 렉스
렉스 마르코
마르코안녕하세요. FMS 엔지니어링팀의 렉스, 마르코입니다.
저희 팀은 쏘카 외 차량 관제를 위한 PoC(Proof of Concept)를 진행했으며, 그 일환으로 주행 이벤트 탐지 파이프라인을 구축했습니다. 이 과정에서 다양한 문제를 해결하며 파이프라인을 지속적으로 개선해왔습니다.
다음과 같은 분들이 읽으면 좋습니다.
- EDA(Event Driven Architecture)에 관심있는 개발자
- 대량의 IoT 트래픽을 처리해야하는 개발자
이 글을 읽는 분들은 아래와 같은 내용들을 얻으실 수 있을거라고 기대합니다.
- 분산된 시스템(MSA)간의 이벤트 순서를 보장하는 방법
- 배치성 동기 시스템을 실시간 이벤트 기반의 비동기 시스템으로 전환 시 고려해야할 사항들
목차
-
팀 소개
-
FMS의 주요 서비스
2.1 주행이벤트란?
2.2 구성하는 원천 데이터 소스
2.3 서비스 상에 제공되는 화면
-
첫 번째 파이프라인 개선기
3.1 기존 파이프라인 소개
3.2 문제 상황 분석
3.3 개선하고자 하는 사항들
3.4 개선하기
3.5 결과
-
두 번째 파이프라인 개선기
4.1 문제 상황 분석
4.2 개선하고자 하는 사항들
4.3 개선하기
4.4 정합성 확보하기
4.5 결과
-
회고
1. 팀 소개

FMS 팀은 차량관제를 위한 서비스를 제공하기 위해 모인 목적 조직팀입니다.
PoC를 진행하며 실시간 관제, 안전점수, 운행일지 등 차량의 관리 및 운영을 효율화하기 위한 차량 관제 플랫폼을 구축했습니다.
2. FMS의 주요 서비스
2.1 주행이벤트란?
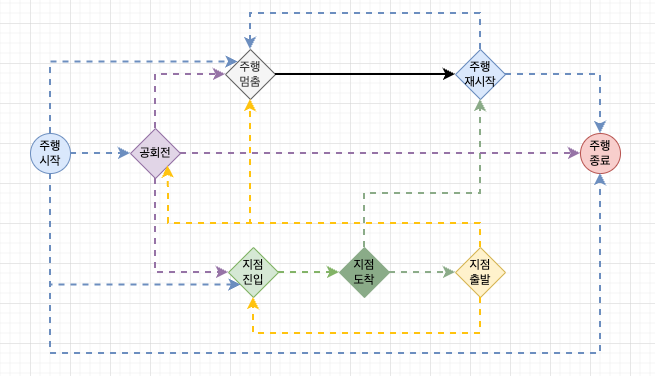
FMS 플랫폼에서는 차량의 주행 시작부터 주행 종료까지를 하나의 트립으로 정의하며, 트립 내에 발생 할 수 있는 이벤트들을 주행 이벤트로 정의합니다.
주행 이벤트는 주행 시작 이벤트로 시작하여 주행 종료 이벤트로 끝나며, 두 이벤트 사이에는 주행 상태에 따른 다양한 이벤트들(차량 상태/Geofence 이벤트)이 포함됩니다.
이 이벤트들은 선행 이벤트를 기준으로 후행 이벤트가 탐지되기 때문에 순서가 중요합니다.
2.2 구성하는 원천 데이터
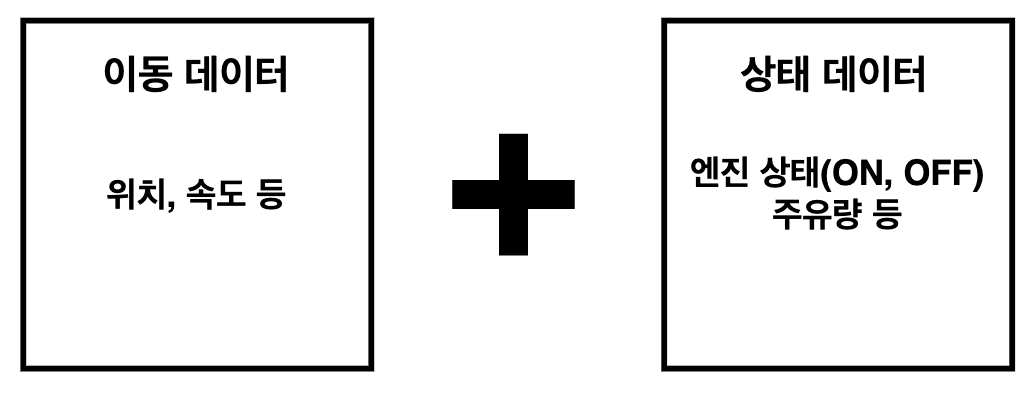
파이프라인에서 다루는 데이터는 크게 두 가지로 구성됩니다.
첫째, 위치와 속도 같은 기하학적 정보를 다루는 이동 데이터입니다. 둘째, 엔진 상태와 주유량 등 상태 정보를 다루는 상태 데이터입니다.
파이프라인에서는 이 두 가지 데이터를 조합하여 주행 이벤트를 탐지합니다.
2.3 서비스 상에 제공되는 화면
주행 이벤트는 실시간 관제, 운행일지, 이동 히스토리 등 다양한 기능의 원천이 됩니다.
트립에서 발생하는 주행 이벤트를 시각화하여, 이동 정보와 실제 지도상의 이동 경로를 제공합니다.
