 카일
카일O’Reilly Strata Data Conference New York 2019 다녀온 후 작성한 후기입니다.
목차
- O’Reilly Strata Conference 소개
- 신기한 광경
- Session 소개
사내 전파용으로 만든 행사 후기 슬라이드 자료를 SOCAR Speakerdeck에 업로드했습니다! 발표 자료엔 다음 내용이 있습니다. 관심있으신 분은 발표 자료를 참고하시면 좋을 것 같습니다 :)
- 3개의 테마, 6개의 발표 정리
- Optimization
- Uber
- Explainable AI
O’Reilly Strata Conference 소개
O’reilly는 개발 관련된 책을 많이 만들고 있는 출판사로, 아마 개발 관련 책을 보셨다면 O’Reilly 마크를 보셨을 겁니다.

출판사지만 동시에 컨퍼런스도 다양하게 열고 있습니다. 매년 다양한 장소에서 여러 테마로 컨퍼런스가 열리고 있습니다.
2019년엔 Software Architecture, TensorFlow, AI, Data 등 다양하게 열렸습니다.

저희가 이번에 참여한 컨퍼런스는 Data Conference로 데이터에 관한 포괄적인 세션들이 많았습니다.
이번 New York 행사장은 한국의 코엑스와 비슷한 장소였습니다.

행사장 입장시 안내 데스크에 사람이 있는 한국과 달리, 신청자가 직접 기기를 통해 이름표를 직접 인쇄합니다. 등록한 메일로 QR Code가 전달되는데, 기기에서 QR Code를 입력하면 됩니다.

행사장엔 세션 장소와 기업 부스로 나뉘어져 있었습니다.
Anaconda 같은 기업 부스도 있었고, Google Cloud Platform 등이 있었습니다.

O’reilly 부스에선 컨퍼런스 참여자 전원에게 원하는 책 1권을 주고 있었습니다. Stream Processing with Apache Spark를 받았습니다.

신기한 광경
1) DJing

행사장에 음악이 계속 나오고 있는데, DJ가 계셨습니다.
2) 프로필 사진 촬영

프로필 사진 찍어주는 공간도 있었습니다. 사람들이 줄서서 자신의 프로필 사진을 찍고 있었습니다.
3) 세션 종료 후 파티

세션이 끝난 후 기업 부스에서 파티 음식을 제공했습니다.
- 간단한 먹거리, 맥주, 아이스크림 등
- 개발자 행사에 곁들여진 파티의 모습을 볼 수 있었습니다
이런 부분을 통해 행사를 주최한 오라일리가 행사에 얼마나 신경쓰는지를 알 수 있었습니다.
Session 소개
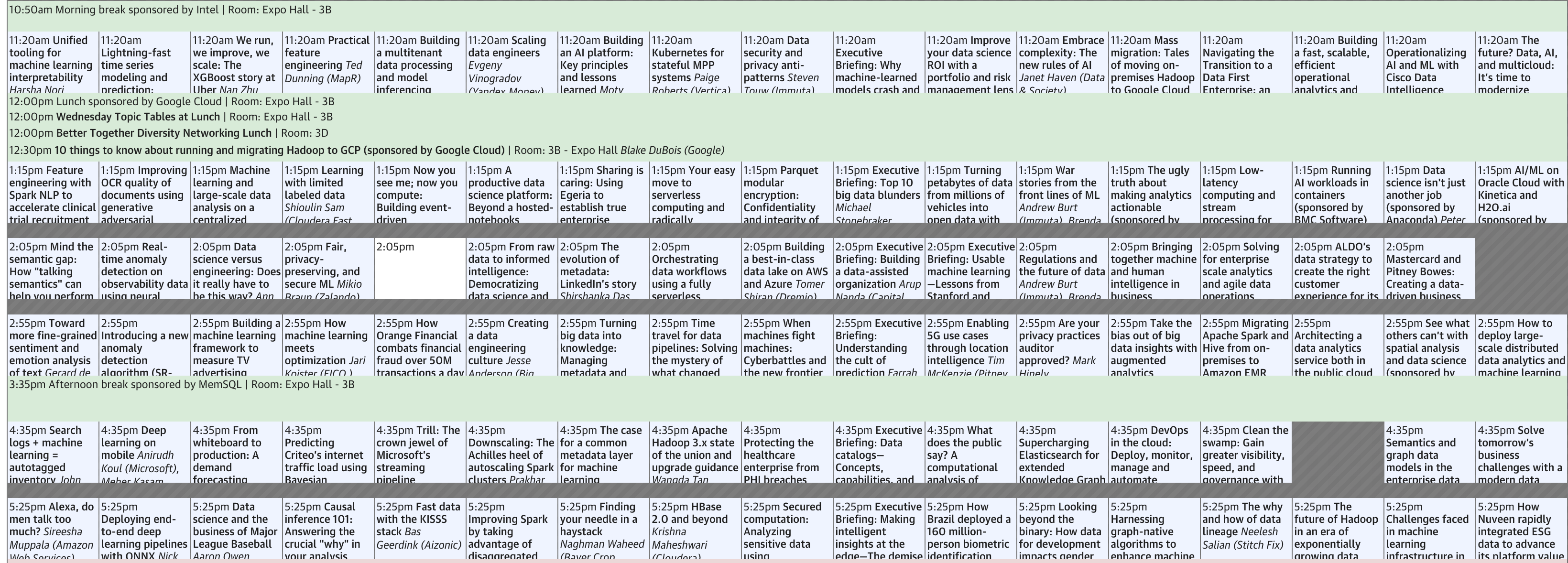
다양한 발표 중 저희가 들은 세션 중 블로그 글에 정리한 것은 총 4개입니다.
How machine Learning meets optimization
최적화(Optimization)란 단어는 데이터 사이언스를 공부하다 보면 자주 접할 수 있는 단어입니다. 최적화는 다양한 방식으로 진행할 수 있는데, 산업 공학에선 Linear Programming(LP), Constraint Programming 등으로 문제를 풀 수 있습니다.
발표자분은 Optimization과 머신러닝이 함께 필요한 문제의 예시로 Scheduling Problem과 Routing Problem을 예시로 들었습니다. 이 문제들은 저희가 속한 모빌리티 산업에서 많이 풀고있는 문제로, 제한된 리소스로 최대(혹은 최소)의 효과를 낼 수 있는 문제입니다.
