 삐약
삐약 루디
루디1. 들어가며
안녕하세요. 쏘카 데이터엔지니어링팀 삐약, 루디입니다.
내용을 시작하기에 앞서, 저희 팀의 업무와 역할에 대해 간략히 소개해 드리겠습니다.
데이터엔지니어링팀은 신뢰할 수 있는 데이터를 쏘카 구성원들이 안정적으로 활용할 수 있도록 기반을 마련하고, 이를 실제 비즈니스에 적용할 수 있는 서비스를 개발하며 환경을 구축하고 있습니다. 데이터 마트 관리, 데이터 인프라 구축, 그리고 데이터 제품(Data as a Product) 개발 등 폭넓은 업무를 수행하고 있습니다.
특히 주요 업무로는 배치 및 실시간 스트리밍 파이프라인을 설계하고 개발하여, 쏘카의 모든 서비스에서 발생하는 데이터를 비즈니스 분석에 효과적으로 활용할 수 있도록 지원하는 역할을 하고 있습니다.
이번 글에서는 저희 팀이 관리 및 운영하는 데이터 파이프라인 중, 비즈니스 의사 결정 시 지표로 사용되는 서버 로그를 데이터 웨어하우스로 사용하고 있는 BigQuery에 적재하는 로그 파이프라인 개선 과정을 소개드리고자 합니다
개선을 하게 된 가장 주요 이유 중 하나는 데이터 스키마 변경으로 인해 겪는 어려움 이었습니다. 이를 해결하기 위해 데이터 컨트랙트를 도입하게 되었고, 이 과정에서 얻은 경험을 나누고자 합니다. 이번 시리즈는 비슷한 문제를 겪고 계신 분들께 도움이 되길 바랍니다.
이 글이 유용한 대상
- 데이터 파이프라인을 구축하거나 개선하고자 하는 데이터 엔지니어
- 데이터 컨트랙트를 도입하려는 개발자
- 데이터 엔지니어의 업무에 대해 궁금한 분
2. 기존 로그 파이프라인 현황
기존 파이프라인을 설명하기에 앞서, 아키텍처의 문제를 더 명확히 이해하기 위해 원본 데이터의 구조와 요구사항을 먼저 살펴보겠습니다.
2-1. 원본 데이터 구조 및 요구사항
원본 데이터에서 하나의 로그 파일은 다음과 같은 형식으로 제공됩니다.
...
...
...
{"type": "TYPE101", "logDetails": {"timeMs": 1704067200000, "field1": "$TrIN@", "field2": "1234-5678", ...}}
{"type": "TYPE102", "logDetails": {"timeMs": 1704070800000, "field3": {"key1": "value1"}, "field4": "abcd-efgh-ijkl", ...}}
{"type": "TYPE103", "logDetails": {"timeMs": 1704070800000, "field5": [0, 1], "field6": "{'key2':{'key3':'value2'}}", ...}}
...
...
...
하나의 파일에는 여러 종류의 로그 데이터가 섞여 있으며, 모든 데이터에는 로그의 종류(type)와 생성 시간(timeMs) 같은 공통 필드가 포함되어 있습니다. 또한 각 로그 타입마다 고유한 필드도 존재합니다.
파이프라인의 요구사항은 아래와 같습니다.
- BigQuery 테이블화: 로그 데이터는 타입별로 구분된 BigQuery 테이블에 저장되어야 하며, 이를 통해 조회 및 분석이 가능해야 합니다.
- 특정 타입 데이터 적재: 요청한 타입의 데이터만 BigQuery에 적재해야합니다.
- 배치성 처리: 데이터 처리와 적재는 최소 2시간 이내에 이루어져야 하며, 가능하면 더 빠르게 처리되어야 합니다.
이러한 데이터 구조와 요구사항을 바탕으로, 기존 파이프라인이 어떻게 구성되어 있는지 살펴보겠습니다.
2-2. 기존 파이프라인 아키텍처
우선 어떻게 데이터 파이프라인을 개선할 것인가에 대한 질문에 대한 답을 하기에 앞서 기존 아키텍처에 대하여 이해하고 어떤 부분에서의 문제가 발생하고 있는지의 파악이 필요합니다.
기존 파이프라인 설계 당시의 상황과 고려 사항을 살펴보면, 이미 Amazon Kinesis Data Stream(KDS)과 Firehose를 통해 AWS S3에 데이터가 적재되고 있는 환경이었습니다. 더불어 로그 데이터는 주로 분석 용도로 활용될 예정이었기에 실시간성에 대한 요구사항은 크지 않았습니다. 이러한 배경에서 기존 인프라를 최대한 활용하면서도 효율적인 데이터 처리가 가능한 구조를 고민하였고, 다음과 같은 요구사항을 결정하였습니다.
- S3에 저장된 데이터를 시작점으로 하는 파이프라인 구성
- 배치 처리에 특화된 Airflow를 활용한 데이터 분류 및 적재
- GCP의 GCS를 중간 저장소로 활용하여 타입별 데이터 분류
- 최종적으로 BigQuery 테이블 형태로 데이터 구조화
아래는 기존 파이프라인 구조입니다.

위 요구사항에 따라 구축한 기존 로그 수집 파이프라인의 주요 흐름은 다음과 같습니다.
- 로그 생성 및 KDS로 로그 데이터를 전송합니다.
- 서버에서 생성된 로그는 실시간으로 KDS에 프로듀스됩니다.
- Firehose를 통한 데이터를 저장합니다.
- KDS의 데이터를 Firehose가 읽어 Amazon S3 버킷에 적재 일자 기준 파티셔닝 하여 저장합니다.
- Airflow를 통한 로그 타입 분류 및 BigQuery에 데이터를 적재합니다.
- 분류기: Google Cloud의 GKE 클러스터에서 실행 중인 Airflow가 주기적으로 S3 버킷의 데이터를 읽어 type별로 분류한 후, Google Cloud Storage(GCS)에 timeMs 값에 따라 일자별로 파티셔닝 하여 저장합니다.
