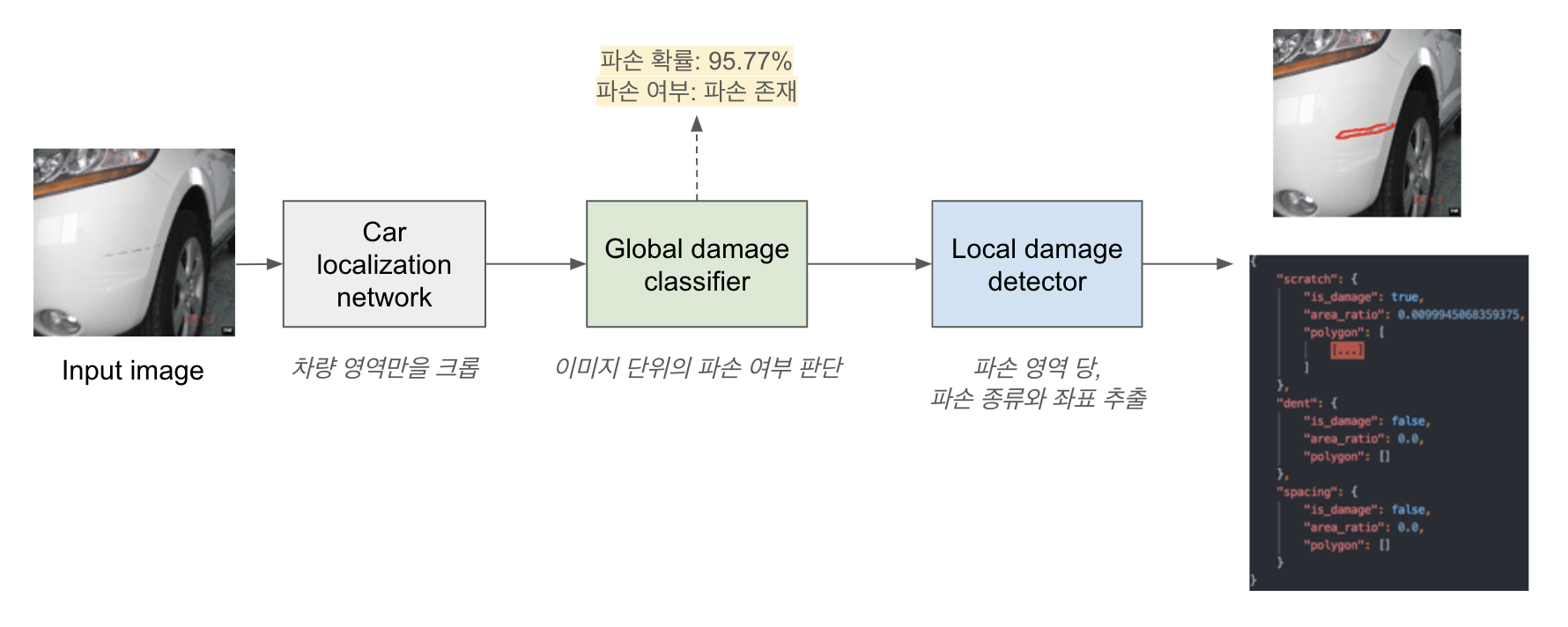
다음 예시 이미지들은 실제 앱을 통해 업로드된 차량 이미지들을 입력으로 한 모델의 Inference 결과입니다.

아래 이미지는 해당 모델을 통해 차량 파손 검수 결과를 제공하고 있는 실제 운영 페이지의 일부입니다.