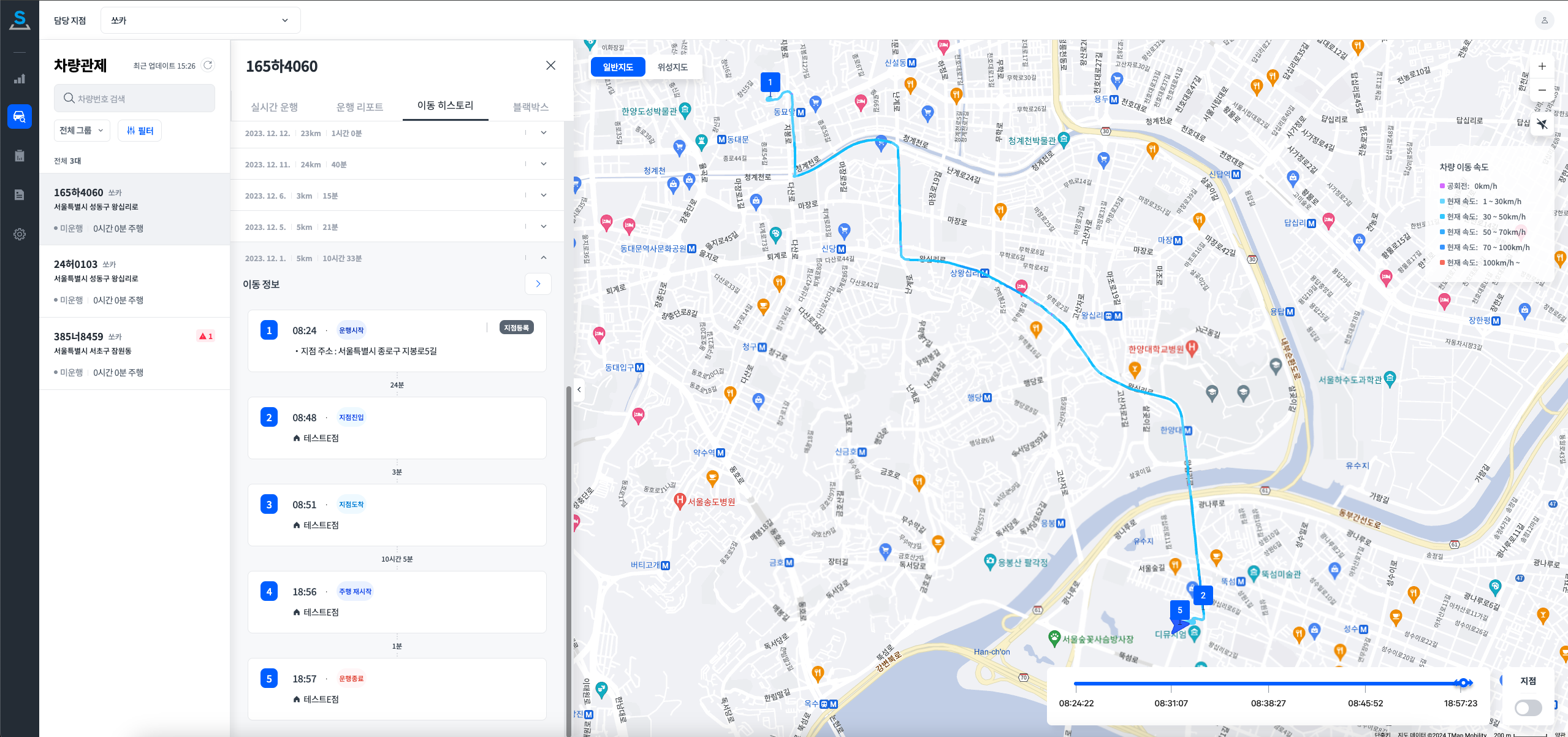
위 이미지는 테스트 차량 기반의 화면입니다.
3. 첫 번째 파이프라인 개선기
3.1 기존 파이프라인 소개
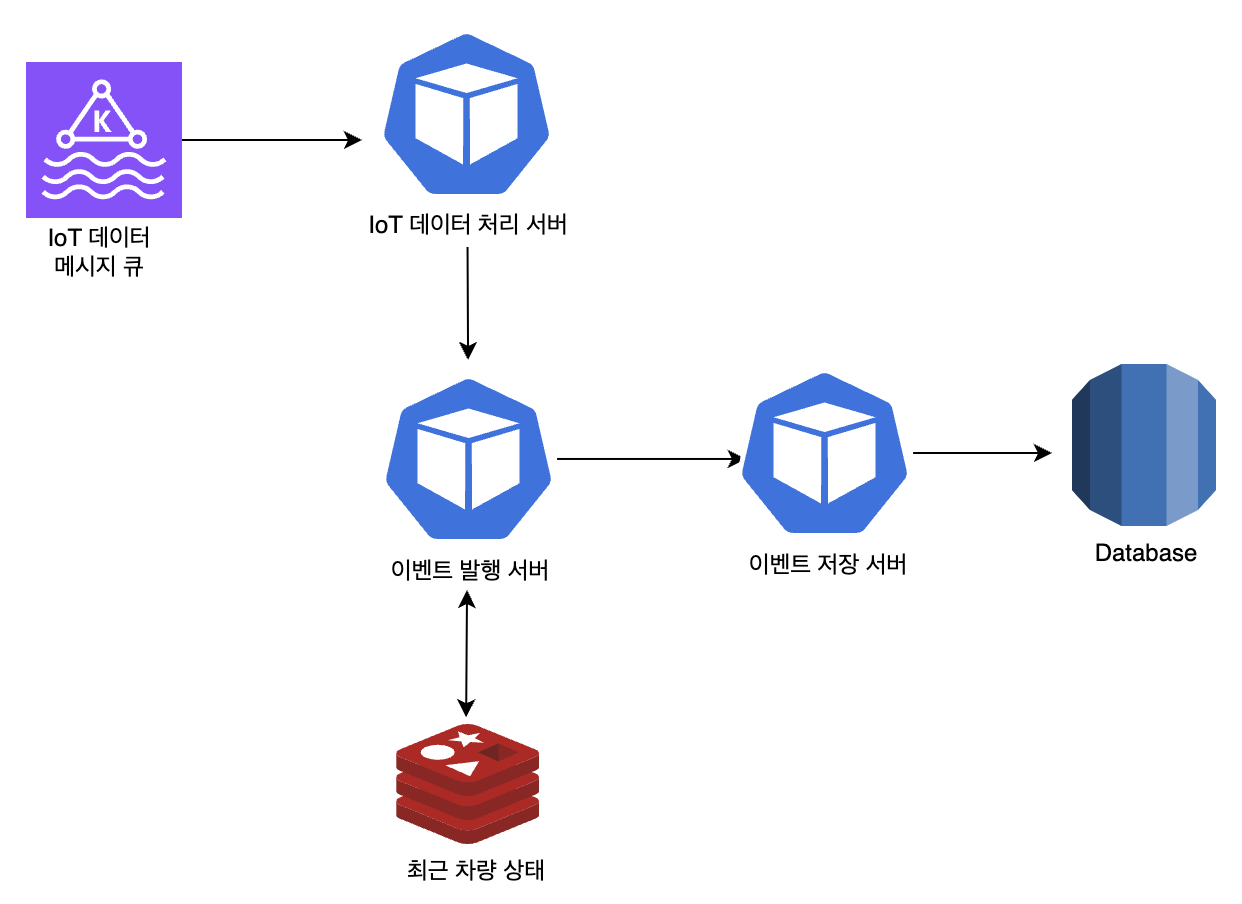
기존 파이프라인은 IoT 데이터를 활용해 이벤트를 발행하면, 최근 차량 상태 정보를 캐싱하고 이벤트 저장 서버가 DB에 저장하는 구조입니다.
IoT 데이터는 최대 2분 동안의 차량 이동 정보와 차량 상태 데이터 프로토콜로 구성됩니다.
