 바다
바다 올리버
올리버안녕하세요. 데이터 엔지니어링 그룹 모비딕 팀의 바다, 올리버입니다. 차량용 단말을 위한 IoT 파이프라인 구축기 #1에 이어, 차량에서 수집한 정보를 전사적으로 활용할 수 있도록 어떻게 단말 파이프라인을 설계하고 만들어 가는지에 대해 자세히 이야기하려고 합니다.
이 글은 다음과 같은 분들에게 도움이 됩니다.
- 데이터 파이프라인 구축에 관심 있는 개발자
- 차량의 정보 수집과 데이터 흐름에 관심 있는 분
- AWS IoT Core, MSK(Managed Streaming for Apache Kafka) 솔루션에 관심 있는 개발자
목차
쏘카의 첫 단말 파이프라인을 소개합니다
기존 단말 파이프라인
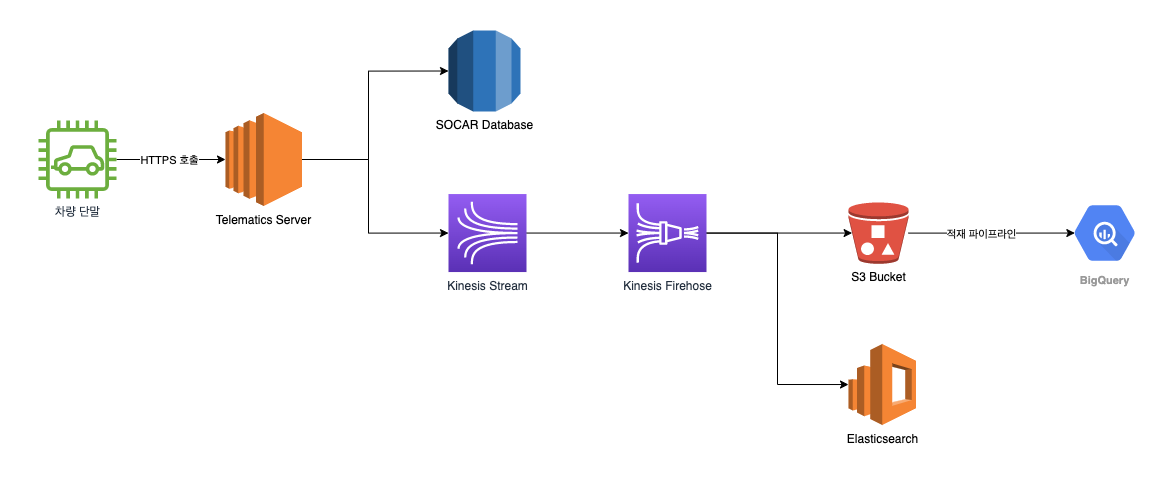
과거에는 차량에서 수집한 정보를 HTTPS 프로토콜을 이용해 쏘카의 텔레매틱스 서버에 전달했습니다. 텔레매틱스 서버에서 단말 데이터를 수집, 가공, 적재하는 작업의 일환으로 파이프라인에 단말 데이터를 투입했습니다. 텔레매틱스 서버는 쏘카 서비스의 원활한 운영과 고객 불편의 최소화를 위해 차량에서 수집한 정보를 최대한 빠른 시간 안에 처리하여야 합니다.
단말이 차량에서 수집한 정보의 종류에 따라 텔레매틱스 서버의 다른 엔드포인트에 이를 보고합니다. 예를 들어 일반적인 차량 정보의 주기적 보고의 경우 /log 엔드포인트로, 단말 재부팅시에 대한 보고는 /boot 엔드포인트로 보고하는 방식입니다.
차량에서 수집한 정보를 보고받은 텔레매틱스 서버는 이 정보를 서비스 운영을 위해 데이터베이스의 차량 정보 스키마에 맞추어 변환하여 데이터베이스에 적재합니다. 이렇게 변환하는 과정에서 운영에 꼭 필요한 데이터만을 필터링해 적재하기 때문에, 운영에는 충분한 정보를 가지고 있지만 연구와 분석을 위해 사용하기에는 한계가 있습니다.
따라서 연구, 분석에도 차량에서 수집한 정보를 충분히 활용할 수 있도록 필터링 되지 않은 데이터를 AWS Kinesis에 흘려보냅니다. Kinesis는 실시간으로 데이터 스트림을 수집하고 처리, 분석하는 데에 사용하는 AWS의 솔루션입니다. 당시 Kinesis를 선택했던 이유는 데이터 스트림에 대한 관리와 개발을 최소화하면서도 차량에서 수집한 정보를 필요한 곳에서 최대한으로 활용하고자 했던 선택이었습니다.
이렇게 Kinesis Stream에 전달된 차량에서 수집한 정보는 Kinesis Firehose를 거쳐 각각 Elasticsearch, S3, BigQuery에 저장하여 활용하고 있었습니다.
기존 파이프라인의 한계
하지만 단순히 ‘수집 정보를 흘려보내기만 하면 되겠다’라고 가볍게 여겼던 Kinesis는 생각보다 많은 관리가 필요했고, Kinesis Stream을 사용하는 프로젝트가 늘어날수록 파이프라인은 점점 복잡해졌습니다.
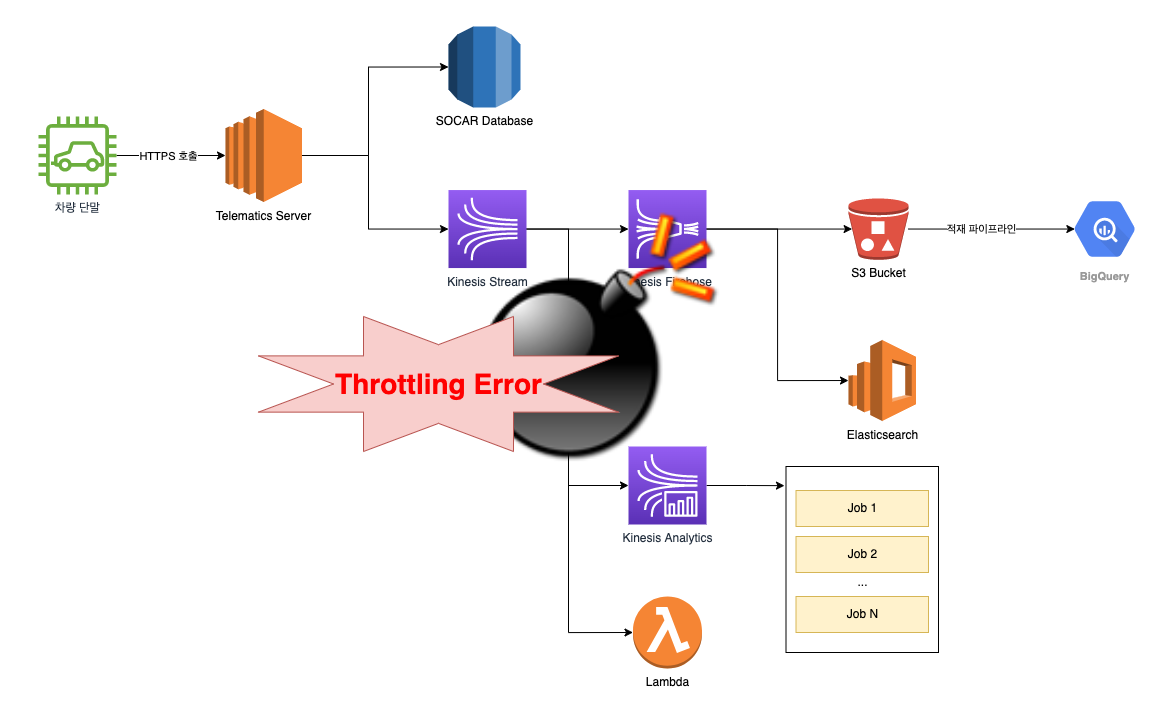
기본적으로 Elasticsearch와 S3, BigQuery에 적재하는 것 외에도, 전사에서 필요한 용도에 따라 단말 수집 정보가 실시간으로 수집되는 Kinesis Stream에 Consumer를 연결하여 활용할 수 있었습니다. 그러나 이 파이프라인을 관리하는 주체가 없어서 불필요하게 많은 Consumer가 연결되었습니다. Kinesis 스트림에 많은 Lambda 함수, 많은 Process들이 붙었고 Kinesis Stream에 병목이 생기는 경우가 생겼습니다.