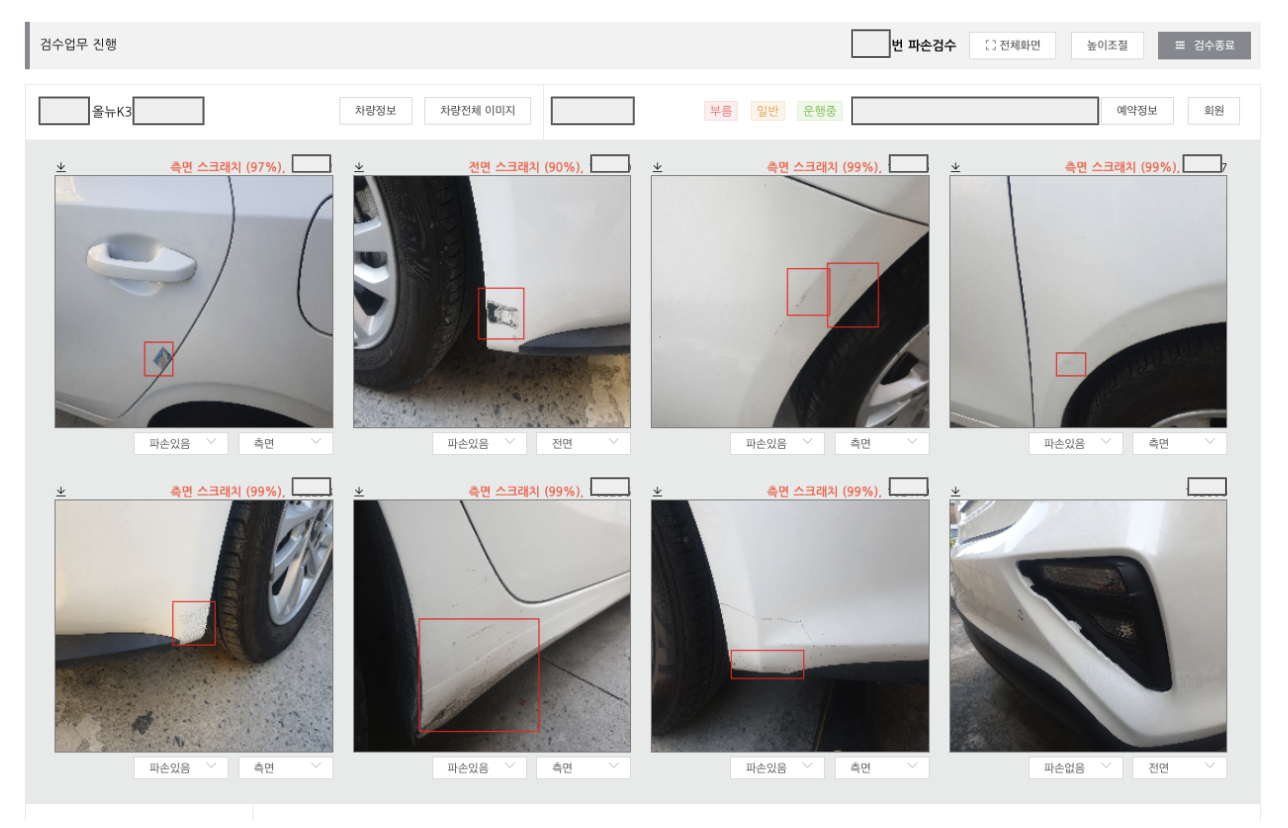
위와 같이 해당 모델의 검수 결과를 직접 운영 페이지에 녹여냄으로써, 업로드되는 차량 이미지 데이터를 차량 유지, 보수 업무에 적극적으로 활용하게 되었고, 차량 이미지 검수에 투입되었던 인력과 시간비용을 절감할 수 있게 되었습니다.
차량 단위로 파손에 대한 히스토리를 매 예약건마다 시간 순으로 관리하기 때문에, 추후 파손의 책임자를 추적해야 하는 상황이 발생했을 때에도 파손 발생 시점을 바로 추론하는 것이 가능합니다.
추후 발전 방향
실제 차량 파손 검수를 진행하는 운영 프로세스 내에서 모델의 검수 결과와 검수 인력의 판단 결과가 다른 경우, 해당 피드백을 모델의 2차 학습에 반영시키는 것을 계획하고 있습니다.
이는 정량적인 모델의 성능 향상 뿐만 아니라, 실제 운영 시 의사결정 기준 합의와도 상당 부분 맞물려 있는 피드백으로, 더 ‘정확한’ 모델 뿐만 아닌 더 ‘사람과 비슷한 의사 결정을 내리는’ 모델로의 개선이 이뤄질 수 있을 것으로 기대하고 있습니다.
차량 파손 탐지 모델 Serving과 관련 글이 추후 업로드될 예정입니다!
Reference
- U-Net
- DeepLab v3
- YOLO v3
- Instance Segmentation