- 적재기: 분류기에서 타입, 시간 별 분류 이후 요청한 로그 타입에 대해서 GCS의 데이터를 BigQuery 테이블에 적재합니다.
이러한 파이프라인 구조는 안정적으로 운영되어 왔으나, 시간이 지남에 따라 여러 가지 한계점과 문제들이 드러나기 시작했습니다. 아래에서 이러한 문제점들을 자세히 살펴보겠습니다.
2-3. 기존 로그 파이프라인 문제점
분류 작업의 비효율성
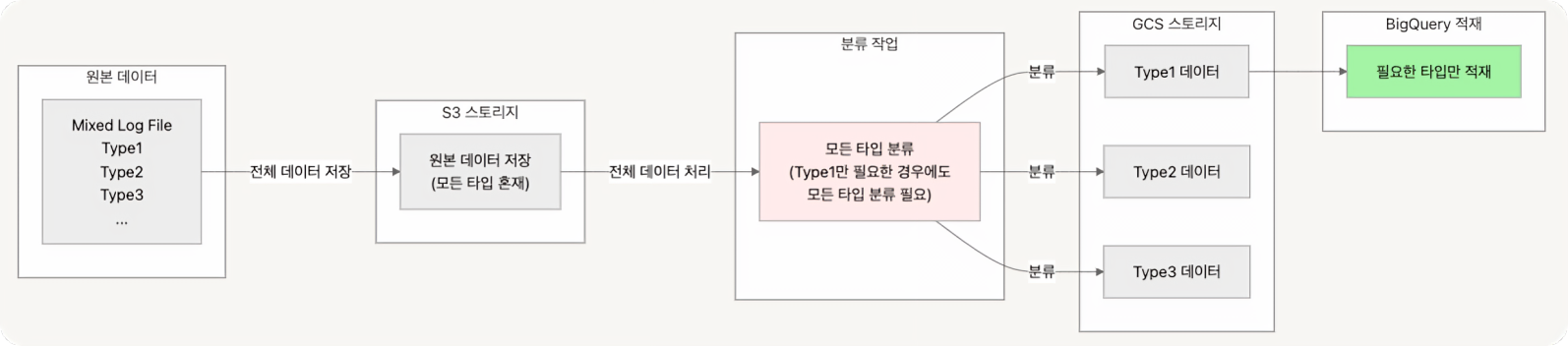
서버 로그는 하나의 파일에 다양한 유형의 데이터를 포함하고 있었고, 이를 적재하기 위해 반드시 분류 작업을 거쳐야 했습니다. S3에 적재된 분류되지 않은 파일을 분류기를 통해 유형별로 분류한 후 GCS에 적재하는 과정에서 많은 시간이 소요되었습니다.
특히, 분류 작업은 모든 유형의 데이터를 처리하고 적재 단계에서만 실제 필요한 데이터가 BigQuery에 적재되었습니다. 하나의 파일에 모든 로그를 처리하고 있는 상황에서 분류기에서 특정 type만 선택적으로 적재하기 어려웠기에 모든 유형의 로그를 분류하다 보니 S3와 GCS에 분류 전후의 중복된 데이터가 저장되는 비효율적인 문제가 발생했습니다.
또한 분류 작업에서 문제가 발생할 경우 모든 타입의 서버 로그 데이터를 적재할 수 없게 되어 단일 장애 지점이 발생하였습니다.
데이터 신선도 부족
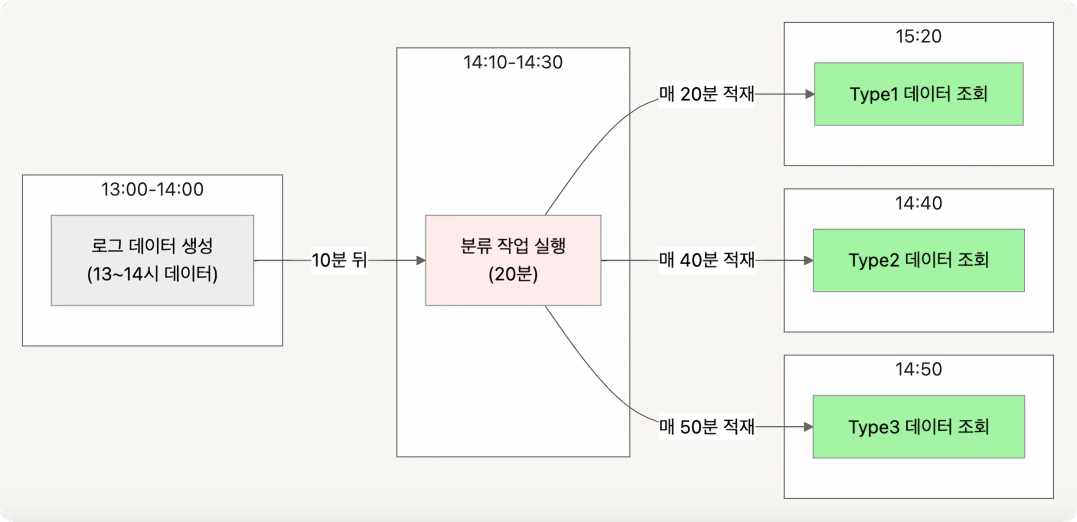
데이터의 신선도가 부족하다는 점도 개선이 필요한 부분이었습니다. 즉각적인 비즈니스 전략 수립을 위해 실시간성 로그 데이터의 수요가 증가함에도 불구하고 현재 파이프라인은 Airflow 배치 스케줄링 방식을 사용하고 있었기 때문에 실시간 데이터가 필요한 상황에서 적절히 대응하지 못했습니다. 이에 따라 데이터 사용자가 즉각적으로 서버 로그 데이터를 확인하기 어려운 비효율적인 상황이 자주 발생했습니다.