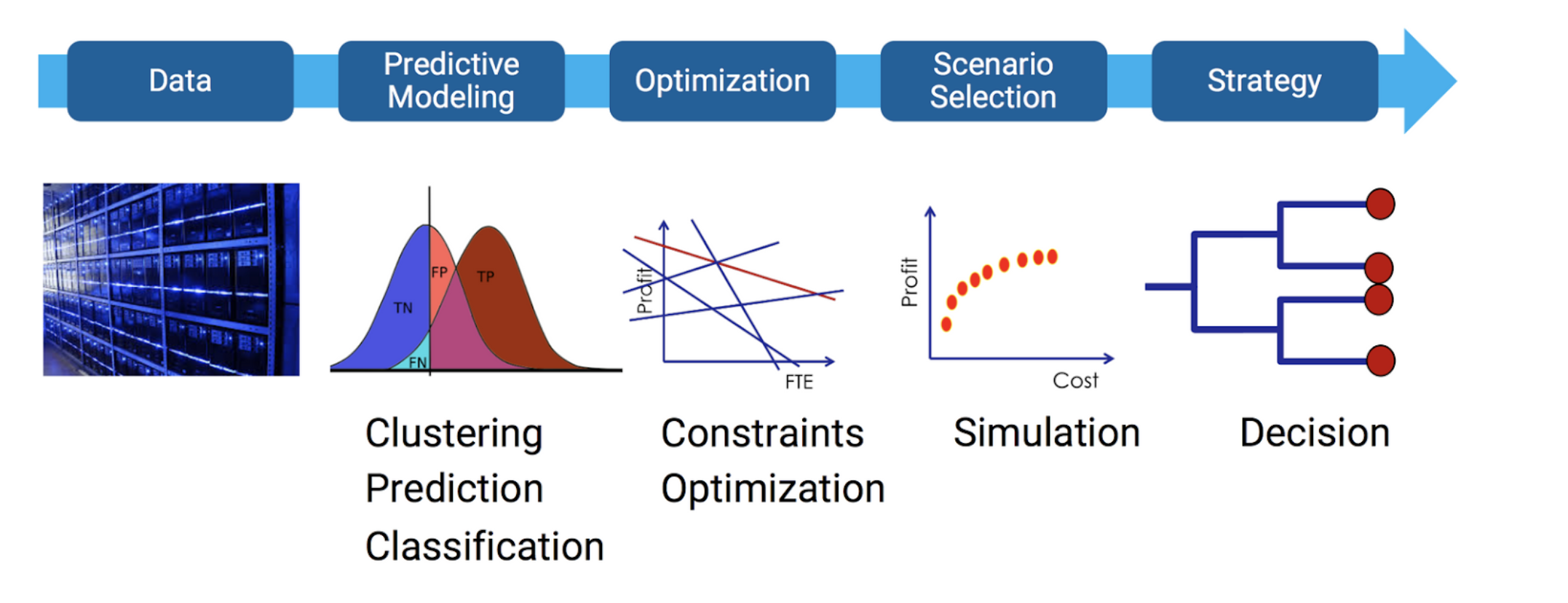
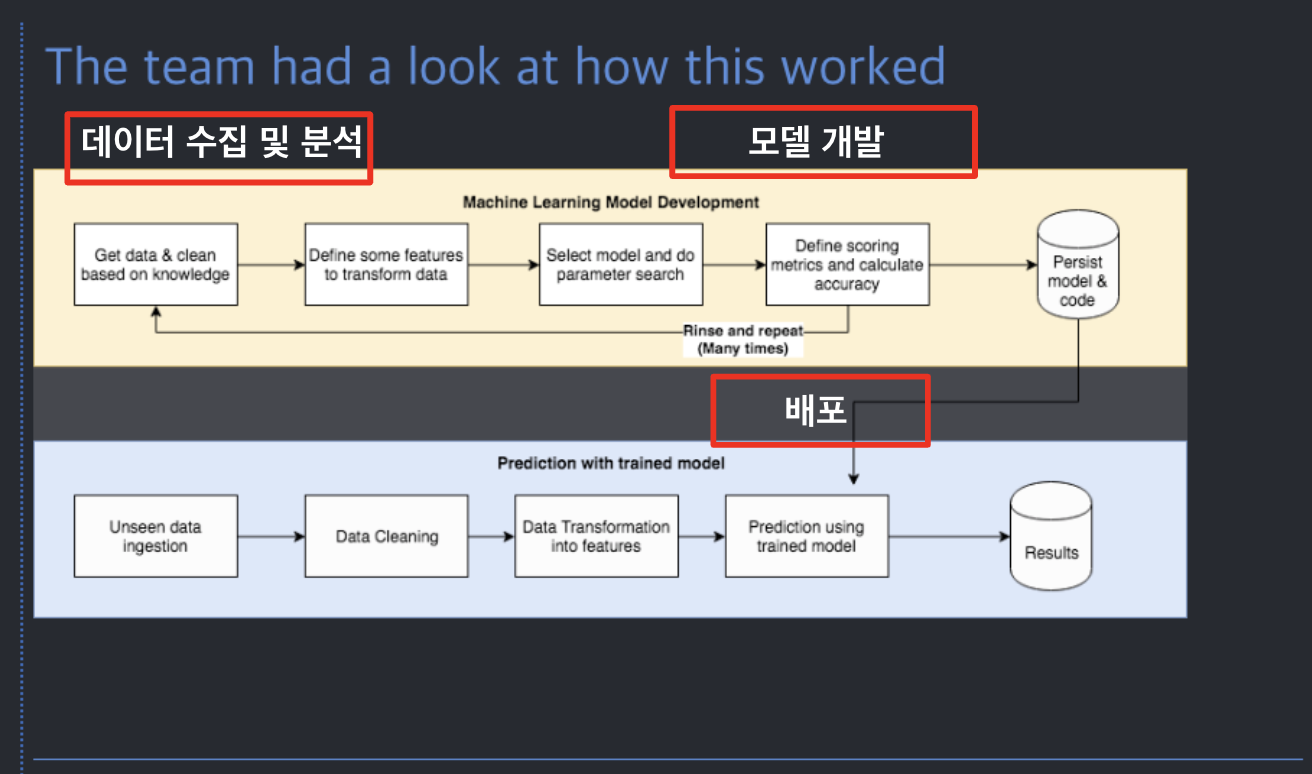
최적화와 머신러닝을 활용하는 방법은 다음과 같습니다. 예측 모델링 후, 그 값을 토대로 최적화를 돌리고 시나리오를 선택합니다.
최적화와 머신러닝 모두 Input을 넣으면 Output이 나오는 점은 동일하나, 최적화는 입력 x에 대해 제약 조건과 objective value가 있어 optimal solution을 찾고 머신러닝은 레이블된 데이터가 존재하는 상태에서 Error를 최소화합니다.