더 많은 처리량을 위해 샤드(샤드 당 1초에 최대 2MB의 데이터 처리)를 늘려보기도 하고, 향상된 팬아웃 기능을 사용하여 극복할 수 있었지만 이는 비용 증가와 직결되며, 근본적인 해결책도 아니었습니다.
한계를 넘기 위한 신규 파이프라인 설계
Server-side Application의 업데이트는 보통 즉각적인 효과를 발휘하지만, 사용자의 PC에 설치되는 소프트웨어나 하드웨어의 펌웨어는 상황에 따라 업데이트에 상당한 시간을 필요로 합니다. 쏘카의 단말 펌웨어 업데이트도 항상 쉽지 않은 일입니다.
차량에 명령을 내리는 명령 채널에 IoT Core를 사용하게 되면서, 보고 채널에도 IoT Core로 갈아탈 수 있는 기회가 왔고, 기존 파이프라인의 한계점을 개선할 수 있는 절호의 찬스를 맞이했습니다! 그리하여 발 빠르게 신규 파이프라인 설계에 착수했습니다. 설계하면서 중점을 두었던 주제들은 다음과 같습니다.
- 단말 수집 정보를 수집-가공-저장하던 텔레매틱스 서버를 은퇴시키자
- 텔레매틱스 서버는 그동안 단말 데이터 처리를 위해 수고해주었지만, 장애가 발생하면 파이프라인의 병목이 되는 원인이기도 했습니다. 이는 파이프라인의 흐름에 치명적일 수 있어 용도를 최소화하거나 은퇴시키고자 했습니다.
- IoT Core를 사용하면서 프로토콜이 제한적인 HTTP 프로토콜 통신을 걷어내고 대용량의 데이터를 전송하기 적합한 MQTT 프로토콜 통신을 사용할 수 있습니다.
- 전사에서 Kafka를 사용하는 분위기에 발맞추어, 데이터 스트리밍 플랫폼의 최강자인 Kafka를 사용하자
- 모비딕 팀뿐만 아니라 전사에서 Kafka를 도입하고자 하는 준비 과정이 있었고, Kafka에 대한 사내 지식이 쌓여가고 공유하고 있었기 때문에 이 또한 좋은 기회라고 생각했습니다.
- 하나로 통합되어 있던 토픽을 관심 분류에 따라 여러 토픽으로 나누어 사용하자
- 기존 파이프라인에서는 차량에서 수집한 정보를 저장되는 데에 하나의 토픽을 사용하고 있었습니다. 이 때문에 스트림 내의 차량 수집 정보를 특정 프로젝트 내에서 사용하기 위해서는 프로젝트에 불필요한 정보도 일단 모두 읽어야 하는 문제가 있었습니다. 이러한 비효율을 제거하고자, 단말 수집 정보의 토픽을 관심사별로 분리하고자 했습니다.
- 시스템 부하가 일으키는 장애에 대한 걱정 없이 신규 서비스를 개발하자
- Kinesis 파이프라인에서 Throttling이 지속적으로 발생하면서 Kinesis와 연결하여 사용하려던 신규 서비스를 투입하는 것도 굉장히 부담스러워졌습니다. 이를 극복하면서 신규 서비스 개발에도 데이터 스트림이 걸림돌이 되지 않았으면 했습니다.
- MSK를 사용하여, 운영 리소스를 최소화하자
- 우리의 리소스를 고려한다면 Kafka 운영을 위한 리소스가 추가 투입되는 것도 부담스러운 요소 중 하나였습니다. AWS에서 완전 관리형 Kafka 서비스인 MSK를 제공하고 있습니다. MSK 덕분에 Kafka를 직접 사용하면서 운영 리소스를 최소화하며 빠르게 요구사항을 충족할 수 있겠다고 생각했습니다.
- 데이터 파이프라인의 토픽, 파티션 등의 세부 설정을 우리가 직접 하여 상황에 맞게 사용할 수 있도록 하자
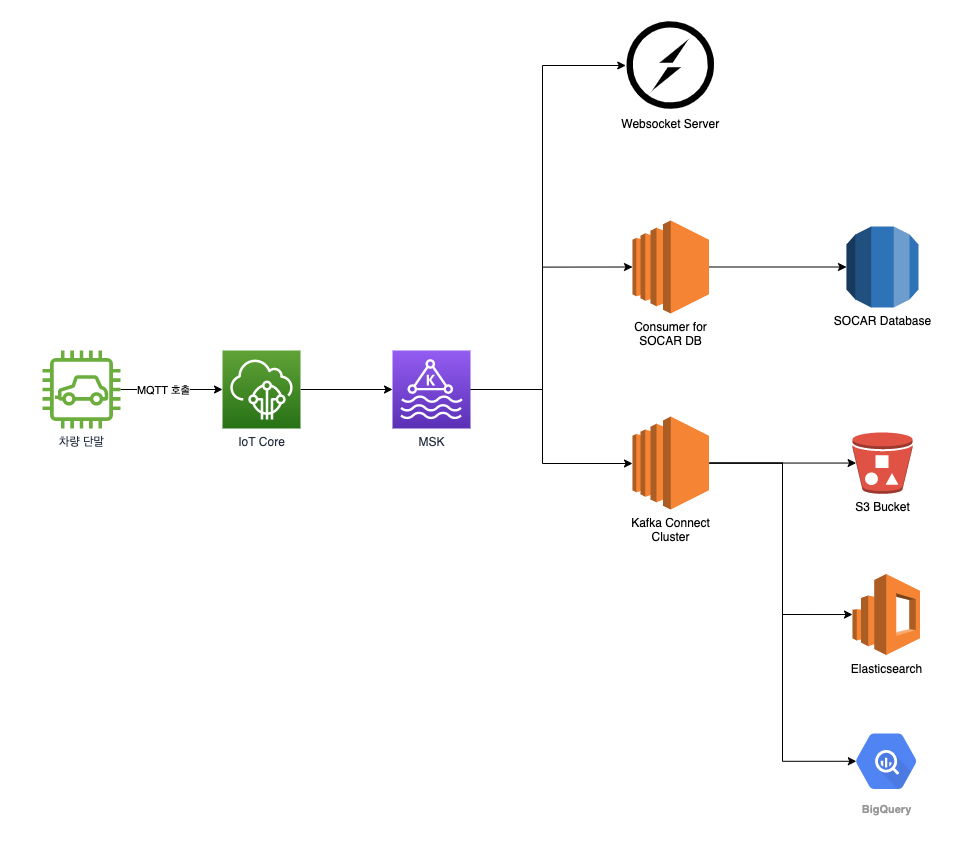
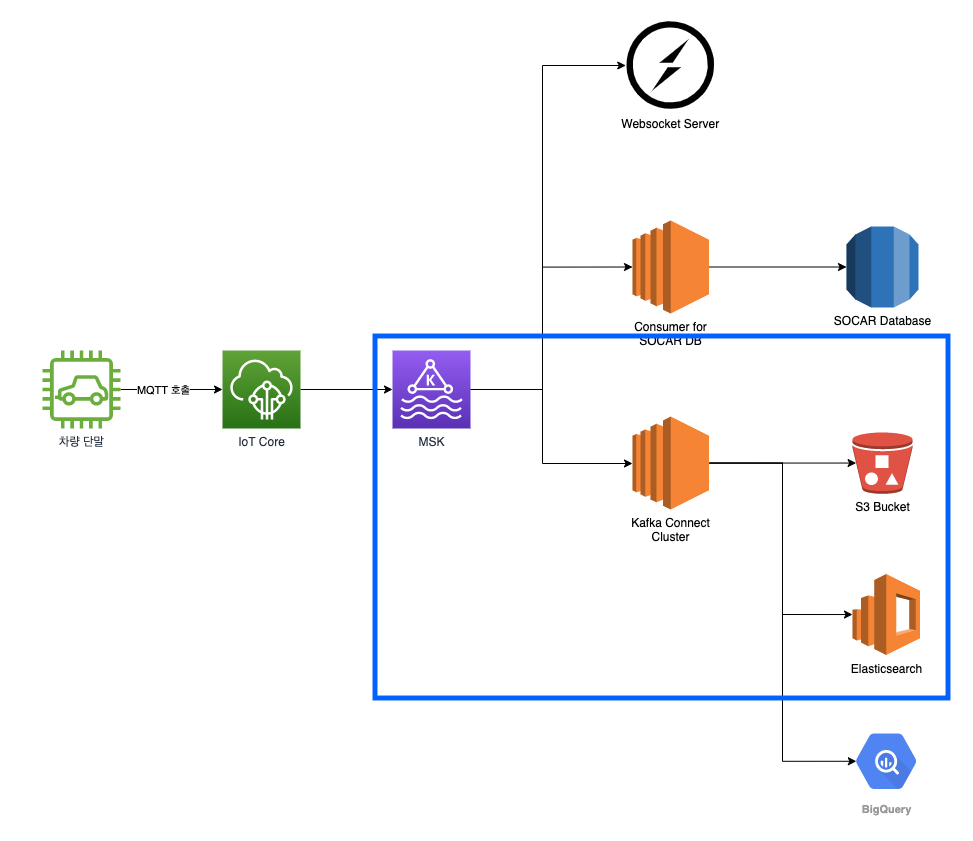
이런 목표들을 가지고 설계한 파이프라인을 통해 차량에서 수집한 정보를 보고받고, MSK의 토픽에 정보가 담긴 메시지를 전달하며, 각각의 Consumer가 MSK에 붙어 필요한 데이터들을 가져갈 수 있는 기존보다 안정적인 새로운 파이프라인을 구성하기로 했습니다.