스키마 변경과 관리 부재
서버 로그의 스키마 변경에 대한 이력 관리 체계가 부재했던 점은 주요한 문제 중 하나였습니다. 기존에는 데이터 생산자와 소비자가 공통으로 사용하는 Schema Registry와 같은 스키마 저장소가 없었기 때문에, 생산자가 스키마를 변경하고 소비자가 이를 사용하는 과정에서 문제가 발생하곤 했습니다. 특히, 스키마가 혼재된 데이터를 처리해야 할 경우 임시 적재기를 사용하는 비효율적인 방식을 사용하고 BigQuery에 수기로 스키마를 업데이트 하는 등 유지보수의 큰 오버헤드가 팀 내 병목을 발생시켰습니다. 이러한 문제들은 데이터의 안정성과 활용도를 저하시켰고, 운영 부담을 가중시키는 요인이 되었습니다.
수기로 관리되던 기존 로그 BigQuery 스키마
로그 BigQuery 스키마 예시
2-4. 해결 방안 모색
위에서 언급한 주요 문제점들은 서로 긴밀하게 연결되어 있었습니다. 분류 작업의 비효율성은 데이터 신선도에 직접적인 영향을 미쳤고, 스키마 관리 체계의 부재는 분류 작업의 복잡성을 더욱 가중시켰습니다. 이러한 상황을 개선하기 위해 저희 팀은 파이프라인의 전면적인 개선이 필요하다고 판단했습니다.
따라서 기존 파이프라인의 문제들을 해결하기 위해 아래와 같은 해결방안을 세웠습니다.
| 문제점 | 해결 방안 |
|---|---|
| 분류 작업의 비효율성 | S3와 GCS 중 단일 원본 데이터 저장소를 설정하고, 특정 유형의 로그만 적재 가능하도록 개선 |
| 데이터 신선도의 부족 | 기존 배치 파이프라인에서 실시간 처리 가능한 스트리밍 파이프라인으로 전환 |
| 스키마 변경과 관리의 부재 | 로그 데이터 스키마를 통합 관리할 수 있는 체계를 구축 |
3. 파이프라인 문제 해결 방안
3-1. 분류 작업 효율화
기존의 KDS를 Managed Streaming for Apache Kafka(MSK)로 전환하고, 커스텀 Kafka Consumer를 도입하여 실시간 데이터 분류 시스템을 구축하고자 하였습니다. MSK를 선택한 주요 이유는 Schema Registry를 통해 메시지 스키마를 체계적으로 저장하고 관리할 수 있다는 점이었습니다. Kafka Consumer를 통해 특정 타입의 로그만 선별적으로 분류 및 적재하고자 하였으며, 분류한 데이터를 GCS에 직접 적재하도록 설계하여 기존에 발생하였던 S3와 GCS 간의 중복 저장 문제를 해소하고자 하였습니다.
더불어 Custom Consumer에서의 다양한 사용자 정의 설정을 지원하기에 분류 작업의 유연성을 높이고, 체계적인 모니터링 시스템을 구축하여 운영 안정성을 강화하고자 하였습니다.
3-2. 데이터 신선도 개선
실시간 스트리밍 파이프라인을 구축하여 분류 작업의 효율성을 높임과 동시에 실시간 데이터 처리가 가능하게 하여 데이터 신선도를 개선하고자 하였습니다. Kafka Consumer가 수집된 데이터를 실시간으로 처리하고 GCS에 즉시 적재하며, BigQuery 외부 테이블과 연동하여 사용자들이 필요한 시점에 즉각적으로 데이터를 활용할 수 있는 환경을 제공하고자 하였습니다. 이를 통해 데이터의 생산부터 소비까지의 시간 간격을 최소화하여 데이터의 실시간성을 확보하고자 하였습니다.
3-3. 스키마 통합 관리
데이터 컨트랙트를 도입하여 파이프라인 전반의 스키마 변경 관리를 체계화하고자 하였습니다. Kafka Schema Registry를 활용해 검증된 스키마만 데이터 생산과 소비 과정에서 사용되도록 함으로써 데이터 품질과 안정성을 확보하고자 하였습니다. 또한, 스키마를 중앙 집중적으로 관리하고 모든 스키마 변경 시 필수적으로 리뷰 프로세스를 거치도록 하여 변경으로 인한 잠재적 문제를 사전에 방지할 수 있는 구조를 구상하고자 하였습니다.

데이터 컨트랙트는 데이터 생성자와 소비자 간의 명시적인 합의로, 데이터의 형식과 구조에 대한 명확한 규칙을 정의하여, 데이터 파이프라인 전반의 품질, 신뢰성, 일관성을 보장합니다. 데이터 컨트랙트는 다음과 같은 세 가지 핵심 요소로 구성됩니다.
- 생산자와 소비자 간의 문화적 합의
- 코드/템플릿을 통한 명시적인 스키마 정의 (Protocol Buffer, Schema Registry)
- Producer, Consumer를 포함한 파이프라인 전반에서의 실제 적용
위 해결방안을 이루기 위해 최종적으로 아래와 같은 기술 스택을 선택하였습니다. 각 기술에 대한 자세한 내용 및 신규 아키텍처에 대해서는 아래에서 다룰 예정입니다.
| 기존 | 변경 | |
|---|---|---|
| 분산 메시지 플랫폼 | Kinesis Data Stream (KDS) | Managed Streaming for Apache Kafka (MSK) |
| 메시지 소비 | Firehose | Kafka Consumer |
| 데이터 가공 | Airflow | Kafka Consumer |
| 스키마 통합 관리 | X | 1차: Protobuf 2차: Schema Registry |
4. 새로운 아키텍처
4-1. 새로운 아키텍처 개요
지금까지 기존 파이프라인의 문제점과 각 문제를 해결하기 위해 했던 고민 과정에 관해 설명해드렸습니다. 이를 기반으로, 기존의 데이터 흐름에서 발생하던 비효율성과 복잡성을 해결하기 위해 새롭게 만든 아키텍처에 대한 소개를 이어가보겠습니다.