ML is not enough: Decision automation in the real world
이 세션은 위에서 말씀드린 “How machine Learning meets optimization” 같이 원론적인 내용을 다루기보다, 머신러닝과 최적화를 같이 사용한 실용적인 후기에 대한 발표입니다.
대부분 현실의 의사 결정은 머신러닝 모델의 예측값만으론 충분하지 않고, 사람의 판단은 Decision Making과 Machine Prediction으로 이루어집니다.
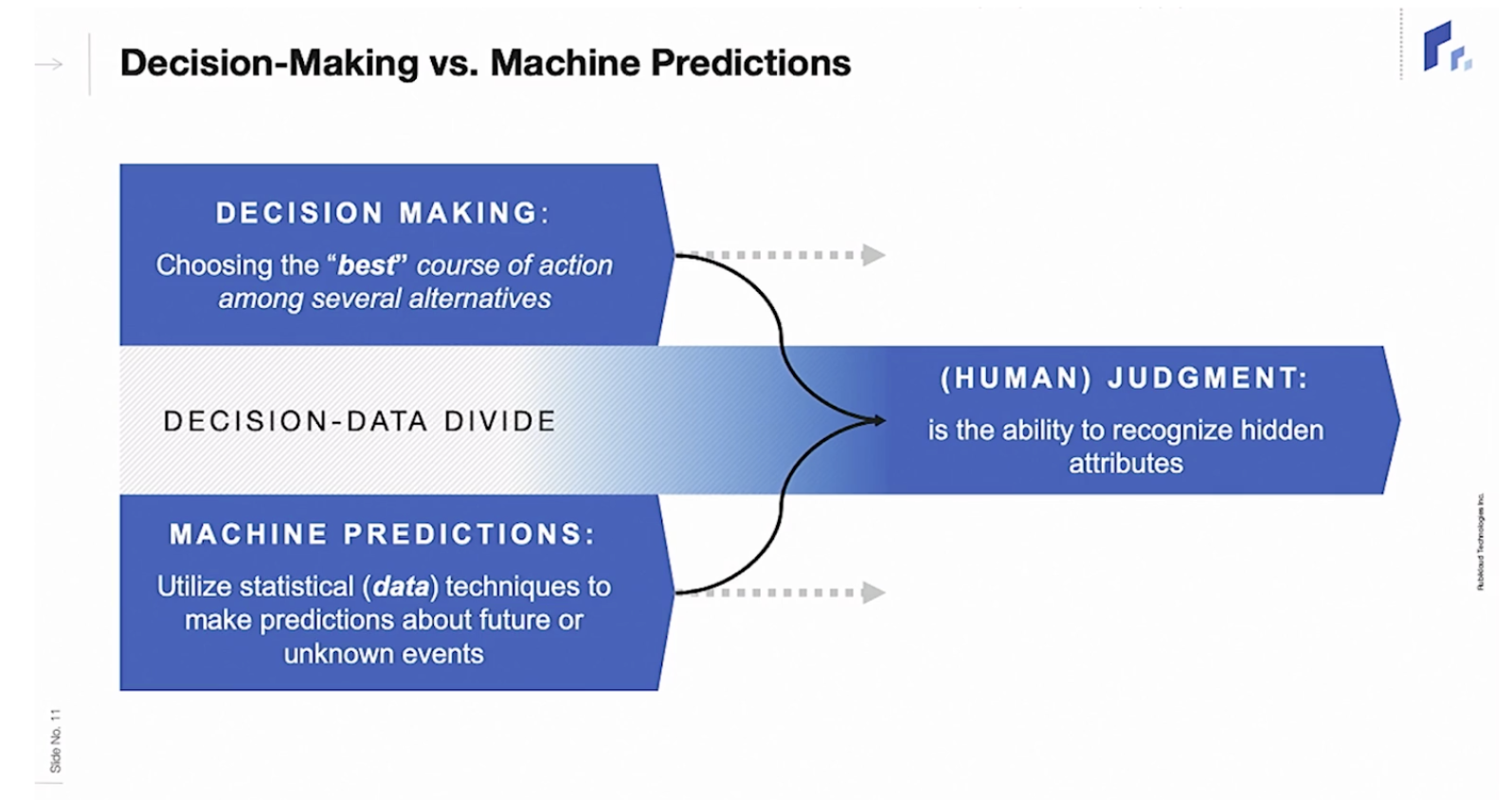
Decision Making은 여러 대안 중 가장 Best 행동을 찾는 것이고, Machine Prediction은 미래의 Unknown event를 예측하는 것입니다.
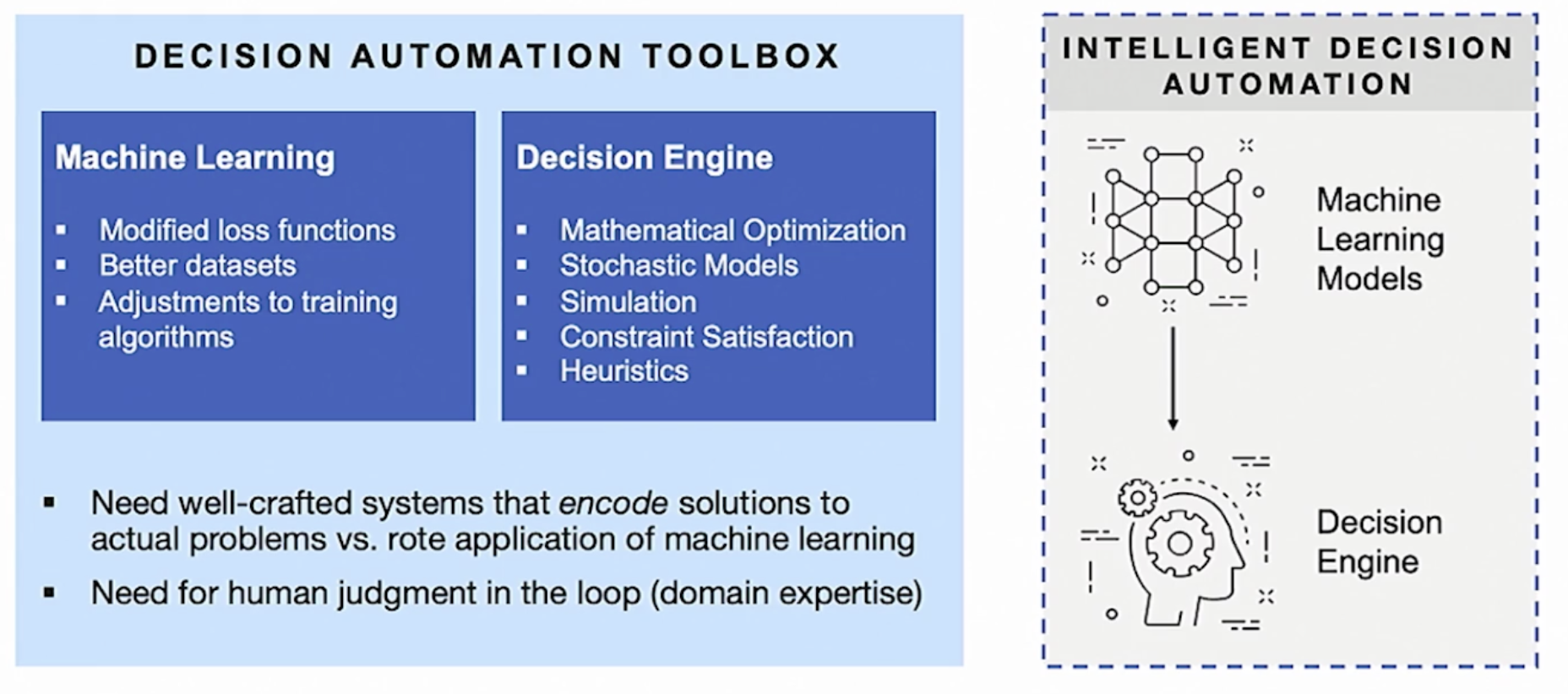
이 두가지를 조합하기 위해 머신러닝의 예측값을 Decision Engine의 Input으로 넣고 결과를 받도록 설계합니다.