이제 본격적으로 파이프라인을 구현해볼까요?
본격적으로 신규 단말 파이프라인을 구축해봅시다
쏘카의 신규 단말 파이프라인은 크게 토픽을 관리하며 메시지를 저장하는 Kafka 클러스터와 메시지를 생산하는 Producer, 메시지를 소비하는 Consumer 세 가지로 구성됩니다.
Kafka 클러스터
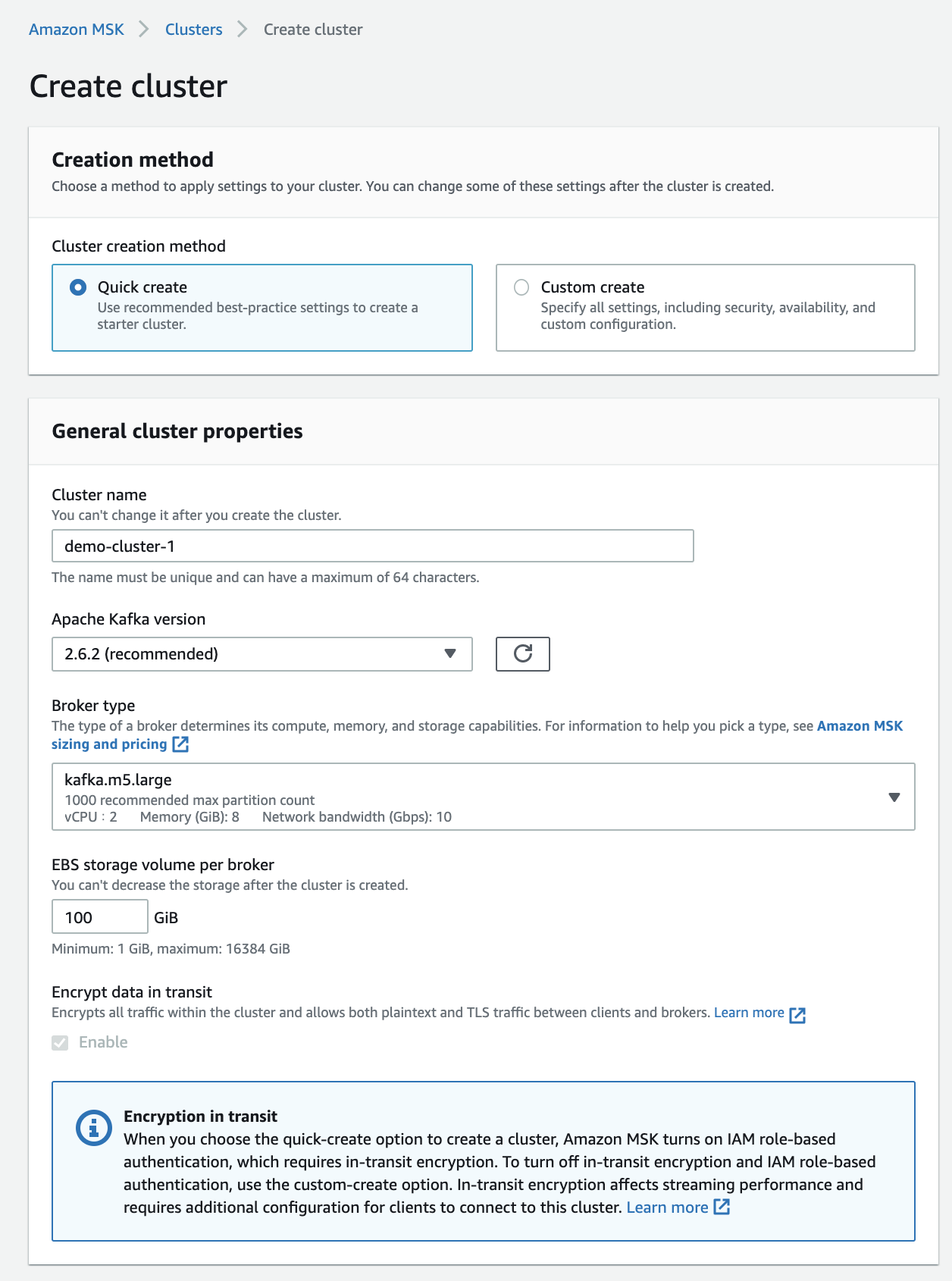
Kafka 클러스터는 AWS MSK를 통해 쉽게 구축할 수 있었습니다. 사용하고자 하는 인스턴스와 브로커 당 용량 및 Kafka의 버전, 보안 설정만 거치면 쉽게 클러스터를 구축할 수 있습니다.
주의할 점은 생성 후 클러스터의 설정 변경에 제약이 있다는 점입니다. 예를 들어 인스턴스의 타입은 자유롭게 Up & Down이 가능하나, 브로커의 수량과 브로커의 용량은 증설만 가능합니다. (이 부분을 놓쳐 초기에 클러스터를 여러 번 새로 만드는 고생하기도 했습니다)
스토리지의 경우 그동안 기존 파이프라인을 운영했던 데이터에 기반하여 최대 피크 수준도 버틸 수 있도록 설정했습니다. 이를 넘어서서 스토리지가 꽉 차게 되면 메시지가 유실되는 문제가 발생합니다. 이런 문제를 겪지 않도록 MSK에서는 스토리지 오토스케일링 기능을 제공합니다. 전체 용량의 10~80%에 도달하면 Auto Scaling이 되도록 설정이 가능합니다. 다만 안타깝게도 오토 스케일링도 스케일링 업만 가능하며 다운은 불가능하다는 점 유의하셔야 합니다.
마지막으로 Cluster Configuration을 통해 Kafka 클러스터 설정을 할 수 있습니다. Kafka는 스트리밍 데이터 처리 플랫폼으로 데이터를 영구 저장할 수도 있지만 보통은 메시지의 저장 기간을 정해놓고 사용합니다. 장애가 발생해도 2일 이내에 해결하겠다는 마음으로 48시간(2일)로 설정했습니다. 이외 자세한 설정값들은 Kafka 문서를 참고해주세요.
log.cleanup.policy: delete
log.retention.hours: 48
이렇게 기본적인 클러스터 설정이 끝나면 수분 내에 Kafka 클러스터가 생성됩니다. 이제 메시지를 위한 토픽을 만들어주어야겠죠. 로컬 머신에 MSK와 같은 버전(권장)의 Kafka를 다운로드하시면 기본적으로 제공하는 CLI를 이용하여 토픽을 생성할 수 있습니다. (또는 원하는 언어의 Kafka 클라이언트를 통해서도 생성할 수 있어요!)