가장 큰 변화는 역시 데이터 생산자/소비자가 같은 단일 데이터 소스(Single Source of Truth, SSoT)로 부터 데이터를 생산 및 소비한다는 점입니다. 이를 통해 데이터의 일관성을 유지하고, 한층 더 견고한 파이프라인을 유지할 수 있게 됩니다. 또한 기존에 오래 걸리던 분류 작업을 Consumer 단에서 바로 해결이 가능하니 배치 파이프라인을 유지할 필요가 없어졌고 그 결과 데이터 유저는 준실시간으로 데이터를 사용할 수 있게 되었습니다.
아래에서 아키텍처 다이어그램과 함께 각 컴포넌트에 대한 설명과 데이터 흐름에 대한 더 자세한 설명을 이어가겠습니다.
4-2. 주요 컴포넌트
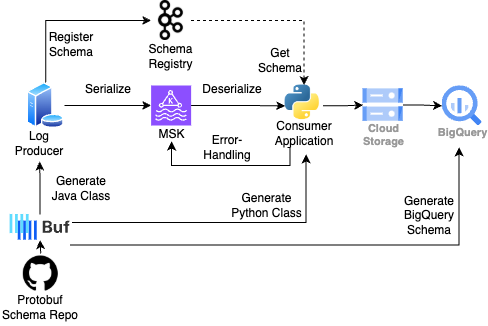
Protobuf
Protobuf는 Google에서 개발한 데이터 직렬화 포맷으로, 구조화된 데이터의 효율적이고 빠른 처리를 지원합니다. JSON이나 XML보다 데이터 크기가 작고 처리 속도가 빨라, 서비스 간 데이터 교환에 적합합니다. 데이터 생산 및 소비 과정에서 주요 스키마 포맷으로 활용되며, 파이프라인 전반에서 일관된 데이터 처리를 가능하게 합니다.
Buf
Buf는 Protobuf 기반의 데이터 스키마를 중앙에서 효율적으로 관리하고 최적화하는 스키마 관리 및 검증 도구입니다. Protobuf 스키마는 Protobuf 통합 레포지토리에 저장되며, Buf를 활용하여 스키마 린팅, 포맷팅, 코드 생성, 호환성 검증 등의 작업을 자동화하여 일관성과 품질을 보장합니다. 또한, 파이썬 및 자바 클래스 컴파일, BigQuery 스키마 생성과 같은 다양한 플러그인을 지원하여 다양한 언어 및 서비스 간 통합 스키마 관리를 가능하게 합니다. Buf 에 대한 더 자세한 내용은 공식문서 링크를 참고 바랍니다.
MSK (Managed Streaming for Apache Kafka)
Kafka는 분산 스트리밍 플랫폼으로, 실시간 데이터를 확장성 있게 처리할 수 있습니다. AWS 의 MSK 는 Kafka를 완전 관리형 서비스로 제공하여 운영 부담을 크게 줄여줍니다.
MSK는 쏘카 내부적으로 많은 팀에서 안정적으로 사용되고 있는 서비스로, 새로운 파이프라인으로 전환 시 부담이 적었습니다. 또한, 오픈 소스 Kafka 라이브러리와 Schema Registry와의 높은 호환성 덕분에 데이터 처리 파이프라인을 유연하게 설계할 수 있었습니다.
Kafka Schema Registry
Schema Registry는 Kafka와 통합되어 데이터를 효율적으로 관리하는 중앙화된 스키마 관리 서비스입니다. Kafka에서 전송되는 데이터의 구조를 정의하고, 데이터 생산자와 소비자 간 스키마 일관성을 보장합니다. 대표적으로 Avro, Json, Protobuf 세 가지 직렬화 포맷을 지원하는데 데이터의 직렬화 및 역직렬화 시 스키마 호환성을 검증하며, 데이터 스키마 변경으로 인한 문제를 사전에 방지하는데 도움을 줍니다.
Consumer (커스텀 파이썬 애플리케이션)
일반적으로 Kafka 의 토픽에 저장된 데이터를 읽어와 처리하는 애플리케이션을 Consumer 라고 합니다. MSK 의 Consumer로 많이 쓰이는 Firehose, Flink, Kafka-connect 등이 있지만 데이터 분류와 필드/타입 파티셔닝과 같은 맞춤형 데이터 처리 요구사항을 충족하기 위해 파이썬 Confluent kafka 라이브러리로 Consumer를 자체 개발하였습니다.
GCS
GCS는 Consumer가 MSK에서 수집한 메시지를 안정적으로 저장하는 원천 데이터 저장소입니다. 또한, BigQuery 외부 테이블의 소스(Source) 역할을 수행하며, 이를 통해 유저들에게 실시간에 가까운 데이터 접근을 제공합니다. GCS를 활용함으로써 데이터의 보존, 관리, 및 확장성을 효과적으로 보장할 수 있습니다.
BigQuery
BigQuery는 Google Cloud에서 제공하는 완전 관리형 데이터 웨어하우스로, 쏘카 전사적으로 활용되는 주요 분석 플랫폼입니다. BigQuery에서 제공하는 뷰 테이블(View Table) 기능을 통해 이용자들에게 데이터를 제공하게 됩니다. 해당 뷰 테이블은 GCS 외부 테이블과 BigQuery 내부 테이블을 결합하여 구축되며, 이를 통해 사용자는 데이터의 신선도와 안정성을 동시에 확보할 수 있습니다.