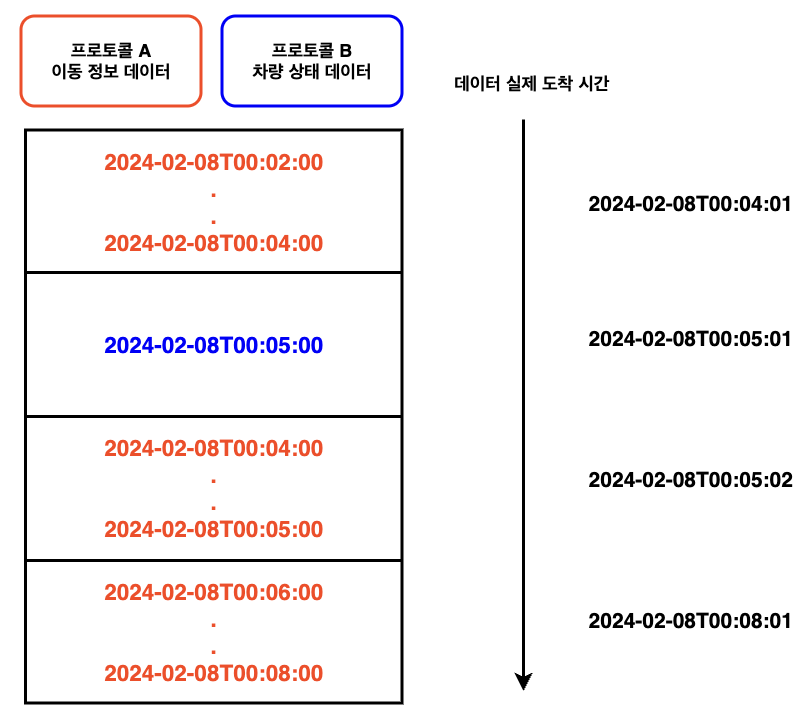
3.2 문제 상황 분석
데이터의 보장되지 않는 순서
주행이벤트는 데이터의 순서가 필수적으로 지켜져야 합니다. 순서가 보장되지 않으면 선/후행 관계가 중요한 이벤트의 정합성이 깨질 수 있기 때문입니다.
초기 파이프라인에서는 IoT 단말기로부터 올라오는 데이터를 제어없이 처리 했기 때문에 서로 다른 프로토콜 간에는 데이터 순서가 지켜지지 않았습니다.
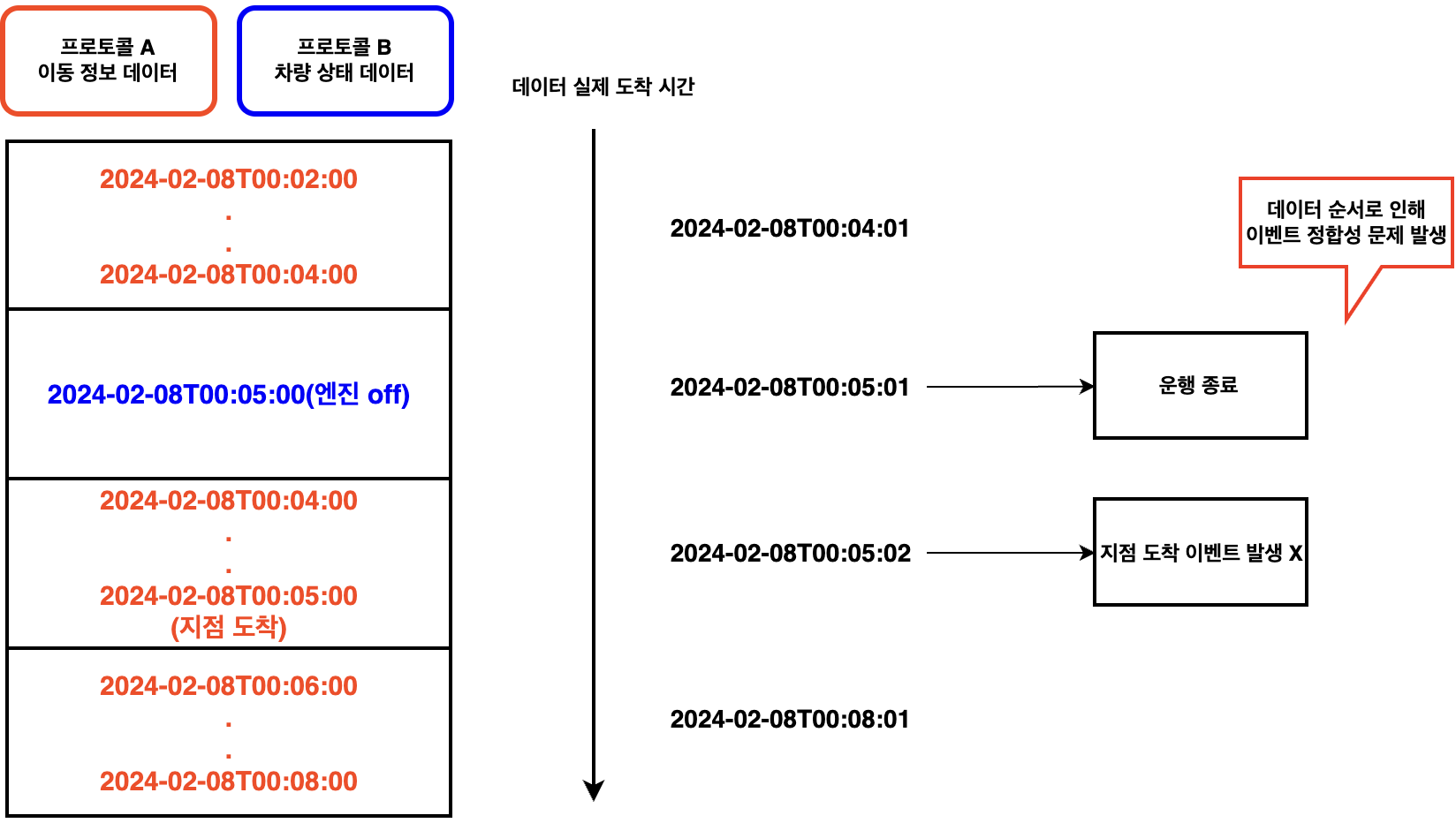
뿐만 아니라 같은 프로토콜 내에서도 데이터 묶음의 개수가 달라 도착 주기가 변경되면, 이벤트 발행 서버에서 동시에 처리되어 데이터 순서가 보장되지 않았습니다.