/bin/kafka-topics.sh --create \
--zookeeper <주키퍼 호스트>:<주키퍼 포트> \
--topic <토픽 이름> \
--partitions <파티션 수> \
--replication-factor <복제 팩터>
참고로 auto.create.topics.enable 설정을 켜두면 자동으로 토픽을 생성하게 할 수 있습니다. 저희는 무분별하게 토픽이 생성되는 것을 막고자 이 방식은 사용하지 않았습니다.
토픽 생성 시에는 토픽 이름, 파티션의 개수, 복제 팩터를 설정하게 됩니다.
Kafka는 토픽에 메시지를 저장할 때 파일 시스템을 사용하기 때문에, 파티션을 하나로 지정하면 브로커의 I/O에 따라 성능이 좌지우지됩니다. 따라서 클러스터의 브로커 수, 데이터의 크기, Consumer의 수 같은 요소를 적절하게 고려하여 파티션의 수량을 정해야 합니다.
복제 팩터는 중요한 설정 중 하나로, 하나의 파티션이 몇 개까지 복제될지를 설정하는 수치입니다. MSK는 중요 보안 업데이트나 설정 변경 시에 브로커를 한 대씩 차례차례 재부팅합니다. 이때 복제 팩터가 1인 경우 해당 파티션이 있는 브로커가 업데이트 등으로 인해 잠시 OFF되어 있을 때 Producer가 해당 파티션에 데이터를 쓰려고 하면 데이터 유실이 발생할 수 있습니다. 이러한 문제 없이 운영하기 위해서는 복제 팩터를 최소 2 이상으로 설정해 주셔야 합니다. 2 이상으로 설정한 경우, 기존 파티션 Leader를 가지고 있던 브로커가 OFF 되어도 복제본을 갖고 있던 다른 브로커가 파티션 Leader를 넘겨받아 Kafka 클러스터가 다운타임 없이 정상적으로 역할을 수행해냅니다.
Producer
Kafka 클러스터가 준비되었으니, 메시지를 생산할 Producer를 설정해 보겠습니다. 엄밀히 말하면 단말에서 차량 정보를 수집하여 전달하는 부분을 Producer라고 볼 수도 있겠지만, 여기서는 Kafka 클러스터를 기준으로 하여, Kafka에 메시지를 생성하는 부분을 Producer의 역할로 정의하겠습니다.
위에서 말씀드린 것처럼, 단말의 펌웨어는 Server-side Application처럼 어느 시점에 한 번에 업데이트하기 어렵습니다. 빨라도 몇 주에서 오래 걸리면 몇 달은 길게 두고 보아야 하는 작업입니다. 이렇게 짧지 않은 기간동안 보고 채널이 파편화되어 있는 동안에도 파이프라인에는 펌웨어 구분 없이 모든 차량에서 수집한 정보가 적재되어야 했습니다. 그렇게 하기 위해 IoT Core의 메시지 생성과 텔레매틱스 서버의 메시지 생성을 모두 구현하게 되었습니다.
IoT Core의 메시지 생성
먼저 신규 펌웨어에서 IoT Core로 차량에서 수집한 정보를 전달하는 경우를 살펴보겠습니다. 단말에서는 차량 정보를 수집하여 IoT Core의 특정 토픽에 보고합니다. 그리고 IoT Core Rule을 만들어 이 정보를 구독할 수 있습니다. 예를 들어 단말은 report라는 토픽에 차량 정보를 보고하고, IoT Core Rule에 report 토픽을 구독하도록 Rule을 생성했다면, 새로운 차량 정보 메시지가 보고될 때마다 Rule에 설정된 작업이 실행됩니다.
IoT Core Rule에 대해 자세히 알아볼까요? IoT Core Rule은 익숙한 SQL 쿼리(정확히는 AWS IoT Core SQL)를 통해 입맛에 맞게 단말에서 보고한 데이터를 가공할 수 있으며, 다른 데이터 시스템으로 전달하는 역할을 수행합니다. 신규 단말 파이프라인에서는 단말에서 JSON 형식의 메시지를 전달받고, 여기에 SQL을 이용하여 Timestamp를 추가해 사용합니다. 이를 위해 다음과 같은 쿼리문을 사용합니다.
SELECT *, parse_time("yyyy-MM-dd'T'HH:mm:ssz", timestamp()) as timestamp
FROM 'report'
AWS IoT Core SQL에서 지원하는 SQL 구문은 일반적인 SQL 구문과 비슷하지만 다를 수 있으니, 자세한 내용은 AWS에서 제공하는 AWS IoT Core SQL 레퍼런스를 참고하시기 바랍니다. IoT Core SQL의 특별한 점을 꼽자면, 무려 Lambda 함수를 실행할 수 있는 Function까지 지원해 원하는 대로 데이터 가공이 가능합니다.
이렇게 원하는 대로 가공을 마쳤다면, 이 데이터를 다른 데이터 시스템으로 전달하기 위해 여러 개의 작업을 설정할 수 있습니다.
작업에는 미리 정의된 약 20개의 템플릿이 있으며, HTTPS 엔드포인트로도 전송할 수 있는 작업까지 준비되어 있어 원하는 대로 커스텀이 가능합니다. 이제 Kafka에 메시지를 전송할 수 있도록 작업을 추가해 보겠습니다.
Apache Kafka 클러스터에 메시지 전송을 선택한 후 구성을 누르면, Kafka의 구성 정보를 입력하여 세팅할 수 있습니다.
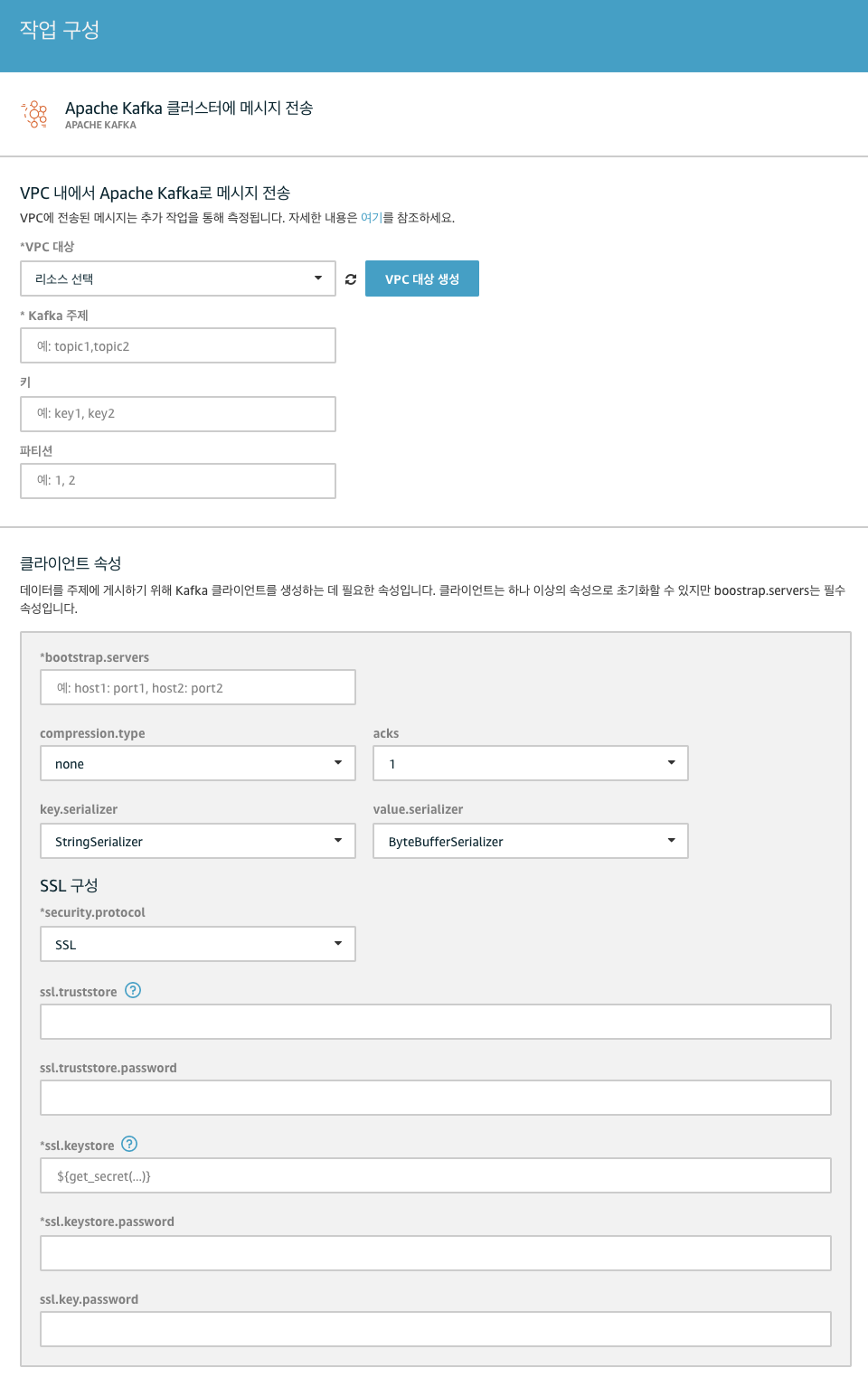
먼저 기본적인 Kafka 정보(Kafka 엔드포인트, SASL 구성 등)를 설정해 주세요. Kafka에서 어떤 토픽에 메시지를 저장할 것인지 토픽 이름을 지정해야 합니다. 저희는 여기서 하나의 토픽에만 메시지를 전달하는 것이 아니라, 차량에서 수집된 정보의 종류에 따라 다른 토픽에 메시지를 전달하고 싶었습니다. 이런 처리를 위해서는 대체 템플릿을 사용할 수 있습니다.