4-3. 데이터 처리 흐름
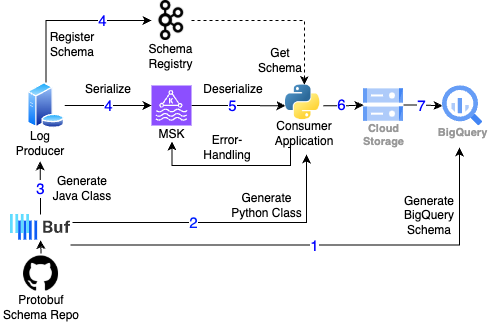
기본적으로 로그가 발생하면 쏘카 내부 서버에서 MSK로 로그데이터를 보내게 되고 최종적으로 BigQuery로 적재되는 구조입니다. 여기서 중요한 점은 각각의 서비스에서 데이터를 처리할 때 같은 소스를 바라봄으로써 데이터 일관성을 유지한다는 점입니다.
스키마 업데이트와 통합 관리 (0)
스키마 업데이트는 데이터 생산자와 소비자 모두 PR 리뷰 과정을 거칩니다. 이 과정에서 Github Actions 를 통해 기본적인 린팅, 포맷팅, 호환성검사가 진행되며 문제가 있을 시 조기에 발견이 가능합니다. 이후 변경 사항이 문제를 일으키지 않는지 개발 환경에서 테스트를 진행하게 됩니다.
BigQuery 스키마 생성 (1)
Buf 에서 제공하는 플러그인 (googlecloudplatform/bq-schema)을 활용하여 BigQuery 테이블 스키마를 손쉽게 생성할 수 있습니다. BigQuery는 업데이트된 스키마를 기반으로 기존 테이블 스키마를 수정(Alter Column)합니다. 여기서 업데이트된 BigQuery 스키마가 기존 BigQuery 스키마와 호환 되지 않는다면, 다시 (0)으로 돌아가 스키마 업데이트에 대해 다시 논의합니다.
파이썬 클래스 생성 및 배포 (2)
Buf 에서 제공하는 파이썬 클래스 생성 플러그인 (protocolbuffers/python)을 사용하여 스키마 변경 시 최신 파이썬 클래스를 생성합니다. 이후 새로운 버전의 파이썬 클래스를 포함한 Consumer Pod을 재배포합니다.
자바 클래스 생성 및 배포 (3)
자바 스프링으로 구현된 Producer 서버는 Gradle 플러그인을 활용하여, Protobuf 통합 레포지토리의 스키마를 자바 클래스로 컴파일하여 사용합니다. Protobuf 스키마 업데이트되어 버전이 변경되면, 해당 버전에 맞춰 Producer 를 재배포합니다.
데이터 생성 (4)
서버(Producer)는 로그 데이터를 (Confluent Kafka 라이브러리의 ProtobufSerializer를 통해 메세지를 Protobuf 포맷으로 직렬화한 뒤 MSK에 전송하며, 동시에 Schema Registry에 스키마를 등록합니다. MSK에 데이터를 보낼 때, auto_register_schema 인자에 True를 주게 되면, 자동으로 Kafka Schema Registry에 스키마를 등록할 수 있습니다. (이 부분은 선택사항이며 스키마 배포 전략을 어떻게 가져가냐에 따라 달라질 수 있습니다)
데이터 소비 (5)
Consumer 애플리케이션은 Confluent Kafka 라이브러리의 ProtobufDeserializer를 활용하여 MSK로부터 데이터를 역직렬화하여 메시지를 읽어옵니다. 수신된 메시지는 애플리케이션의 비즈니스 로직에 따라 필요한 형태로 분류 및 가공됩니다.
데이터 처리 중 문제가 있는 경우, 해당 데이터를 MSK의 DLQ로 전송하고 에러 메시지와 함께 나중에 재처리합니다.
데이터 GCS 적재 (6)
Consumer 애플리케이션이 데이터를 필요한 형태로 분류하고 가공한 이후, 특정 기준(예: 날짜컬럼, 특정 컬럼 등)으로 파티셔닝한 후, GCS에 저장합니다.
gs://log/type=CREATE_SOCAR/ymd=2024-12-31/hour=23/uuid.json
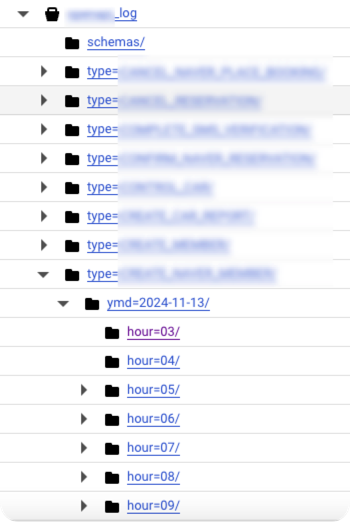
각 타입별 로그가 ymd/hour 기준으로 파티셔닝되어 적재
최종 BigQuery 데이터 적재 (7)
실시간으로 GCS에 적재된 데이터는 BigQuery External Table로 구성되며, 이는 GCS를 소스로 참조합니다. 그러나 External Table의 쿼리 성능이 상대적으로 느리기 때문에, 매일 일 배치 작업을 통해 해당 데이터를 BigQuery 내부 테이블로 적재합니다.
최종 사용자는 BigQuery External Table과 BigQuery 내부 테이블을 BigQuery View Table을 통해 데이터를 확인합니다. 이 구조를 통해 유저는 데이터를 BigQuery 에서 준실시간으로 확인할 수 있습니다.
5. 기술스택 선정 및 구현 과정에서의 고민
위에서 전반적인 아키텍처 내용과 구현의 결과물을 소개해 드렸습니다. 아래에서는 이를 구현하는 과정에서 팀내에서 겪었던 기술스택 선정에 대한 고민과 예상치 못했던 시행착오에 대해서 좀 더 공유해보겠습니다.