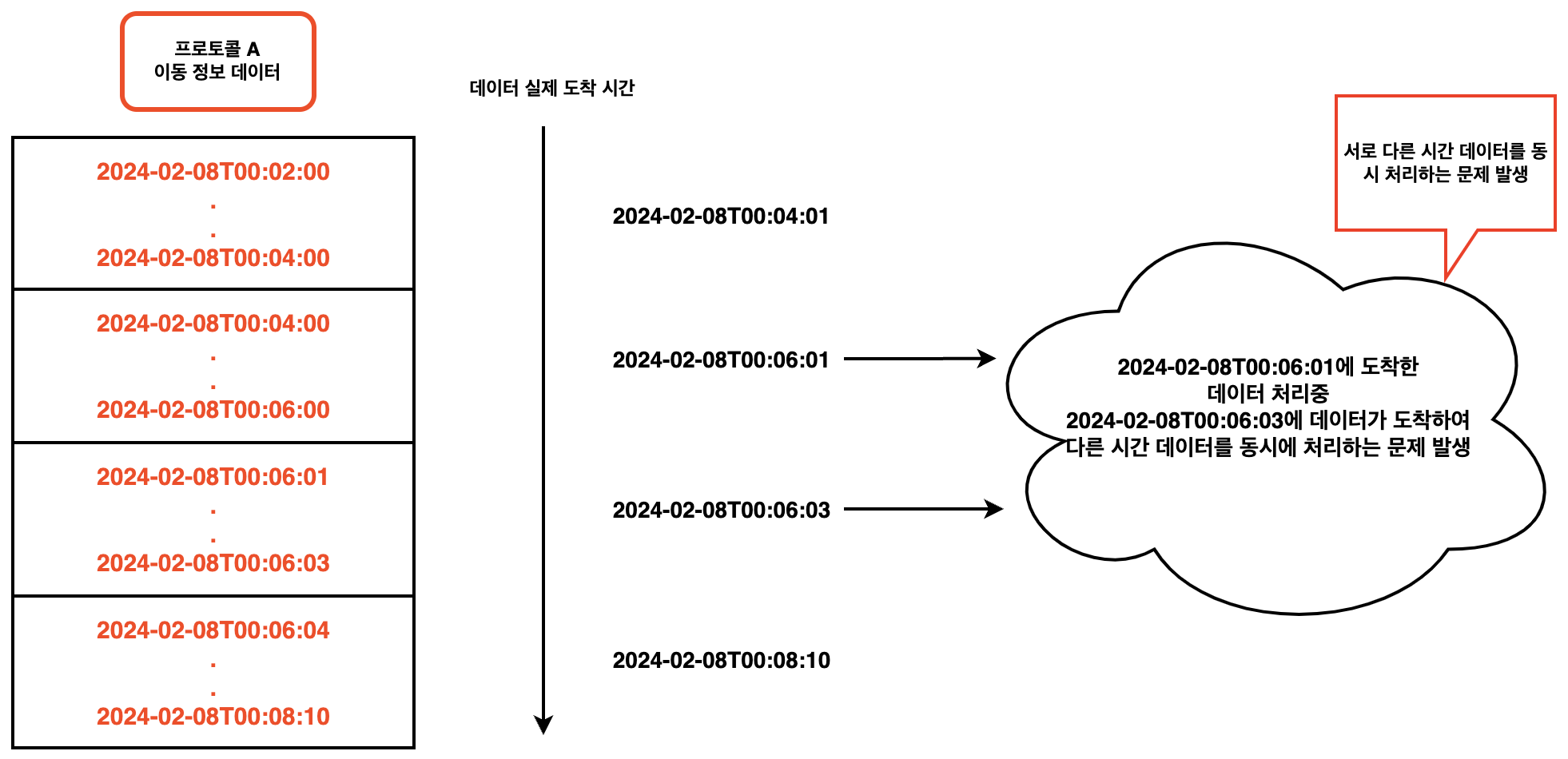
3.3 개선하고자 하는 사항들
데이터의 순서를 보장하자
문제를 해결하기 위해서는 데이터 순서를 보장하는 것이 필요했습니다. 이를 위해 이벤트 탐지에 필요한 데이터의 순서를 보장 하고자 했고, DB를 사용하기로 결정했습니다. 단말기에서 올라오는 데이터를 DB에 적재하면 쿼리를 통해 데이터를 제어할 수 있다고 판단했기 때문입니다.
3.4 개선하기
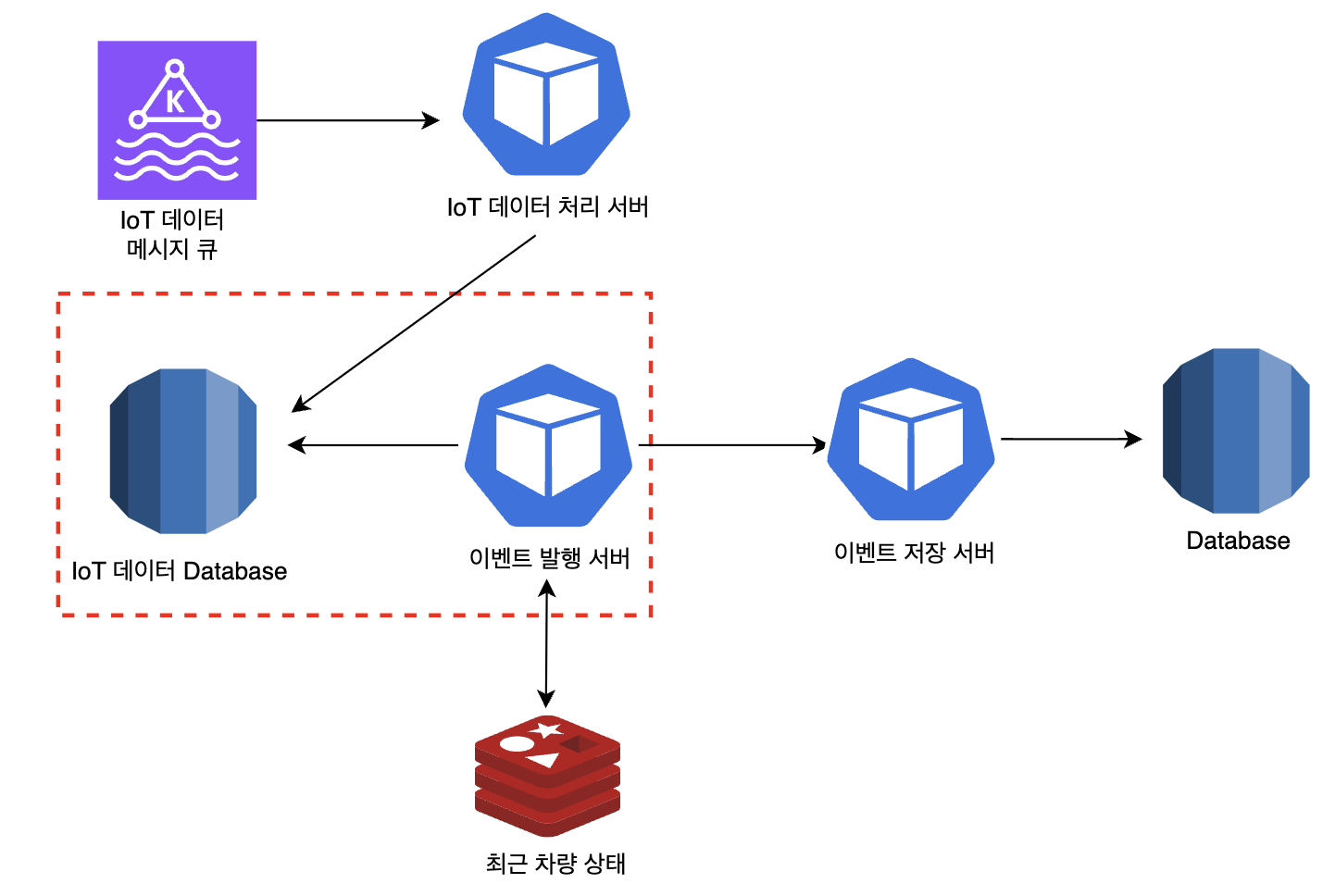
단말기에서 올라오는 IoT 데이터를 바로 처리 하는 것이 아닌 DB에 먼저 적재를 진행했고, 이벤트 발행 서버에서 일정 주기마다 스케줄링을 통해 이벤트 탐지를 진행했습니다. 이때 DB는 팀에서 가장 숙련도가 높은 RDB를 선택했습니다.