Decision Engine의 제약 조건(constraint)으로 비즈니스 로직상 중요하게 여기는 것들을 넣을 수 있습니다. 예를 들어 특정 제품이 프로모션하고 있다면, 그 부분을 우선적으로 추천해줄 수 있습니다. 그 외에도 아래 사진처럼 새로운 제품에 대한 비즈니스 로직, 재고에 대한 로직 등을 추가할 수 있습니다.
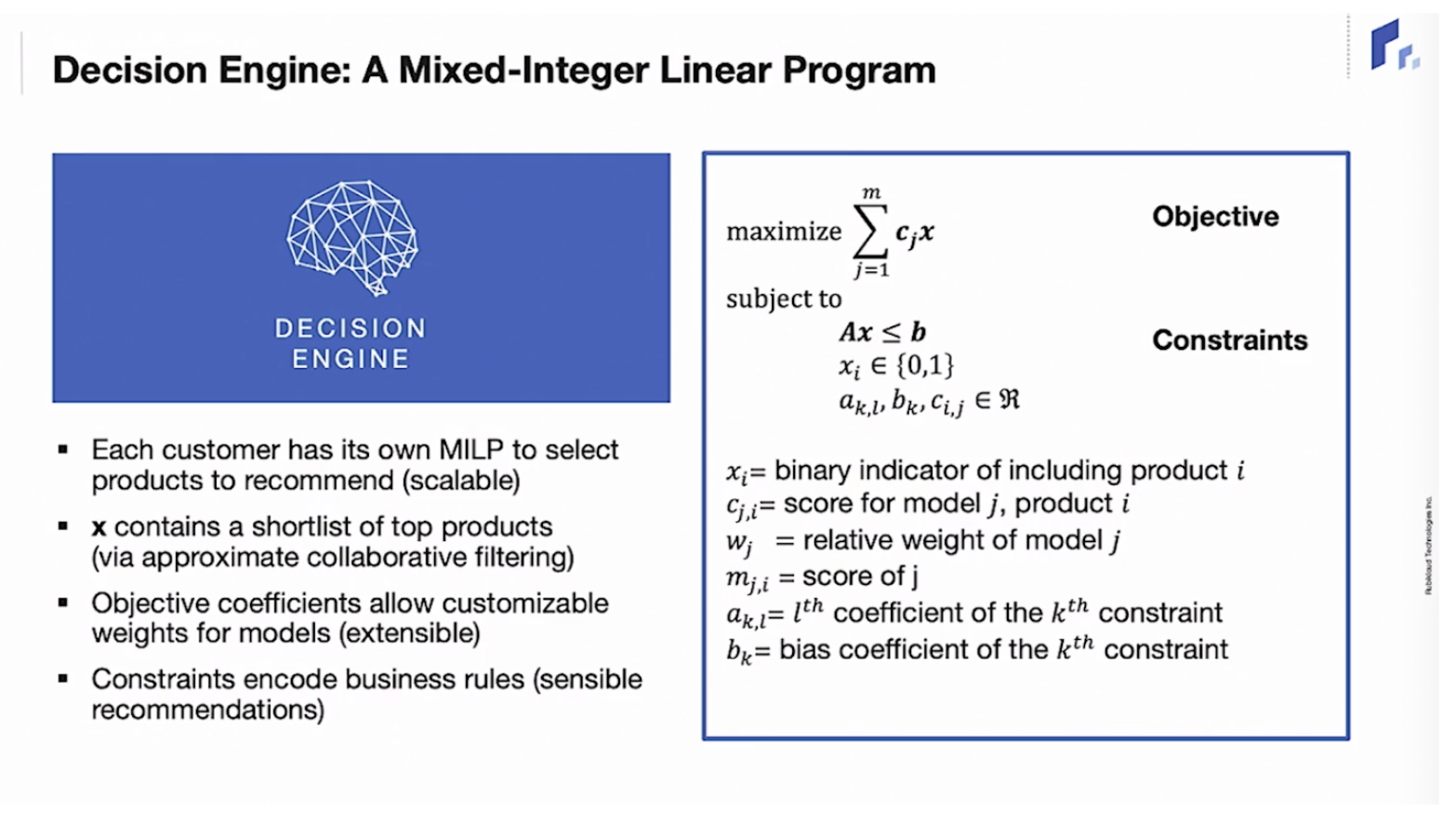
Decision Engine은 Mixed Integer Programming을 사용해 예측 값과 비즈니스 룰을 제약 조건으로 삼고 목적 함수를 최대화하는 값이 나오게 됩니다.
다른 예시로 Supply Chain(공급 관리) 최적화에 대한 내용을 들었습니다.
준비하고 있어야 하는 안전한 재고량보다 수요 예측이 높게 될 경우와 낮게 될 경우 생길 비용이 비대칭적이다라는 점을 말하며, 수요 예측 결과에 따른 비용을 다르게 정의했습니다.