5-1. 커스텀 Consumer 를 개발하기까지
분류 작업의 효율화 및 신선도 개선을 위해 로그파일 저장소를 [S3+GCS] → [GCS] 단일 저장으로 변경하고 Airflow 스케줄링을 통한 배치작업 대신 MSK + Consumer 조합으로, 준실시간으로 분류와 적재를 동시에 할 수 있게끔 아키텍처의 변화를 주었다고 위에서 간략하게 설명드렸습니다. 아래는 Consumer 기술스택 선정 과정에 있어서 검토했던 내용을 공유해 드리겠습니다.
Firehose 를 계속해서 사용해볼까? 개선과정에서 첫번째로 결정된 사항은 Schema Registry 사용을 통한 스키마 관리였습니다. 여기서 자연스럽게 메세징 플랫폼은 KDS 대신 MSK로 정해졌습니다.
다음 단계는 메시지 소비를 위한 기술 선택이었는데, 기존에 사용하던 Firehose를 계속 사용할지, 아니면 새로운 대안을 도입할지 두 가지 선택지가 있었습니다.
Firehose는 Dynamic Partitioning 기능을 제공하여 메시지의 특정 필드를 파싱해 파티션키로 사용할 수 있습니다. 하지만 MSK를 Firehose의 소스로 선택할 경우 Dynamic Partitioning 기능을 사용할 수 없다는 제약이 있었습니다. 특히 메시지 타입별 분류가 필수적인 상황에서 이 기능의 부재는 큰 단점으로 작용했습니다.

Firehose 의 소스로 MSK 선택 시, Dynamic Partitioning 기능 사용 불가
또한, Firehose 만으로는 메시지 변환(Transformation)에 한계가 있어 메시지 변환 레이어로 AWS Lambda를 추가해야 했습니다. Firehose 가 AWS Lambda 에게 넘겨준 값(kafkaRecordValue=base64 인코딩 문자열) 을 다시 디코딩하고 Protobuf 역직렬화 하는 일련의 과정들을 포함해 운영 리소스 증가와 오버엔지니어링이라는 생각을 하였습니다.
Kafka-connect 는 어떨까?많은 기업에서 Kafka Consumer 로 Kafka-connect 를 사용합니다. 대표적으로 Confluent Kafka-connect 혹은 AWS MSK Connect 를 많이 사용합니다. MSK를 쓰다보니 같은 관리형 서비스로 MSK Connect 를 사용하려 했지만 불친절한 에러로깅으로 셋업 과정이 쉽지 않았습니다.
Kafka-connect 를 이용한 단순적재는 오픈소스로 나온 Sink Connector(S3, GCS, MySQL, …) 를 사용하면 편리합니다. Confluent 사에서 제공하는 오픈소스 플러그인(Kafka-connect-protobuf-converter 등) 을 받아서 Avro 혹은 Protobuf 메세지 등 상황에 맞게 사용할 수도 있습니다. 또한 Kafka-connect 자체적으로 SMT (Single Message Transformation) 도 지원하기에 간단한 데이터변환은 적용하기에 나쁘지 않습니다. 하지만 여러 테스트 결과 원하는 대로 메세지 파싱이 되지 않아서 결국 선택은 하지 않았습니다.
저희가 사용했던 Protobuf 스키마 파일을 예시로 보여드리면서 보다 상세한 설명을 해드리도록 하겠습니다. 기본적으로 저희가 사용하기로 결정한 로그 스키마 형태는 아래와 같습니다.
syntax = "proto3";
import CreateSocar, DeleteSocar, UpdateSocar, ...;
message Log {
Type type = 1;
google.protobuf.Timestamp timestamp = 99;
enum Type {
...
CREATE_SOCAR = 18;
DELETE_SOCAR = 19;
UPDATE_SOCAR = 20;
...
}
oneof data {
...
CreateSocar create_socar = 3;
DeleteSocar delete_socar = 4;
UpdateSocar update_socar = 5;
...
}
}
Kafka 토픽당 스키마는 1대1 대응이기에, 수백개의 로그 종류별로 토픽을 생성하여 관리하기에는 오버엔지니어링이라 판단했습니다. 우회책으로 Protobuf 의 oneof 기능을 이용해서 1개의 Protobuf 스키마로 n개의 Protobuf 스키마를 검증할 수 있게 해주었습니다. (로그타입을 유저, 운전, 예약 등 대분류로 나누어서 토픽의 개수를 최소화 할 수 있었습니다).
CreateSocar 로그를 생성하거나 DeleteSocar 로그를 생성하거나 상관없이 위 ‘Log’ Protobuf 스키마를 사용해서 로그를 생성하면 됩니다 (물론 CreateSocar 로그를 생성하려면 CreateSocar 스키마에 맞는 데이터를 만들어줘야 합니다). 위 스키마를 사용하여 CREATE_SOCAR 혹은 DELETE_SOCAR 라는 type의 로그를 생성했을 때 기대했던 로그 파일 결과물은 아래와 같습니다.
{
"type": "CREATE_SOCAR",
"timestamp": 1725428910094
"create_socar": {
...
"socar_id": "45525545",
"name": "소나타",
...
},
...
}
{
"type": "DELETE_SOCAR",
"timestamp": 1725428910095
"delete_socar": {
...
"socar_id": "45525546",
"name": "아반떼",
...
},
...
}
위와 같이 공통필드(type, timestamp) 를 제외한 각 type에 해당하는 데이터가 type 이름과 같은 필드(create_socar, delete_socar)에 들어오는 포맷을 원했습니다.
하지만 kafka-connect-protobuf-converter:7.2.2 버전의 커넥터 플러그인을 사용한 결과 아래와 같이 MSK로부터 데이터를 읽을 때, data 필드에 one of 의 값으로 주어질 수 있는 모든 필드에 대해서 불필요한 값이 생성되는 문제가 있었습니다.
{
"type": "DELETE_SOCAR",
"timestamp": 1725428910094,
"data_0": {
...
"create_socar": null,
"delete_socar": {
"socar_id": "45525546",
"name": "김쏘카",
},
"update_socar": null,
...
},
...