대체 템플릿은 치환자라고 생각하시면 됩니다. IoT SQL 레퍼런스에서 지원하는 SELECT 절, WHERE 절 또는 Function을 사용할 수 있습니다. 쏘카 단말에서 보고하는 정보 중에는 해당 정보의 종류를 나타내는 타입이 존재합니다. 이 타입 별로 토픽을 분리하기 위해, 토픽 이름을 message-${type} 으로 지정하였습니다. 이렇게 설정하면 log 타입의 메시지는 message-log에, boot 타입의 메시지는 message-boot에 저장하게 됩니다. 토픽이 자동 생성되는 옵션을 켜지 않으신 경우 꼭 미리 각 type에 대한 토픽을 먼저 생성하셔야 한다는 점 잊지 말아 주세요!
다음은 파티션 설정입니다. 파티션은 파티션 번호를 직접 지정할 수도 있고, 지정하지 않으면 Kafka의 DefaultPartitioner에 따라 파티션이 선택되어 메시지가 분배되게 됩니다. 여기에서 카프카의 중요한 특징을 하나 알고 가셔야 하는데, 파티션이 2개 이상인 토픽 내 메시지는 시간 순서가 지켜지지 않는다는 점입니다. 다만 파티션 내에서는 시간 순서가 지켜집니다. 쏘카에서는 각각의 프로젝트에서 실시간으로 데이터를 사용하게 될 때, 최소한 단말기 별로라도 메시지의 시간 순서가 꼭 지켜져야 합니다. 같은 단말의 메시지들이 다른 파티션에 저장되어 시간 순서대로 메시지를 사용할 수 없다면 실시간 처리가 사실상 불가능하게 됩니다. 대체 템플릿을 이용하여 메시지의 Key를 단말 번호인 ${device_no}로 지정하여 같은 단말의 메시지는 같은 파티션에 생성될 수 있도록 설정하여 이와 같은 문제를 해결할 수 있었습니다.
(참고로, Kafka의 DefaultPartitioner는 Key 값이 Null인 경우 해당 토픽의 파티션에 Round Robin 방식으로 분배하며, Key 값이 Null이 아닌 경우 Key 값을 해시화하여 파티션을 선택해 분배합니다)
이렇게 메시지를 IoT Core에서 Kafka 토픽으로 무사히 전달했습니다!
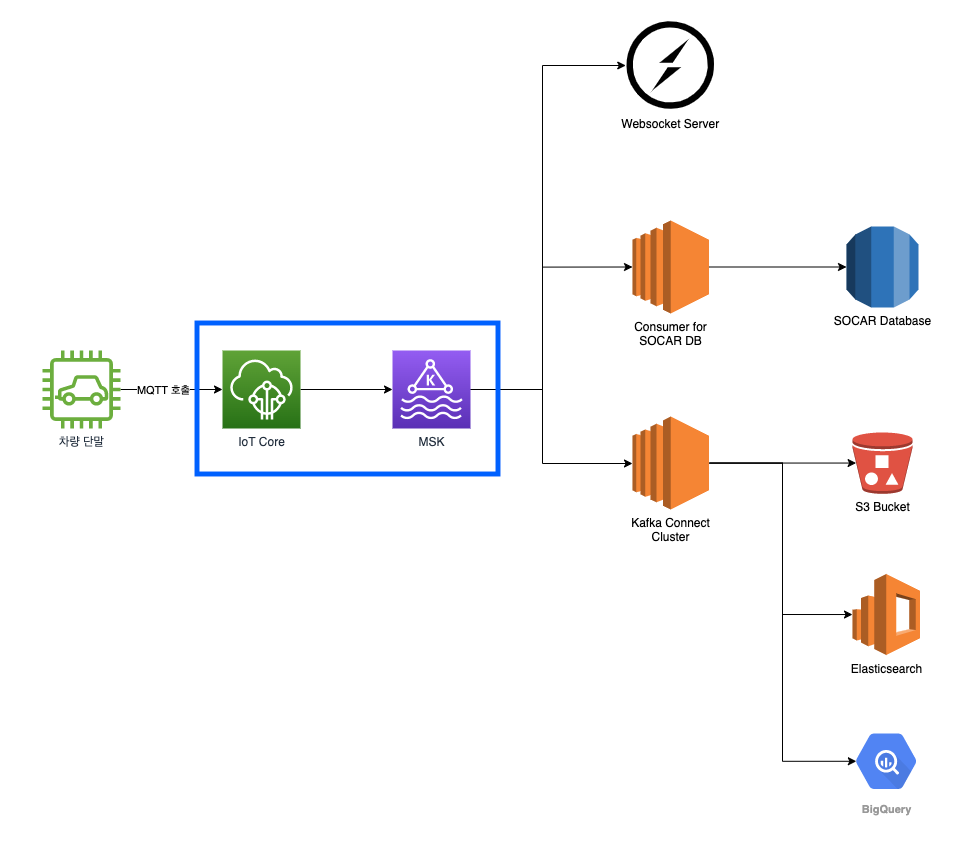
텔레매틱스 서버의 메시지 생성
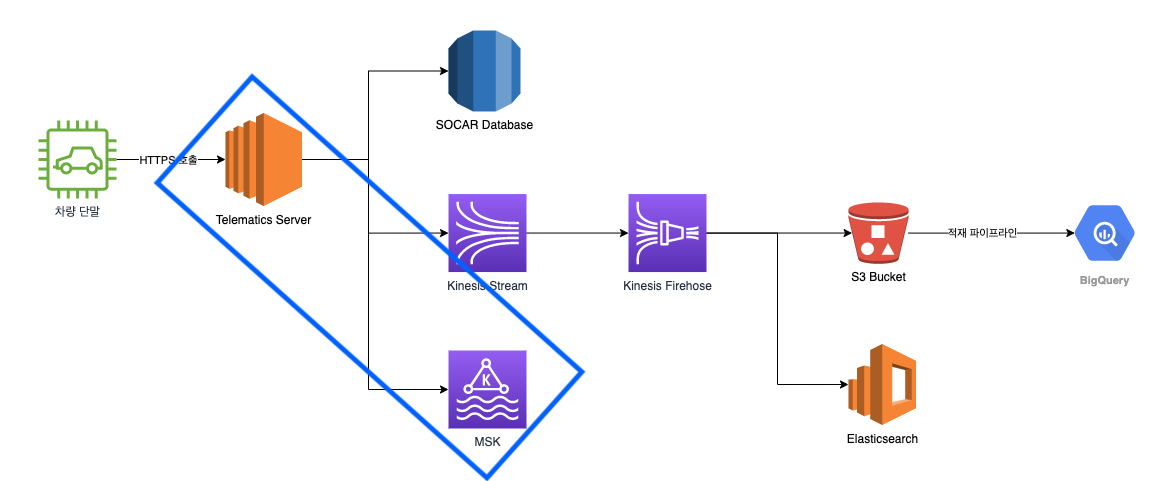
기존에 차량과 통신할 때에는 총 두 채널로 통신했습니다. 명령 전달은 MQTT로 하고, 명령에 대한 응답 보고 혹은 상태 보고들을 텔레매틱스 서버로 HTTPS 방식의 보고를 하고 있었습니다. 이때, 신규 STS 단말기의 데이터 형태와 구형 단말기(CSA 단말기)의 형태가 달라 데이터를 호환시켜주는 모듈을 거쳐 동일하게 데이터가 쏘카 데이터베이스에 적재될 수 있도록 하는 일련의 과정들을 거칩니다.