3.5 결과
데이터의 순서를 보장할 수 있는 기반을 마련함으로써, 플랫폼의 정합성을 높일 수 있었습니다.
4. 두 번째 파이프라인 개선기
4.1 문제 상황 분석
첫 번째 파이프라인 개선은 데이터 순서 보장 문제를 해결했지만, 짧은 시간에 개선을 진행해야 했기 때문에 효율적이지 못한 부분들이 있었습니다.
스케줄링 기반 배치성 동작으로 인한 효율적이지 못한 리소스 처리
트래픽이 적은 시간에도 동일한 로직이 주기적으로 수행되어 불필요한 리소스 비용이 발생했습니다. 고객사의 특성상 주말보다는 평일, 밤보다는 낮과 같이 특정 시점에 부하가 몰리기 때문입니다. 또한, 배치성으로 로직이 수행되어 부하가 분산되기보다는 특정 시점에 집중되는 문제도 있었습니다.
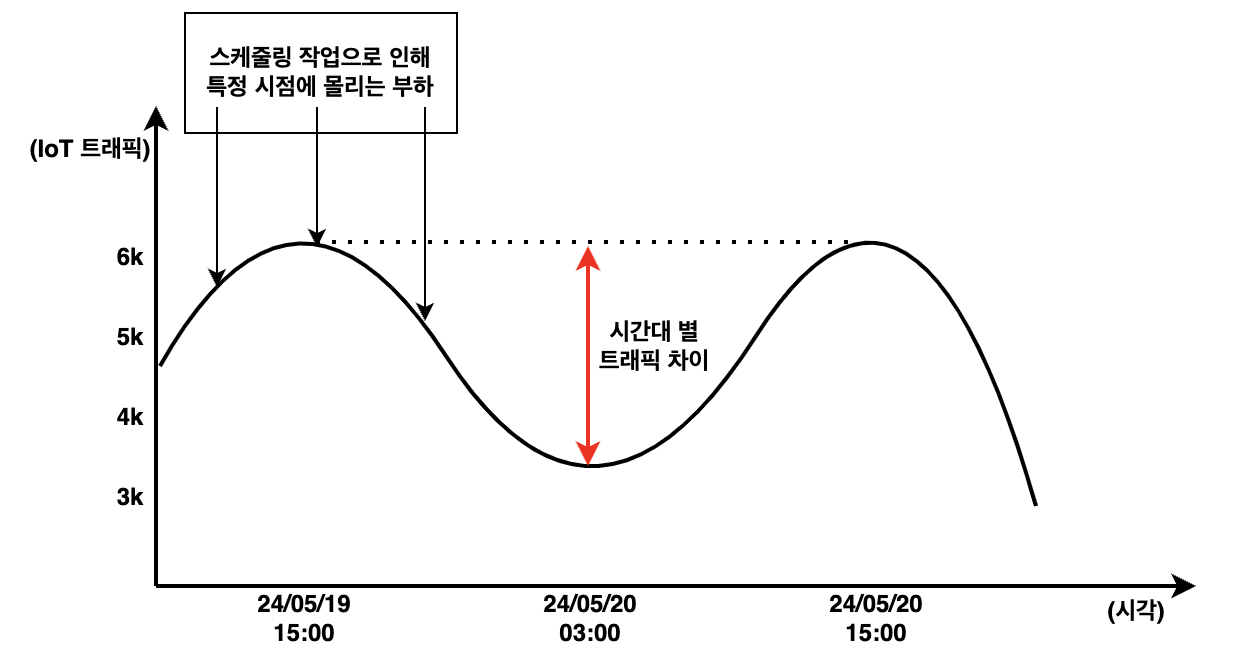
위 이미지는 실제 데이터가 아닌, 이해를 돕기 위한 예시입니다.
쏘카는 쿠버네티스를 활용하여 스케일 아웃 환경을 구성하고 있습니다. 주행이벤트 탐지 시 중복 탐지를 방지하기 위해 각 차량을 하나의 Pod에서만 처리하도록 Lock을 사용했습니다. 그러나 특정 서버에서 먼저 선점하는 차량이 많은 경우, 효율적인 부하 분산이 이루어지지 않았습니다.