}
위와 같은 부분과 더불어 n개 필드를 활용한 파티션키 생성과 같은 요구사항을 별도의 Transformation 로직으로 처리하려면 Java/Kotlin 으로 구현을 해야하는데요, 팀 내 Java/Kotlin 언어에 대한 경험치가 높지 않아 개발 및 유지보수가 힘들다고 판단했습니다.
우리가 자체 Consumer를 개발하자! 다행히 Kafka 는 다양한 언어에 대한 SDK를 지원하기에 직접 파이썬 Consumer 를 만드는 것이 개발 및 유지보수를 생각하면 낫다고 판단하여 진행하게 되었습니다.
파이썬으로 kafka 메세지를 consume 하려면 보통 confluent-kafka 혹은 kafka-python 으로 많이 구현합니다. 저희는 MSK 와의 호환성과 Schema Registry 지원 기능을 고려하여 confluent-kafka 를 선택하였습니다 (kafka-python 은 Schema Registry 미지원).
다양한 상황을 고려하고자 다음과 같은 config 값을 설정할 수 있는 커스텀 Consumer 를 개발하였습니다.
- 버퍼 크기 (buffer size)
- 소비 성능과 메모리 사용량을 균형 있게 조정하기 위해 버퍼 크기를 설정할 수 있도록 구성했습니다. 이를 통해 대량의 데이터를 가지고 있는 토픽도 안정성 있게 처리할 수 있습니다.
- 예:
100이면, 버퍼에 100개의 메세지가 차면 로그 데이터를 적재
- 버퍼 간격 (buffer interval)
- 메시지를 일정 주기마다 처리할 수 있도록 버퍼 간격을 설정하였습니다. 이를 통해 지연 시간과 처리량 간의 균형을 맞출 수 있습니다.
- 예:
300이면, 300초에 한번 버퍼에 있는 로그데이터를 적재
- Dead Letter Queue (DLQ) 설정
- 오류 발생 시 메시지를 별도의 토픽(Dead Letter Queue)에 적재할 수 있도록 설정하였습니다. DLQ를 활용하여 장애 상황을 모니터링하고 빠르게 대응할 수 있습니다. 또한 범용성을 위해 AWS MSK 말고 GCP PubSub 도 인자를 받을 수 있게 기능구현을 하였습니다.
- 예: 오류(역직렬화, 파티셔닝키생성, 잘못된 적재 디렉토리 등) 가 발생하면 해당 오류를 메세지 헤더에 넣어서 DLQ로 전송
- 파티션 키 (Partition Key) 전략
- 특정 n개의 컬럼을 조합하여 Kafka 파티셔닝 키로 설정할 수 있도록 구현하였습니다. 이를 통해 원하는 방식으로 파티션키를 생성할 수 있습니다.
- 예:
type,timestamp등의 필드를 인자로 주면type=CREATE_MEMBER/ymd=2025-01-01/hour=02와 같은 파티셔닝키 생성 가능
- 적재 대상 선택 옵션
- 수집한 데이터를 어디에 적재할지 선택할 수 있도록 옵션을 제공하였습니다.
- 예: S3, GCS 등의 대상별 설정을 동적으로 적용
class MSKConsumer:
def __init__(self, config: MSKConsumerConfig, deserializer: MessageDeserializer, dlq_handler: DLQHandler):
self.aws_region = config.aws_region
self.aws_role_arn = config.aws_role_arn
self.bootstrap_servers = config.bootstrap_servers
self.topic = config.topic
self.group_id = config.group_id
self.consumer = self._get_consumer()
self.deserializer = deserializer
self.dlq_handler = dlq_handler
self.messages: list[SuccessMessage] = []
self.error_messages: list[ErrorMessage] = []
self.buffer_size = config.buffer_size
self.buffer_interval = config.buffer_interval
self.last_flush_time = time.time()
self.partition_timestamp_field = config.partition_timestamp_field
self.partition_value = config.partition_value
self.partition_field = config.partition_field
self.gcs_bucket = config.gcs_bucket
self.gcs_client = storage.Client.from_service_account_json(config.google_application_credentials)
self.bucket = self.gcs_client.bucket(self.gcs_bucket)
5-2. Protobuf 메세지 검증
공통적인 Protobuf 통합 레포지토리를 바라보고, buf 플러그인을 통해 각 서비스에 사용되는 스키마를 생성함으로써, 스키마 통합관리를 한다고 말씀드렸습니다. 아래에서는 confluent-kafka 파이썬 SDK 를 사용한 Protobuf 메세지 역직렬화 과정에서 겪었던 시행착오에 대해 공유해보도록 하겠습니다.
Deserializer 에 대해서 Kafka 환경에서 Schema Registry를 활용하는 기본적인 방식은 다음과 같습니다. Consumer가 Kafka로부터 메시지를 읽을 때, 해당 메시지에는 스키마 정보와 직렬화된 데이터가 포함되어 있습니다. Consumer는 Schema Registry를 통해 이 스키마 정보를 조회하고, 이를 바탕으로 역직렬화를 수행합니다.
조금 더 구체적으로 설명하면, Consumer는 Deserializer 객체를 사용하여 메시지를 해석합니다. 이 객체는 선언 시에 schema_registry_client와 schema_str/message_type 인자를 받습니다.
- schema_registry_client는 Consumer가 읽은 메시지에 포함된
schema_id를 Schema Registry 를 통해 조회하고 검증하는 데 사용됩니다. - schema_str/message_type은 Schema Registry에
schema_id로 등록된 스키마와 호환되는지 교차 검증에 쓰이며, 메시지를 해석하는 역할을 합니다.
여기서 메세지에 포함된 schema_id 에 해당하는 스키마를 Writer Schema라고 하고, Deserializer 선언 시 전달하는 schema_str/message_type을 Reader Schema라고 부릅니다.