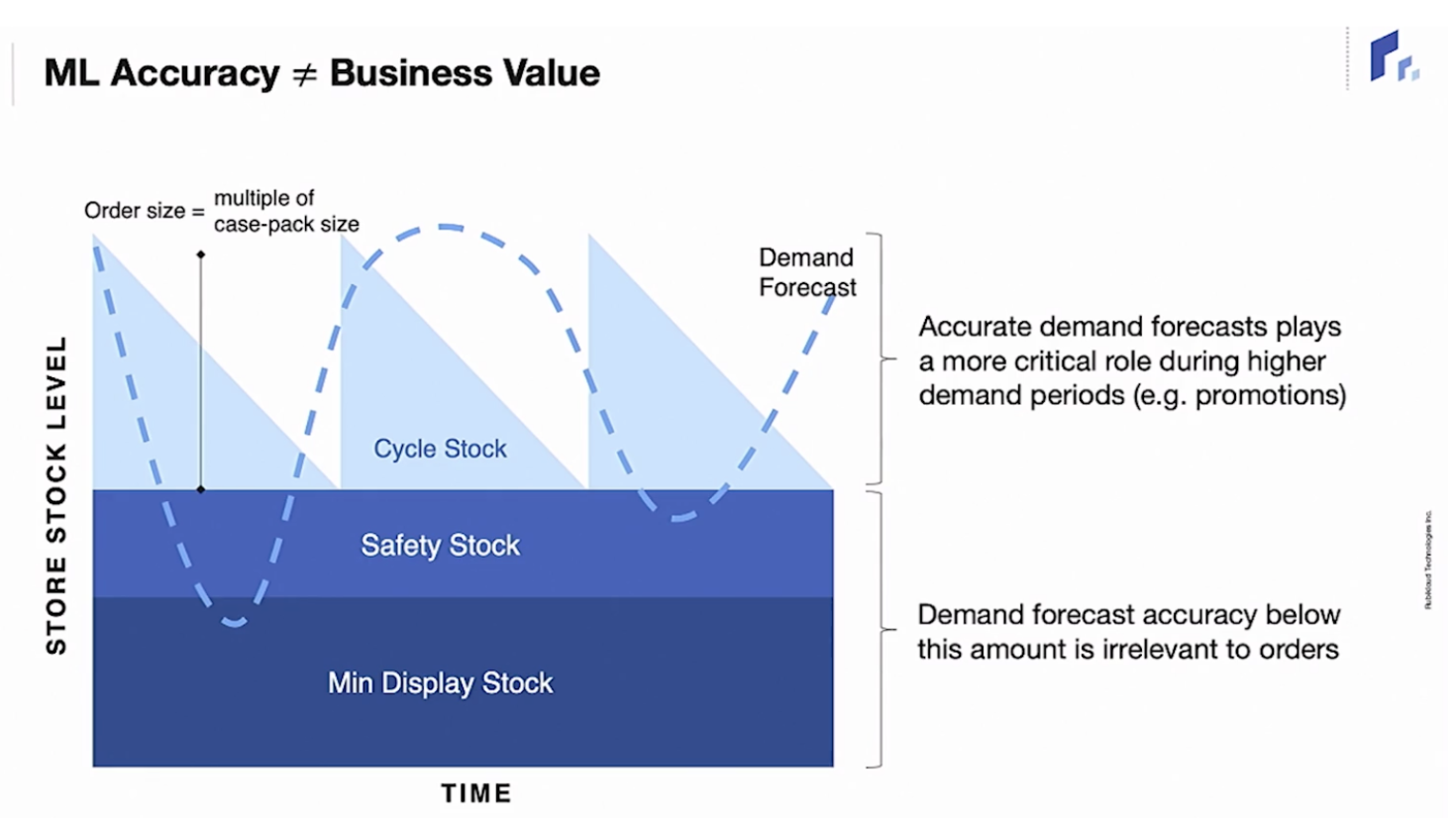
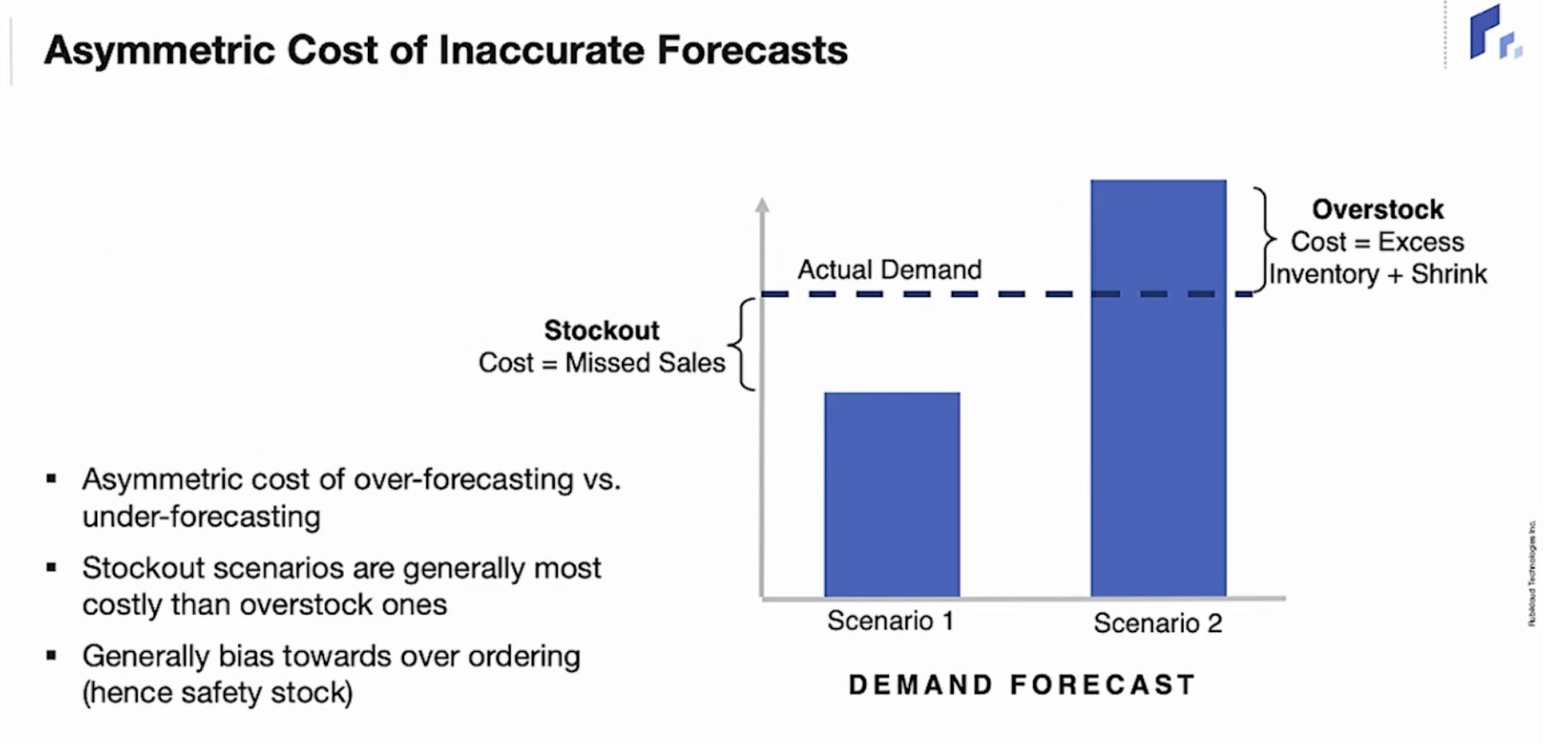
두번째 예시에선 모델의 예측 값을 Deterministic한(한 숫자로 나오는) 수요를 uncertainty range로 대체하는 내용이 나왔습니다.