텔레매틱스 서버가 AWS IoT Core로 전환이 된다면, HTTPS로 텔레매틱스 서버에 상태 데이터를 전달하고 쏘카 데이터베이스에 적재되는 일련의 과정들이 생략됩니다. 기존의 연구나 분석에 사용하고 있던 데이터의 형태가 달라질 수 있기 때문에 기존에 보내고 있는 데이터의 형태와 호환성을 잘 가져갈 수 있도록 하는 것을 우선적인 목표로 잡았습니다.
첫 번째로, 텔레매틱스 서버로 차량이 상태를 보고 하게 되면, 차량의 정보와 상태가 담긴 데이터가 Kinesis와 Kafka로 동시에 보내도록 작업을 했습니다. Kafka는 데이터를 전송할 때 여러 개의 토픽으로 나누어 데이터를 전송할 수 있습니다. 그 기능을 활용해 차량에서 올라오는 데이터들을 GPS, Kinematic, ADAS와 차량 주기 보고 데이터 등 각각 다른 토픽에 전송했습니다. 이로써 차량 데이터가 쏘카 데이터베이스에 저장됨은 물론, 프로젝트별로 데이터를 가져갈 때 실시간 데이터를 원하는 정보만, 원하는 토픽만을 가져와서 쉽게 처리할 수 있게 되었습니다.
Kafka로 데이터를 보내기 위해 작업하는 도중, 서버 앞단의 트래픽을 보조하기 위해 사용한 uWSGI 모듈과 Python에서 Kafka를 사용할 수 있게 해 주는 kafka-python 모듈 간에 서로 충돌이 생겨서 첫 테스트에는 많은 어려움을 겪었습니다. 결국 uWSGI을 gunicorn으로 대체하고, Kafka 라이브러리도 kafka-python 대신 AWS가 제공하는 라이브러리인 boto3로 대체했습니다.
두 번째로, IoT Core에서 전송된 데이터를 판별하여 데이터베이스에 적재할 수 있도록 고민이 필요했습니다. 단말기가 IoT Core로 보고하고 데이터가 바로 Kafka로 전송이 된다면, 데이터베이스에 데이터를 저장해 주는 역할을 하는 텔레매틱스 서버를 거치지 않기 때문에 차량 정보에 대해 저장이 어렵게 됩니다. 이를 위해 AWS IoT Core에 Rule을 추가해 주어 IoT Core의 데이터가 바로 Kafka로 전송되지 않고, 텔레매틱스 서버를 한번 거쳐서 Kafka로 전송할 수 있도록 해주었습니다. 텔레매틱스 서버에서 IoT Core에 대한 새로운 엔드포인트를 만들고, 해당하는 엔드포인트에서 데이터를 받아온 후 판별하여 Kafka 토픽별로 전송했습니다.
IoT Core를 도입하면서 텔레매틱스 서버의 역할을 점차 줄여나가고, 결국에는 텔레매틱스 서버의 역할을 Kakfa와 연결된 Consumer 들에서 처리할 수 있도록 기능들을 점차 옮기려고 합니다. 현재는 여러 차량들을 놓고 테스트해 보고 있습니다. IoT Core를 적용 한 차량이 기존 차량과 동일하게 큰 어려움 없이 차량 데이터를 보내주고 있습니다. 아직은 초기지만, 많은 차량들이 점차 업데이트가 되어서 IoT Core로 데이터를 보낼 수 있게 되는 날이 벌써 기대가 됩니다.
Consumer
이제 수집된 차량 정보가 Kafka 토픽에 안전하게 저장되어 있습니다. 이 데이터를 적재적소에 가져다가 활용하면 됩니다. 하지만 카프카는 영구 저장소가 아니라서, 우리가 설정한 값에 따르면 2일 후에 사라지게 됩니다. 먼저 이를 더 오랫동안 보관하고 활용할 수 있는 공간으로 먼저 저장해야 합니다. 이런 툴을 일일이 개발해야 할까요?
Kafka Connect
물론 자신 있는 언어의 Kafka 클라이언트를 이용하여 Consumer를 한 땀 한 땀 개발할 수도 있겠지만, Kafka 생태계에서는 Kafka와 다른 데이터 시스템 사이를 쉽고 믿을 수 있게 이어줄 수 있는 Kafka Connect를 제공합니다.
많은 회사와 개발자들이 사용하는 RDBMS부터 NoSQL, S3 같은 클라우드 저장소, Elasticsearch 등 수많은 데이터 시스템과 카프카를 이어주는 Connector를 공식적으로 제공하고 있으며, 커뮤니티에서 만든 비공식의 Connector들도 활발하게 만들어져 있어 Kafka Connect 클러스터만 구축한다면 Connector들을 바로 사용할 수 있습니다.
다른 데이터 시스템에서 Kafka로 데이터를 가져오는 커넥터를 Source Connector라 하고, Kafka에서 다른 데이터 시스템으로 데이터를 적재하는 커넥터를 Sink Connector라고 합니다. 우리는 Kafka에 있는 데이터를 소비하는 Consumer를 만드는 과정이므로 Sink Connector를 설정해보겠습니다.
쏘카의 단말 데이터는 오래 저장하고 다시 여러 가지 용도로 사용할 수 있도록 1차적으로 S3에 저장하고 있으며, 최신 데이터는 바로 분석과 연구에 사용할 수 있도록 Elasticsearch에 적재해 활용하고 있습니다.
Kafka Connect 클러스터는 구축되어 있다고 가정하고, 바로 Sink Connector를 설정해보겠습니다. Kafka Connect에서는 Connector를 실행시킬 수 있는 REST API를 제공합니다. S3와 Elasticsearch Sink Connector를 세팅하면서 자세히 알아보도록 하겠습니다.
S3 Sink Connector
Confluent에서 공식으로 제공하는 S3 Sink Connector입니다. 다음 요청을 통해 해당 커넥터를 이용한 Worker를 생성할 수 있습니다.
Endpoint : POST ${카프카_커넥트_호스트}/connectors
{
"name":"s3-sink-worker",
"config": {
// 사용하려는 커넥터의 클래스 이름
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
// S3가 위치한 리전
"s3.region": "ap-northeast-2",
"partition.duration.ms": "180000",
// 여기서 지정한 수만큼 메시지가 쌓이면 S3에 파일로 저장합니다.
"flush.size": "20000",
"schema.compatibility": "NONE",
// 메시지를 가져오려는 카프카의 토픽 이름을 지정합니다. 콤마를 사용해 여러 토픽을 가져올 수 있습니다.