Writer Schema와 Reader Schema 간의 교차 검증을 통해 메시지의 스키마 정합성 및 호환성(Backward, Forward, Full 호환성 등)을 유지할 수 있습니다. 이는 데이터 포맷의 일관성을 보장하고, 시스템 간 호환성을 높이는 중요한 역할을 합니다.
confluent-kafka ProtobufDeserializer 파이썬 라이브러리의 한계
confluent-kafka 에서 제공하는 ProtobufDeserializer 클래스는 Schema Registry에 대한 정보를 인자로 받지 않습니다. 이로 인해 Writer Schema와의 교차 검증이 불가능하며, Reader Schema로 메시지를 해석하기만 할 수 있습니다. 반면, AvroDeserializer와 JSONDeserializer는 Schema Registry 인자를 받아 Writer Schema와의 교차 검증을 지원합니다. 아래에서 Read Schema 와 Writer Schema 와의 교차 검증이 없다면 어떤 문제가 야기될 수 있는지 살펴보겠습니다.
Protobuf는 데이터를 Binary Wire Format으로 직렬화하며, 다음과 같은 정보만 포함됩니다.
- 필드 번호 (Tag Number)
- 데이터 타입 (Wire Type)
예를 들어, 아래와 같은 Protobuf 스키마와 메시지가 있다고 가정합니다.
message Person {
string name = 1;
int32 age = 2;
}
{
"name": "Alice",
"age": 30
}
이 메시지가 Key-Value 형태의 Wire Format으로 직렬화되면 다음과 같습니다.
0a 05 41 6c 69 63 65 10 1e
| Byte | 설명 | 세부 내용 |
|---|---|---|
| 0a | Key | 1 << 3 | 2, Tag Number=1, Wire Type=2 |
| 05 | Value의 길이 | 5 bytes |
| 41 6c 69 63 65 | Value | "Alice"의 UTF-8 인코딩 |
| 10 | Key | 2 << 3 | 0, Tag Number=2, Wire Type=0 |
| 1e | Value | 30의 Varint 인코딩 |
이때, Protobuf는 다음과 같은 정보를 포함하지 않습니다.
필드 이름(name, age)메시지 구조(Person 메시지 타입)전체 스키마 정의(message Person { … })
따라서 필드 번호 (Tag Number) 와 데이터 타입 (Wire Type) 으로 필드를 매핑하기 때문에 다음과 같은 한계가 있습니다.
- 필드 이름이 달라도 문제 없이 역직렬화가 가능합니다.
- 필드 순서가 달라도 영향을 받지 않습니다.
- 메시지 구조가 달라도 오류가 발생하지 않습니다.
예를 들어, 아래와 같이 Producer와 Consumer의 스키마가 다를 경우에도 오류 없이 메시지를 해석합니다.
-
Producer
message Person { string name = 1; int32 age = 2; } -
Consumer
message User { string username = 1; int32 years = 2; }
Consumer는 Tag Number=1을 username으로, Tag Number=2를 years로 해석하게 됩니다. 즉, 필드 이름과 메시지 구조가 달라도 데이터 해석에는 영향이 없지만, 이는 데이터 정합성 검증의 부재를 의미합니다.
또한, Writer Schema가 없기 때문에 Schema Registry에서 지원하는 스키마 호환성 검사 기능을 활용하기 어렵습니다. 이로 인해 Producer와 Consumer 간에 사용하는 스키마의 일관성 유지와 버전 관리가 복잡해질 수 있으며, 스키마 변경 시 호환성 문제가 발생할 가능성도 높아집니다.
이러한 문제를 해결하기 위해 리서치한 결과, confluent-kafka Java SDK는 ProtobufDeserializer가 Schema Registry와 연동되어 Writer Schema와 Reader Schema 간의 교차 검증 및 호환성 검사를 지원함을 확인했습니다. 이 내용은 개선 사항 백로그에 추가했으며, Java SDK 적용 후 보다 체계적인 스키마 관리가 가능할 것으로 기대됩니다.
6. 마무리
이번 로그 파이프라인 개선 작업은 기존의 비효율성을 해결하고 비즈니스 요구사항에 효과적으로 대응하기 위해 진행되었습니다.
그 결과, 데이터 신선도가 기존 1~2시간에서 준실시간(약 3분)으로 단축되었고, 분류 작업의 비효율성을 해소하면서 데이터 적재 속도와 안정성이 크게 향상되었습니다.
또한, 데이터 생산자와 소비자가 같은 스키마를 공유하며 관리하게 됨으로써 데이터 품질과 일관성이 강화되었습니다.
하지만 여전히 해결해야 할 과제가 남아 있습니다. 현재 Consumer에서 Schema Registry를 통한 검증 로직이 완벽하지 않아 잘못된 메세지 데이터에 대한 에러 감지가 쉽지 않습니다. 이는 운영 효율성을 저하시킬 수 있으며, 이를 개선하기 위해 Schema Registry 를 활용한 검증이 반드시 필요합니다. 또한, 데이터 파이프라인 신뢰성을 높이기 위해 모니터링 및 알림 시스템을 강화해야 합니다.
새로운 파이프라인은 실제 비즈니스에 성공적으로 적용되고 있습니다. 특히, 최근 쏘카와 네이버의 제휴 서비스에서 발생하는 로그는 신규 로그 파이프라인을 통해 적재 중이며 현재 안정적으로 운영 중에 있습니다.
이 경험을 통해 신규 아키텍처의 안정성과 유연성을 검증할 수 있었으며, 향후 유사한 실시간 로그 처리 환경에 적용할 수 있는 가능성을 확인했습니다.
네이버 맵에서 쏘카 예약하기
이번 글에서는 기존 파이프라인의 문제점과 이를 해결하기 위한 아키텍처 개선 과정을 다뤘습니다. 다음에는 Schema Registry 검증 로직 보완과 모니터링 시스템 강화를 통해 추가적인 개선을 할 예정입니다. 읽어주셔서 감사합니다.