Uncertainty Range를 표현하기 위해 Two quantile regression, 분포를 근사하기 위한 앙상블 활용, 모델의 Output을 분포로 표현(Bayesian structural time series)을 사용할 수 있습니다.
Uncertainty Range를 구한 후 Robust Optimization를 사용해 최악의 상황을 피하는 방식으로 최적화합니다.

A Practical guide to algorithmic bias and explainability in machine learning
이 세션은 MLOps 관련 Github Repository 중 유명한 Awesome production machine learning 소속이신 분이 발표했습니다.
머신러닝 모델은 잘못된 학습 데이터로 인해 편향되기 쉽습니다. 이에 최근 트렌드로 유럽에선 AI와 관련한 윤리가 법제화 되고 있습니다. 대표적으로 유럽위원회는 AI의 자동화된 의사결정에 대해 설명받을 수 있는 개인의 권리를 명시합니다.


발표자가 속한 Ethical AI라는 조직에선 머신러닝 모델 개발의 각 단계에서 편향을 줄이고, 모델을 설명하기 위한 오픈소스를 개발하고 있습니다.
그 중 대표적으로 데이터 분석 단계에선 eXplainable AI(XAI)란 라이브러리를 소개하고, 모델 개발 및 평가 단계에선 ALIBI란 라이브러리에 대해 소개했습니다.

ALIBI 라이브러리에 구현되어 있는 대표적인 Explainer는 Anchors 가 있습니다.
Anchors는 내부 알고리즘으로 모델을 설명하는 것이 아니라 입력값의 조합에 따른 출력값을 가지고 모델을 설명합니다. 이러한 특성 때문에 Tabular 데이터부터 Text, Image와 같은 비정형 데이터까지 모두 적용할 수 있다는 장점이 있습니다.
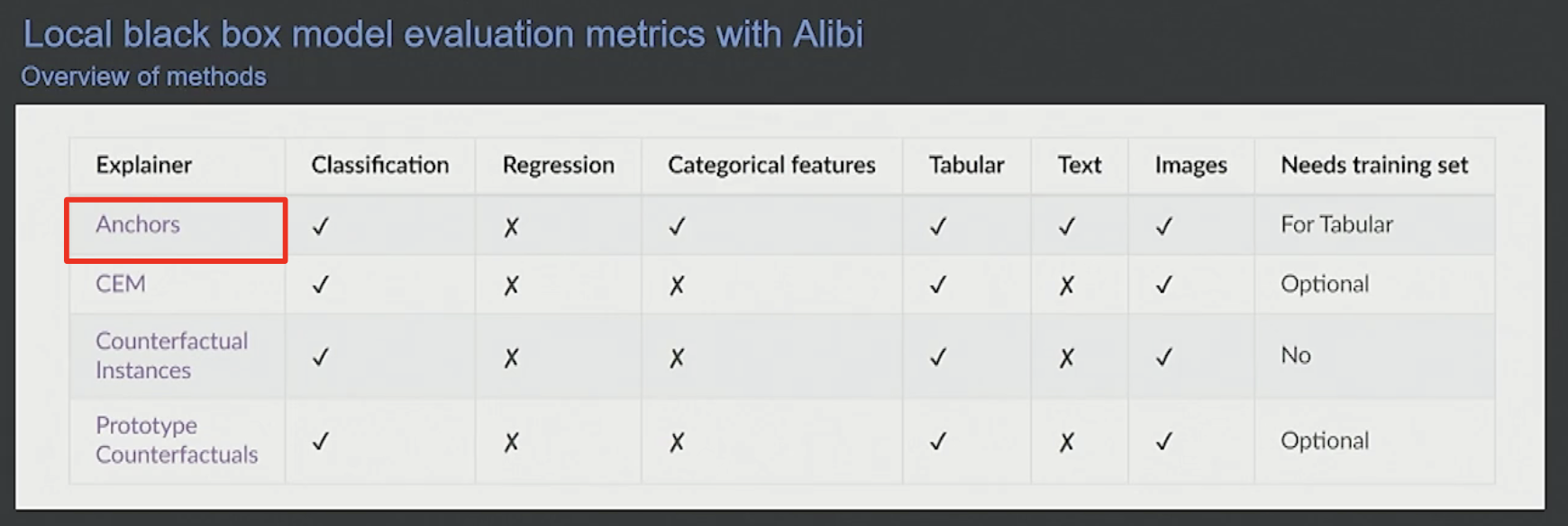
Anchors 는 특정 피쳐를 고정한 후, 다른 피쳐에 변화를 주었을 때 예측값이 변하는지 변하지 않는지를 관찰하는 방식으로 Anchors 를 알아냅니다.
Anchors를 찾아낼 때는 Brute-Force 방식이 아닌 Beam search 와 MAB 방식으로 효율적으로 찾아냅니다. 아래 예시는 beagle의 Anchor 이미지를 고정한 후 다른 영역을 변화시키더라도 예측값은 항상 일정하다는 것을 보여줍니다.