"topics": "토픽 이름",
// 하나의 파일이 가질 최대 용량을 지정합니다.
"s3.part.size": "5242880",
// 타임존을 지정합니다.
"timezone": "Asia/Seoul",
// 로케일을 지정합니다.
"locale": "ko_KR",
// 압축 방식을 지정합니다. none 또는 gzip을 사용할 수 있습니다.
"s3.compression.type": "gzip",
// 데이터 포맷을 지정힙니다. JSON 타입이므로 JsonFormat을 사용합니다.
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
// 메시지를 어떻게 파티셔닝할지 설정합니다. 여기서는 TimeBasedPartitioner를 사용하여 날짜 기준으로 S3에 저장되는 폴더를 분리합니다.
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
// S3Storage로 지정해주시면 됩니다.
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
// 저장될 S3의 버킷 이름입니다.
"s3.bucket.name": "S3 버킷 이름",
// 얼마나 주기적으로 S3에 파일을 저장할지 설정합니다. flush.size에서 설정한 메시지 수에 도달하지 않아도 해당 주기가 되면 S3에 파일을 쓰게 됩니다.
"rotate.schedule.interval.ms": "180000",
// 파일이 저장될 위치를 설정합니다. 시간 기반의 파티셔닝을 통해 시간별로 폴더가 나눠지도록 설정했습니다.
"path.format": "YYYY/MM/dd/HH"
}
}
Worker를 생성한 후, 다음 REST API를 통해 Worker가 제대로 동작하는지 확인하실 수 있습니다.
Endpoint : ${카프카_커넥트_호스트}/connectors?expand=info&expand=status
{
"s3-sink-worker": {
"status": {
"name": "s3-sink-worker",
"connector": {
"state": "RUNNING",
"worker_id": "Worker 1"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "Worker 1"
},
{
"id": 1,
"state": "RUNNING",
"worker_id": "Worker 2"
},
{
"id": 2,
"state": "RUNNING",
"worker_id": "Worker 3"
}
],
"type": "sink"
},
"info": {
"name": "s3-sink-worker",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"s3.region": "ap-northeast-2",
"partition.duration.ms": "180000",
"flush.size": "20000",
"schema.compatibility": "NONE",
"topics": "토픽 이름",
"s3.part.size": "5242880",
"timezone": "Asia/Seoul",
"locale": "ko_KR",
"s3.compression.type": "gzip",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"s3.bucket.name": "S3 버킷 이름",
"rotate.schedule.interval.ms": "180000",
"path.format": "YYYY/MM/dd/HH"
},
"tasks": [
{
"connector": "s3-sink-worker",
"task": 0
},
{
"connector": "s3-sink-worker",
"task": 1
},
{
"connector": "s3-sink-worker",
"task": 2
}
],
"type": "sink"
}
},
}
다른 문제가 없다면 수 분 내로 S3의 파일로 메시지가 잘 적재되는 모습을 확인하실 수 있습니다.
Kafka Connect의 Worker들은 동작하면서 필요한 메타데이터를 Kafka에 별도의 토픽으로 저장합니다. Worker는 자신의 업무 프로세스를 기억하기 위해 순차적으로 토픽의 파티션에서 데이터를 읽어가면서 책갈피를 꽂아둡니다. 이 책갈피를 Offset이라고 합니다. Kafka Connect는 프로세스가 죽어서 Worker가 재시작되는 상황이 발생해도 이 메타데이터를 다시 읽어와 책갈피를 꽂은 부분에서부터 다시 데이터를 읽어가도록 설계되어 있습니다.
Elasticsearch Sink Connector
S3에 무사히 적재했다면, 다음은 분석과 연구를 위한 Elasticsearch에 적재해보겠습니다. Confluent에서 공식으로 제공하는 Elasticsearch Sink Connector를 사용합니다. S3 Sink Connector와 같은 방식으로 생성하는데, 다음과 같은 요청을 통해 Elasticsearch Sink Worker를 실행할 수 있습니다.
Endpoint : POST ${카프카_커넥트_호스트}/connectors
{
"name":"es-sink-worker",
"config": {
// 사용하려는 커넥터의 클래스 이름
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
// Elasticsearch7부터는 type이 사라져, _doc로 지정하면 됩니다.
"type.name": "_doc",
"behavior.on.null.values": "IGNORE",
// 메시지를 가져오려는 토픽 이름
"topics": "토픽 이름",
// true일 때, 메시지에 문제가 있는 경우 무시합니다.
"drop.invalid.message": "true",
// 문제가 생긴 경우 최대 재시도 횟수를 설정합니다.
"max.retries": "50",
// true일 때, Elasticsearch 문서의 키로 메시지의 key를 사용하지 않고, topic+partition+offset를 사용합니다. ex) message-log+0+1
"key.ignore": "true",
// Elasticsearch 동시 요청 수를 제한합니다. retry.backoff.ms: 요청 실패 후 재시도까지 기다릴 시간을 설정합니다. 다음 재시도할 때엔 이전 재시도 대기 시간보다 2배 더 기다립니다.
"max.in.flight.requests": "20",
"retry.backoff.ms": "2000",
// 사용하려는 Elasticsearch의 Endpoint
"connection.url": "ELASTICSEARCH_ENDPOINT",
// Elasticsearch 서버와의 Read Timeout을 설정합니다.
"read.timeout.ms": "60000",
// 주어진 시간만큼 데이터가 쌓이기를 기다린 다음, Bulk Request로 처리하여 효율성을 높입니다. connection.compression: Elasticsearch 서버와 통신 시에 gzip 압축을 사용할지 여부를 선택합니다.
"linger.ms": "1000",
"connection.compression": "true",
// 메시지가 원하는 만큼 쌓이지 않았더라도, 해당 주기가 되면 Elasticsearch로 메시지를 전송합니다.
"flush.timeout.ms": "60000",
// 배치로 처리할 메시지의 수
"batch.size": "2000",
// 최대 버퍼 될 레코드의 수, 태스크 당 메모리 사용량 제한을 위해 사용합니다.
"max.buffered.records": "40000"
}
}
S3 커넥터 설정할 때와 마찬가지로 REST API를 통해 Worker가 정상적으로 동작하고 있는지를 확인해 주세요. 잠시만 기다리면 Elasticsearch에도 메시지가 잘 적재되는 것을 확인하실 수 있습니다!
Elasticsearch Sink Connector에는 알려진 버그가 있습니다. 쏘카에서는 최신의 단말 데이터만 Elasticsearch에서 활용하고 있어서 일자별로 인덱스를 생성하고, 며칠 뒤 오래된 인덱스를 삭제하는 형식을 취하고 있습니다. Elasticsearch Sink Connector는 TimebasedPartitioner를 사용하면 Offset을 제대로 기록하지 못해 설정을 변경하는 등의 이유로 Worker를 재시작할 때마다 토픽에 있는 모든 데이터를 처음부터 다시 읽는 버그가 있습니다.
이를 해결하기 위해, Elasticsearch Sink Connector를 사용할 때에는 TimeBasedPartitioner를 사용하지 않고 Elasticsearch의 Index를 고정하여 사용하기로 했습니다. Elasticsearch에서 Index를 생성할 때 Write Index와 Rollover를 사용하여 Index가 일자별로 자동으로 생성되도록 데이터가 저장되도록 설정해 이 문제를 해결할 수 있었습니다.
단말-차량 Converter
“단말-차량 Converter”는 모비딕 팀에서 최근에 시작한 프로젝트로, Kafka의 도입과 비슷한 시기에 시작한 프로젝트입니다. Kafka에서 수집하는 차량의 데이터는 거의 실시간으로 파악할 수 있기 때문에 이 데이터의 활용도가 무척 높을 거라고 생각했습니다.
차량 데이터는 차량 단말기 번호를 기준으로 수집되는데, “단말-차량 Converter”는 이 데이터를 바로 사용할 수 있도록, 데이터를 변형하여 Kafka로 다시 흘려보내주는 역할을 합니다. 즉, “단말-차량 Converter”는 확장성이 높은 첫 Consumer이자 동시에 데이터를 제공해 주는 Producer 역할을 동시에 하게 됩니다. 이렇게 수집된 데이터는 원하는 곳에서, 필요한 만큼 실시간으로 확인할 수 있습니다.