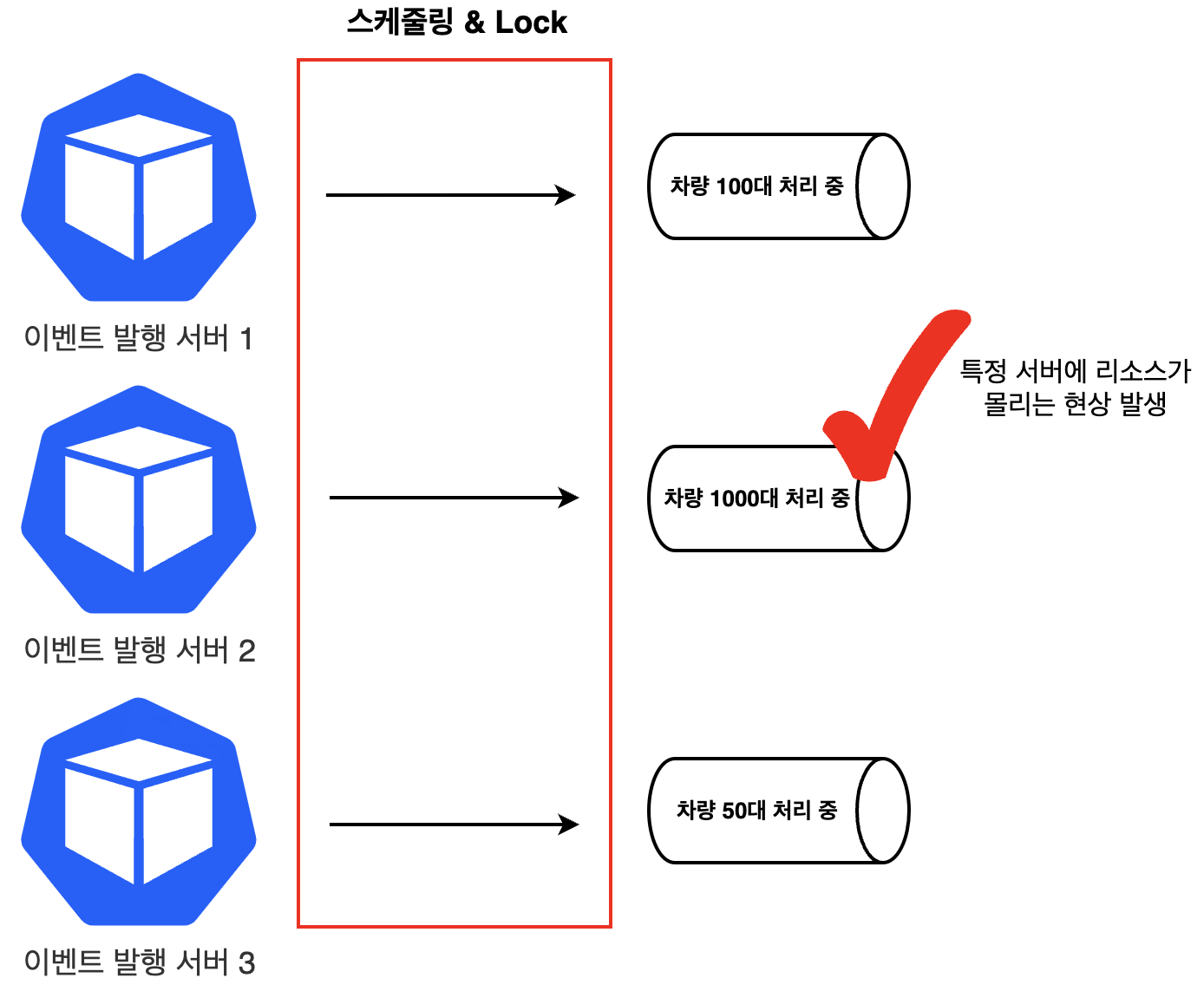
위 이미지는 실제 데이터가 아닌, 이해를 돕기 위한 예시입니다.
실시간으로 들어오는 대량의 데이터에 적합하지 못한 데이터 소스
IoT 데이터를 적재하기 위해 사용된 RDB는 비동기 처리에 적합하지 않았습니다. 또한, 차량 수가 지속적으로 증가할 예정이기에 스케일 아웃이 쉽고 관리가 편해야 했지만, 이러한 요구를 충족하지 못했습니다.
MSA 환경에서 발생할 수 있는 데이터 유실 관리
주행 이벤트 파이프라인은 API 통신을 기반으로 한 MSA 환경입니다. MSA 환경에서는 서버 간 트랜잭션 관리가 중요합니다. 연속성이 보장되어야 하는 파이프라인에서는 배포나 장애로 인해 특정 서버가 정상적으로 동작하지 못할 경우에 대한 처리가 필요합니다. 이를 위해 데이터의 순서를 보장하고 연속성을 유지할 수 있는 방안을 추가로 고려 해야했습니다.
4.2 개선하고자 하는 사항들
효율적인 리소스 분배를 통한 안정적인 플랫폼 구성
스케줄링 기반 배치성 작업으로 인해 특정 시점에 서버에 부하가 몰리거나 리소스가 낭비되는 문제가 있었습니다. 이러한 부분을 최소화 해야합니다.
실시간으로 들어오는 대량의 데이터 처리량 증가
시계열 데이터를 비동기로 빠르게 처리할 수 있는 구조로 개선해서 트래픽이 증가해도 안정적으로 서비스가 운영되도록 해야 합니다.
멱등성 있는 시스템을 구성하기 위한 노력
장애로 인한 데이터 중복이나 누락을 처리하는 정책을 수립하여 플랫폼의 정합성을 보장해야 합니다.