Unified tooling for machine learning interpretability
이 세션은 Microsoft에서 개발 중인 interpretML 오픈소스에 대한 세션입니다. 공식 Github
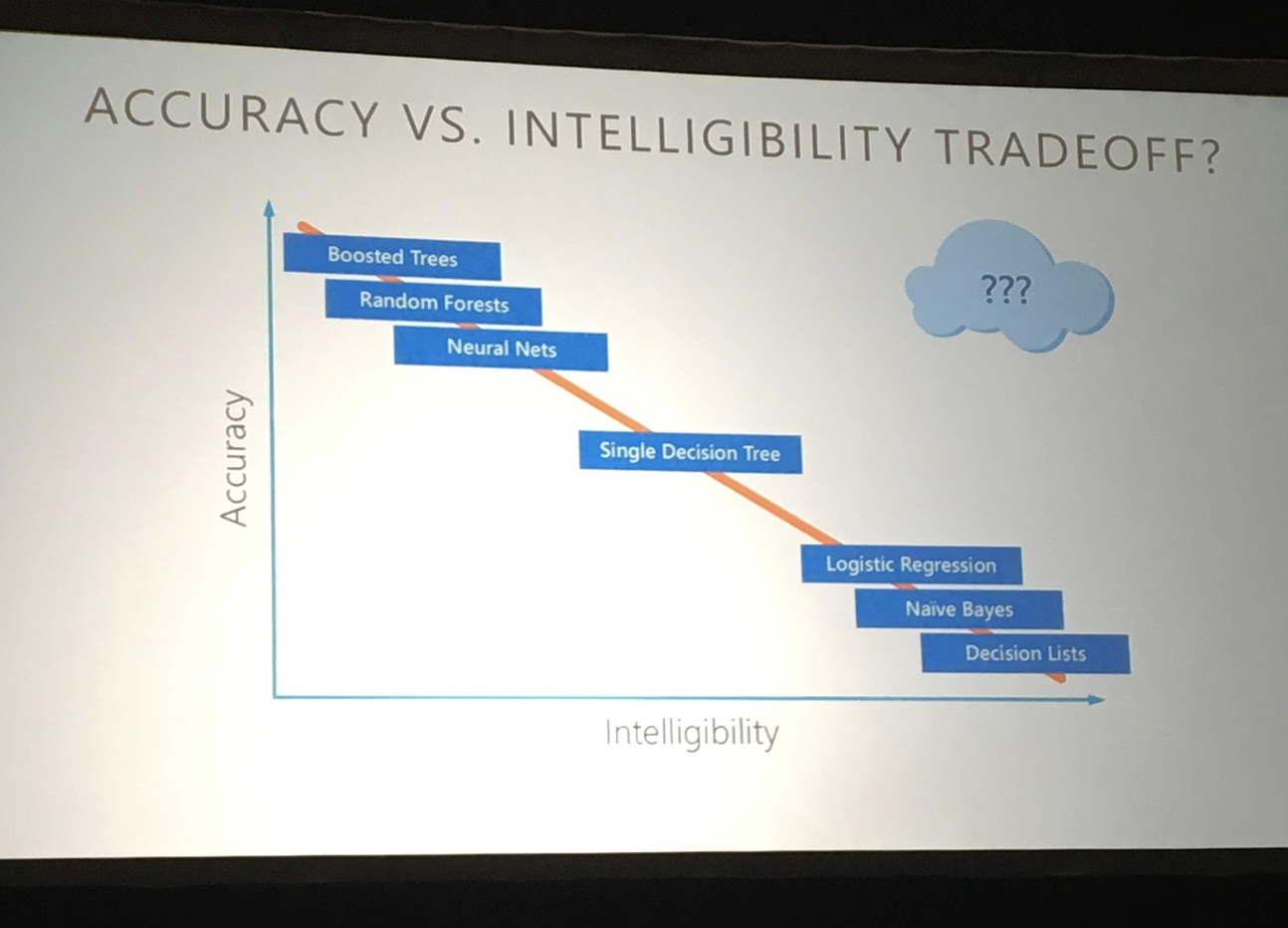
interpretML의 첫번째 특징은 모델의 정확도와 설명력을 모두 갖추려 했다는 점입니다.
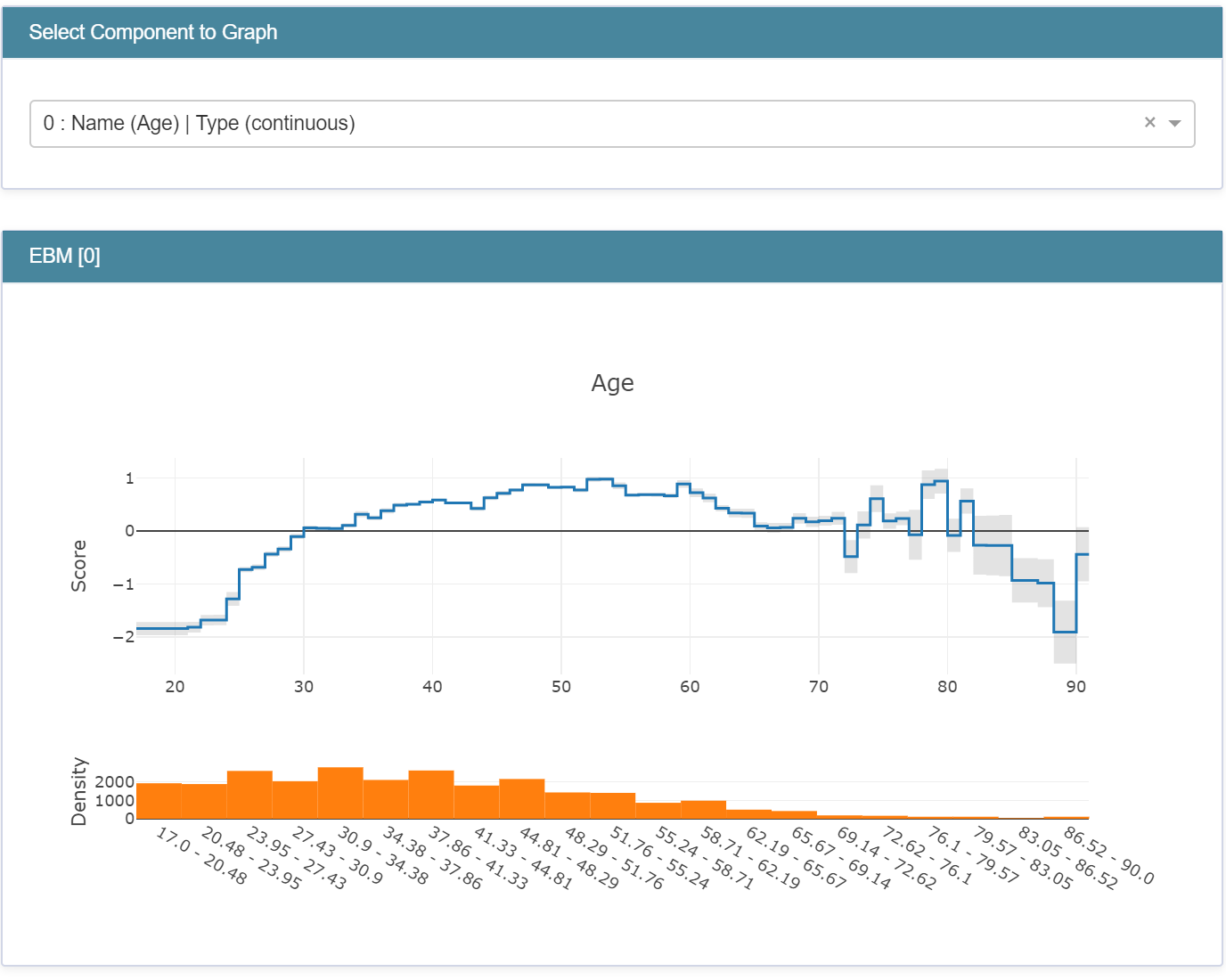
일반적으로 머신러닝 모델의 정확도가 높아질수록 설명하기는 어렵다는 문제가 있습니다. Microsoft 팀은 전통적인 GAM 모델에 Boosting 기법을 결합한 Explainable Boosting Machine (EBM) 이라는 알고리즘을 제안했습니다.