“단말-차량 Converter”의 기능을 구체적으로 말씀드리면, 단말기에서 올라온 정보를 기반으로 차량 정보를 매칭해 주고, 해당하는 데이터가 어떤 차량의 어떤 상태인지 파악할 수 있도록 데이터 조립을 해 줍니다. 차량의 정보를 데이터베이스에서 계속 가져온다면 너무 비효율적이기 때문에, 임시로 저장해 놓은 캐싱 된 데이터를 사용하고, 일정 주기로 데이터를 새로 받아오는 일들을 하고 있습니다.
이렇게 조립한 데이터들이 앞으로 필요한 프로젝트들에 잘 활용될거라 기대하고 있습니다. 또한 어떤 프로젝트든 쉽게 데이터를 사용할 수 있게 데이터를 좀 더 유연하게 설계해나가고 싶습니다. 추가적으로 필요한 연산 작업이라든지, 적재 작업들도 “단말-차량 Converter”를 통해 만들어나갈 수 있을 것 같고, 최근 뜨고 있는 스트림 처리 프레임워크인 Flink를 써 볼 수 있지 않을까 하는 기대감도 가지고 있습니다.
단말 파이프라인 모니터링
구축한 단말 파이프라인이 문제 없이 원활히 흘러가도록 하려면 모니터링의 역할도 아주 중요합니다.
쏘카에는 여러 모니터링 시스템이 구축되어 있는데, 그중 Grafana를 통해 단말 파이프라인 모니터링 대시보드를 구축했습니다. 데이터 소스로 CloudWatch가 이미 연동되어 있어, MSK의 중요한 메트릭으로 대시보드를 꾸리기만 하면 완성입니다.
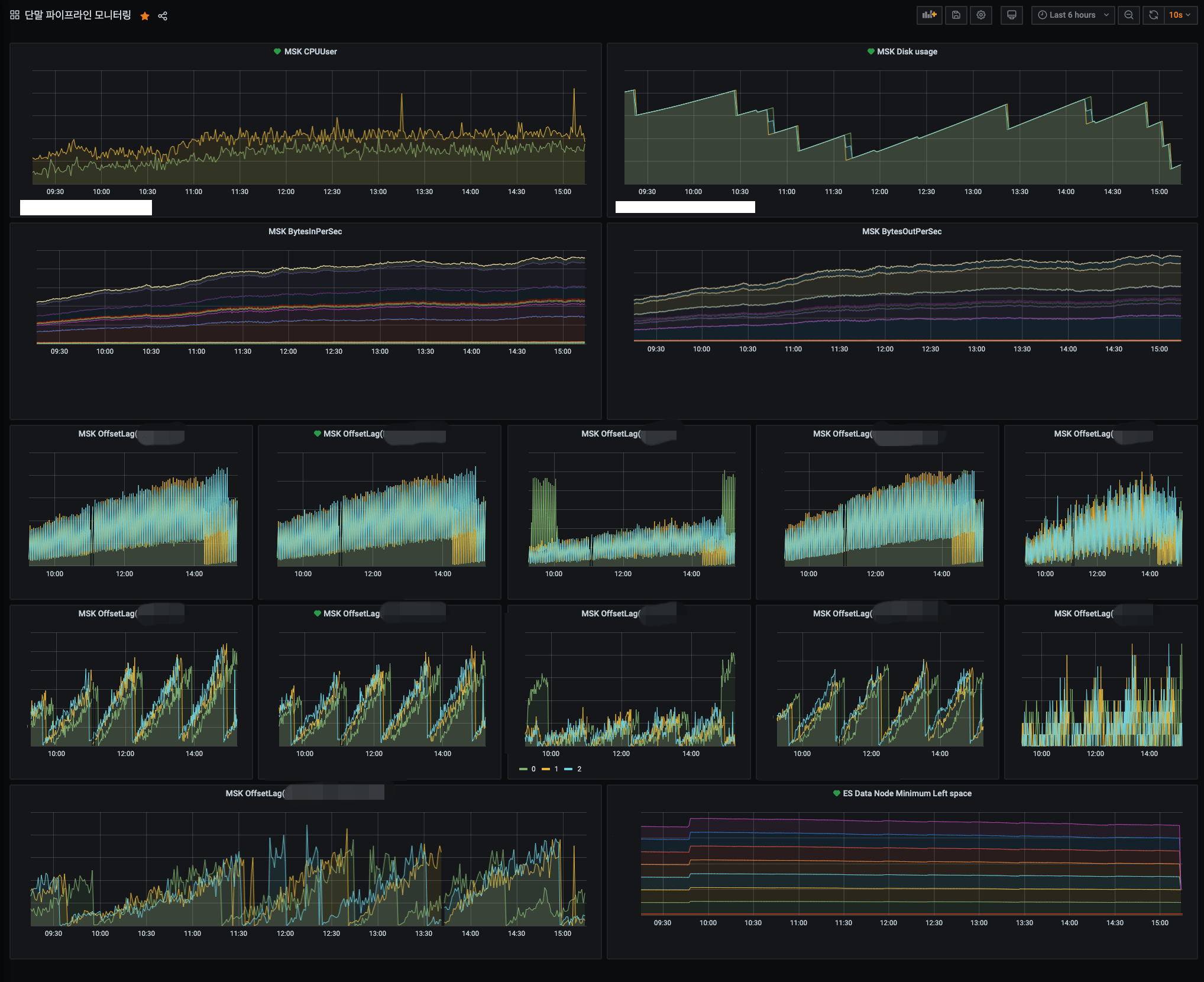 운영 중인 Grafana 대시보드
운영 중인 Grafana 대시보드
CPU, Disk 사용량, 네트워크 In/Out, Elasticsearch의 스토리지 사용량을 기본적으로 모니터링하고 있으며, 각 Consumer의 OffsetLag까지 추가적으로 모니터링하여 각 Consumer에서 데이터를 가져가는 데에 지연이 발생하지 않는지를 모니터링하고 있습니다.
OffsetLag가 무엇일까요? 각 Consumer에서는 토픽의 파티션 별로 메시지를 어디까지 가져갔는지를 기록하는 책갈피를 남겨놓는다고 했는데, 바로 Offset입니다. 파티션의 가장 마지막 메시지와 Offset의 차이가 OffsetLag입니다. OffsetLag가 줄어들지 않고 지속적으로 증가하는 경우 해당 Consumer가 제대로 동작하지 않는다고 판단할 수 있고, 이를 통하여 Consumer의 장애를 인지하고 장애에 대한 조치를 수행할 수 있습니다.
(참고로 OffsetLag는 MSK의 고급 모니터링 옵션을 사용해야 모니터링이 가능합니다.)
이렇게 단말 데이터 파이프라인을 모니터링할 수 있는 대시보드가 완성되었습니다! 필요한 메트릭에 알림을 만들어, 임계치에 도달한 경우 Slack 또는 Opsgenie를 통해 알림을 받아 장애를 인지하고, 조치하고 있습니다.
마치며
여전히 신규 데이터 파이프라인 개발은 현재진행형입니다. Schema Registry를 이용해 단말 데이터에 스키마를 입히고, 사내 많은 분들이 활발하게 사용 중인 BigQuery에 스트리밍으로 단말 데이터를 적재해야 하는 등 해야 할 일들이 많이 있습니다.
하지만 첫 술에 배부를 수 없듯이, 이번 목표는 토대를 단단하게 구축하여 어떤 서비스나 프로젝트에 찰떡처럼 붙을 수 있는 파이프라인을 만드는 것이었고, 결과적으로 짧은 시간 안에 소기의 성과를 달성할 수 있었습니다.
이번에 개선한 신규 단말 파이프라인을 토대로 전사에서 단말 데이터를 더욱 잘 활용할 수 있도록 하고, 더 나아가 유저에게 더 나은 쏘카 서비스 경험을 선물할 수 있도록 앞으로도 모비딕 팀이 계속 노력하겠습니다.