4.3 개선하기
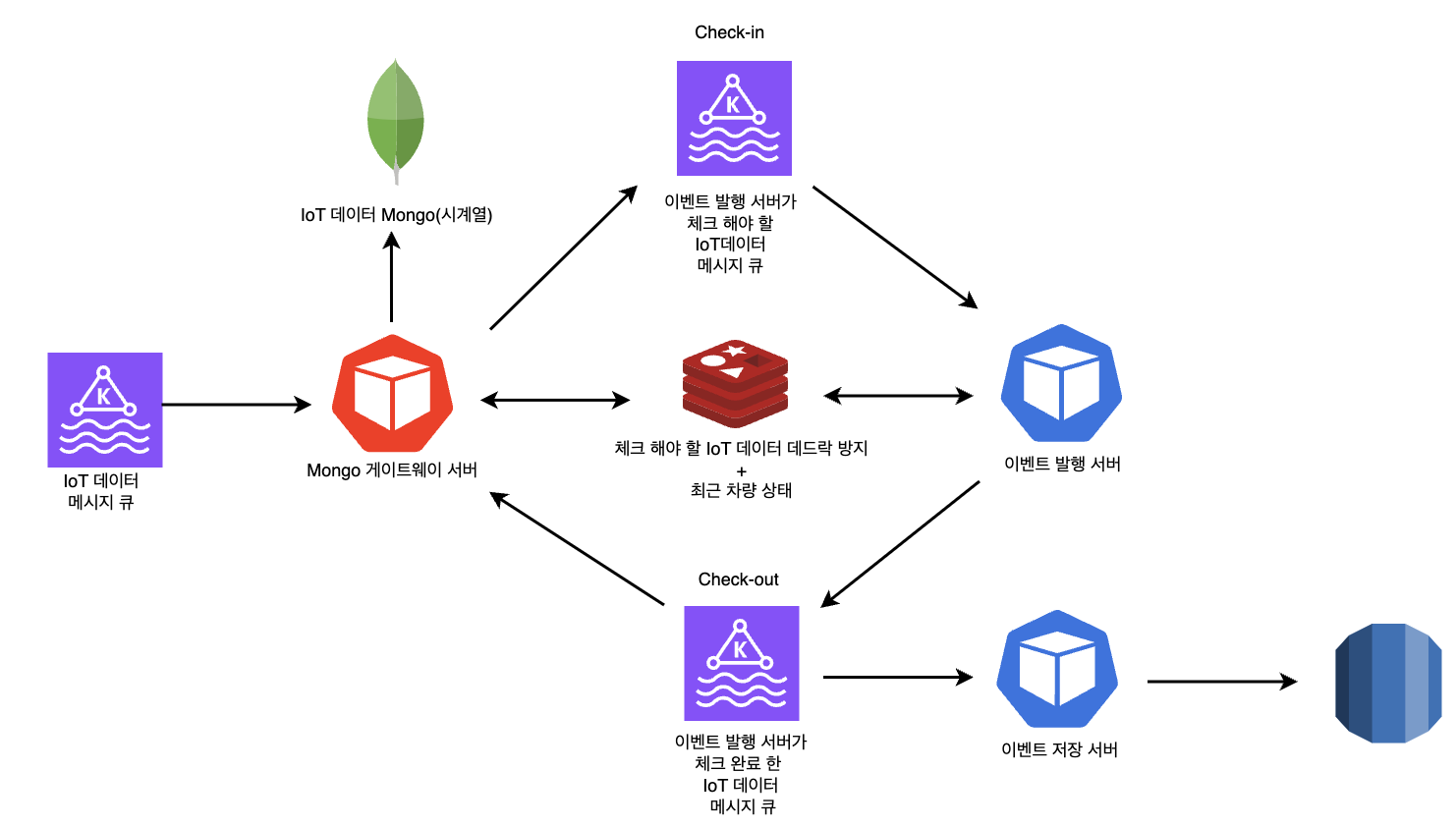
기존의 RDB에서 NoSQL로, 스케줄링 기반에서 Kafka를 활용한 이벤트 기반 파이프라인으로 변경했습니다.
-
Kafka를 선택한 이유
IoT 단말기로부터 올라오는 대량의 데이터를 안정적이고 높은 처리량으로 처리 할 수 있다고 판단했습니다.
또한, MSA 환경에서 API로 강결합된 시스템은 문제 발생 시 연속성을 보장하기 어려웠는데, 메시지 큐 기반으로 변경함으로써 배포나 장애로 인한 특정 서버의 일시적인 중단에 유연하게 대처할 수 있다고 판단했습니다.
-
NoSQL을 선택한 이유
대량의 데이터를 비동기로 처리하여 플랫폼 전반적인 처리량을 높이고자 했고, RDB 대비 효과적인 스케일 아웃의 이점이 있었습니다.
기존에 주행 이벤트를 탐지하고 발행하기 위해 스케줄링과 API로 통신하던 방식을 Kafka 기반의 이벤트 방식으로 변경함으로써 배치성 로직을 제거했습니다. 또한, 전반적으로 동기로 구성되었던 파이프라인에 비동기 드라이버가 지원되는 NoSQL을 도입해서 비동기 구간을 확장했습니다.
실시간으로 차량의 데이터가 주기적으로 들어오는 구조이기 때문에 원천 데이터뿐만 아니라 이벤트 탐지 과정에서도 데이터 순서가 보장되는 것이 중요했습니다.
이를 위해 분산된 파이프라인에 Check-In & Check-Out 개념을 도입하여, 차량별로 한 번에 하나의 Chunk만 순서대로 처리하도록 보장했습니다.
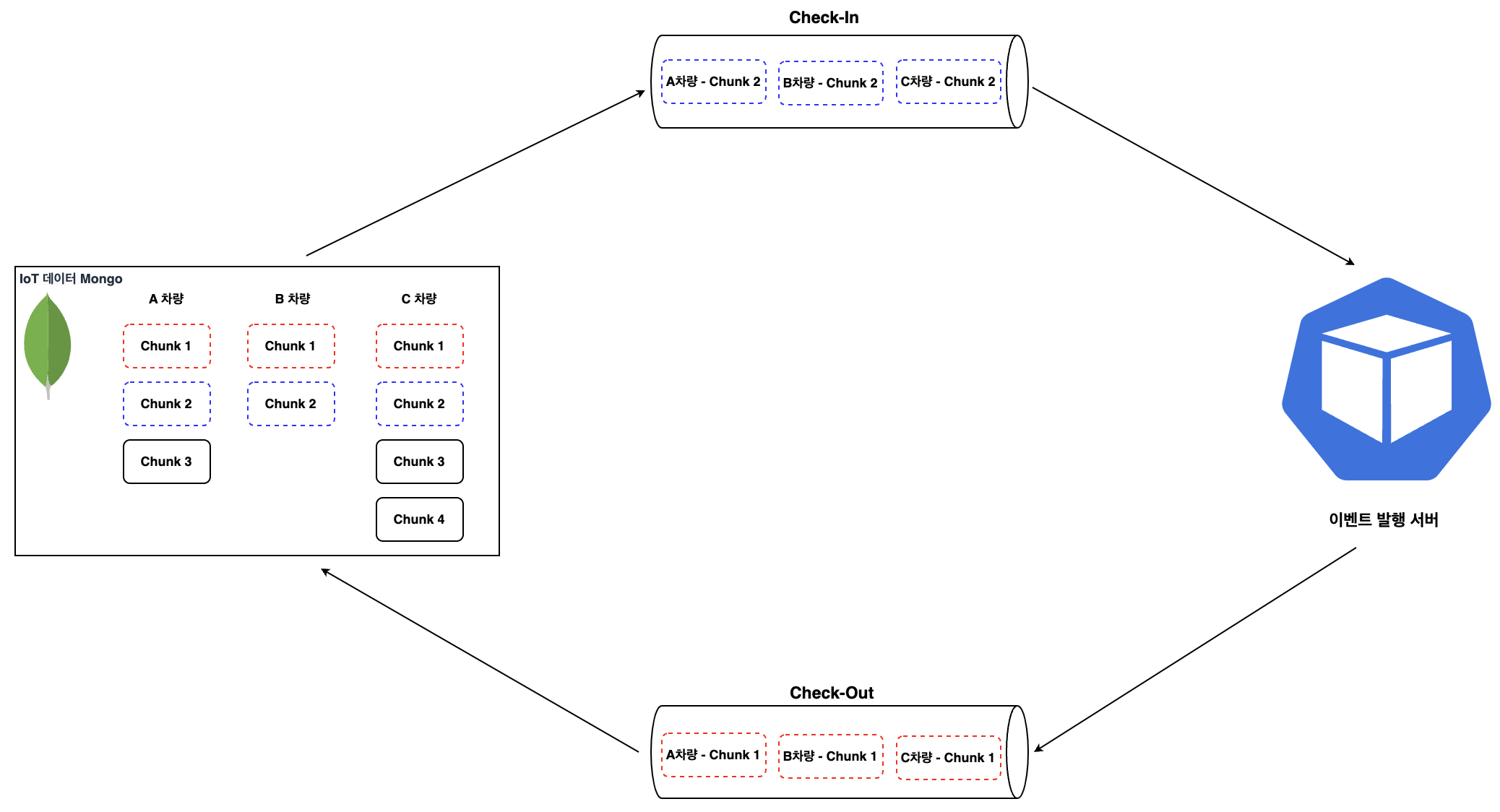
Check-In & Check-Out의 무한 대기 상태(DeadLock)를 방지하기 위한 Check-In Expire 정책과 어플리케이션의 멱등성 있는 설계를 통해 주행이벤트 라이프사이클(시계열 데이터 적재 부터 주행 이벤트 발행 까지)은 엄격하게 트랜잭션이 관리 될수 있는 아키텍처로 설계 되었습니다.