두번째 특징은 모델을 설명하는 기능들을 갖추고 있다는 점입니다.
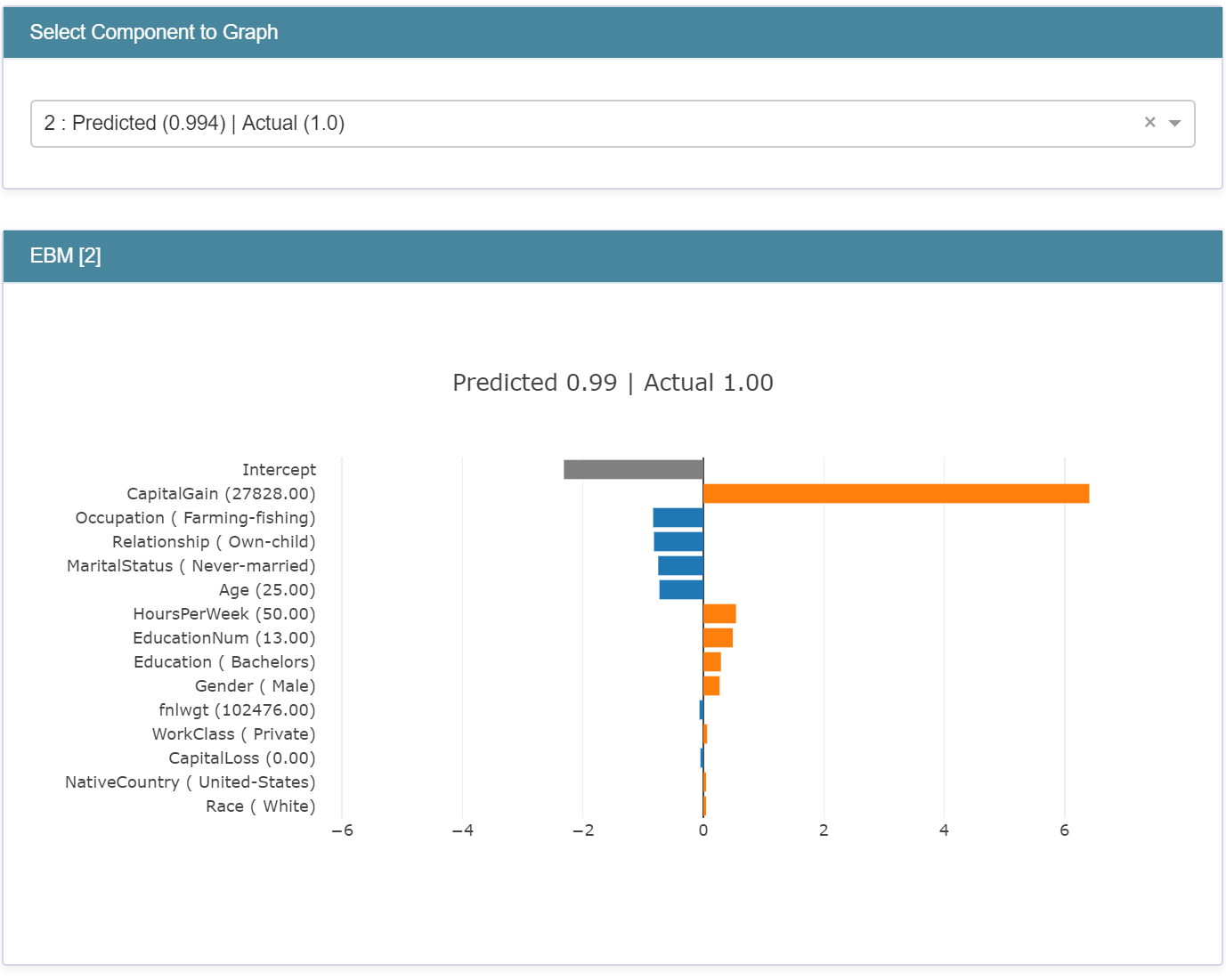
특정 피쳐가 모델 전체에 미치는 영향에 관점(Global)과 특정 instance에 대해 왜 그렇게 예측했는지에 대한 설명(Local)으로 두 가지 측면에서 모델을 설명합니다. 그 이후엔 라이브 코딩으로 라이브러리를 활용하는 방법에 대해 알려줬습니다.
참고 자료
-
쏘카 데이터그룹의 타다데이터팀 카일과 윤이 다녀와서 사내 전파용으로 만든 발표 자료 : SOCAR Speakerdeck에 업로드했습니다
- O’reilly Strata Data Conference 영상을 다시 보는 방법
- Oreailly Learing에 가입 후 시청 가능합니다. 첫 가입시 1달 무료고, 그 이후엔 구독 비용이 존재합니다
- O’reilly Starata Data Conference New York 발표 자료
- Oreilly Conference 발표 자료에 발표 자료가 업로드되어 있습니다. 모든 발표 자료가 업로드되진 않았지만, 관심있으신 부분에 대한 자료를 보시면 좋을 것 같습니다