이를 통해 이벤트 순서를 보장하고, 파이프라인이 일시적으로 중단되더라도 빠르게 회복할 수 있는 환경을 구축했습니다.
또한, NoSQL에 대량으로 쌓이는 시계열 데이터의 볼륨이 성능에 주요한 영향을 미치기 때문에 관리방안을 논의했고, 원천 데이터를 이미 백업해두고 있는 환경이였기 때문에 추가적인 보관 없이 TTL 인덱스를 활용해 일정 시간이 지나면 데이터를 삭제하는 방식으로 관리했습니다.
4.4 정합성 확보하기
이러한 과정을 통해 새로운 파이프라인으로 전반적인 개선이 일어난만큼 기존 파이프라인과 비교했을때 정상적으로 동작하는지 확인하는 것이 필요했습니다. 이를 위해 논리적으로 정의된 개연성을 바탕으로 실차 테스트(실제 차량을 운행하며 수집한 데이터를 활용한 시뮬레이션 테스트)를 병행하며, 기존 파이프라인을 상회하는 정합성을 확보했습니다.
이벤트별 정합성 판단 방식
이벤트의 정합성을 확인 하기 위해 발행된 전체(차량 기준 전체) 이벤트를 순회하며, 선행 이벤트를 기준으로 후행 이벤트가 적절히 발행 되었는지 확인함으로써 정합성을 판단합니다.
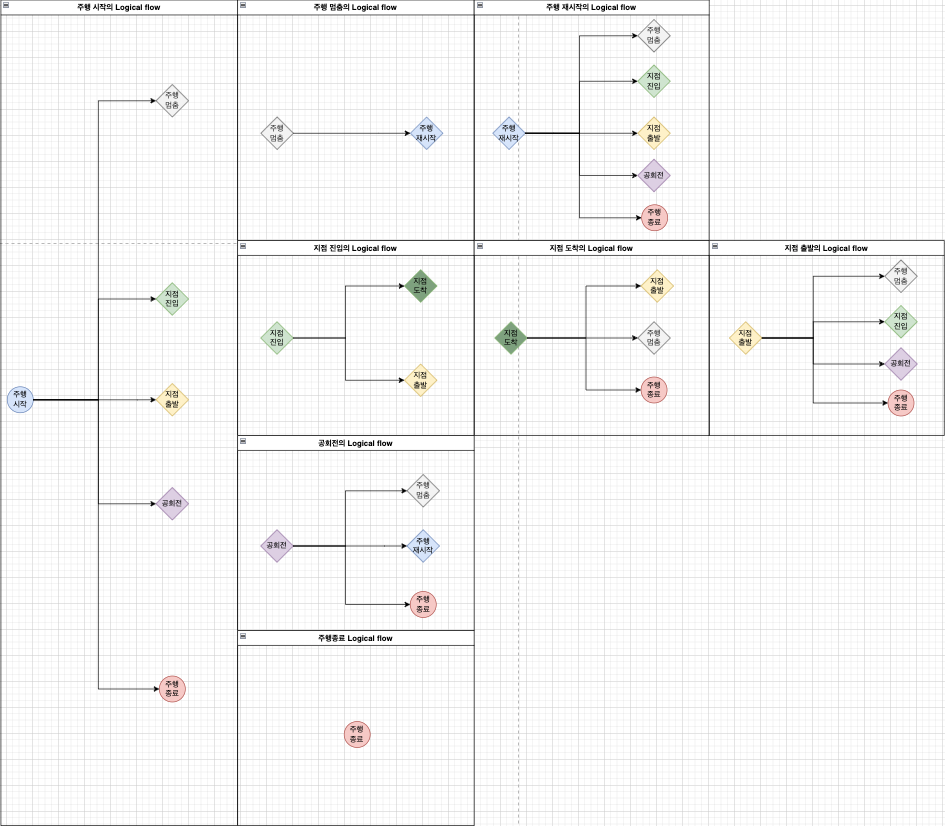
특정 이벤트가 발행될 경우 후행으로 발행될 수 있는 이벤트들의 조합
4.5 결과
스케줄링과 같은 짧은 배치성 작업을 제거하고 실시간 이벤트 기반의 파이프라인으로 전환함으로써, 특정 시간대에 리소스 부하가 집중되는 작업을 최소화하고 서버 간 역할을 명확하게 분리하여 이슈 발생 시 대응이 빨라질 수 있는 환경이 되었습니다.
또한, 이벤트를 활용하여 알림 서버와 같은 다른 서비스로의 확장 구조를 넓혔고, 단순히 어플리케이션의 스케일 아웃 뿐만 아니라 NoSQL의 장점을 활용하여 데이터 스토리지의 스케일 아웃도 용이하게 변경함으로써 대량의 데이터에 대한 플랫폼 대응력이 높아졌습니다.
5. 회고
주행이벤트 파이프라인은 이벤트의 순서를 보장하고 대량의 데이터를 처리하는 것이 중요했습니다. 하지만 초기에는 이러한 부분이 보장되지 않아서 두 차례에 걸쳐 파이프라인을 교체했습니다.
이벤트의 순서를 보장하고, 배치성 동기 시스템을 실시간 이벤트 기반의 비동기 시스템으로 변경하는 과정을 통해 필요한 기술을 정의했고, 파이프라인에 적합함을 증명했습니다.
이 경험을 통해 대량의 데이터를 다루는 역량을 쌓을 수 있었고, 앞으로 더 어려운 문제를 해결하리라 기대합니다.