 험프리
험프리안녕하세요. 데이터 비즈니스 본부 - 데이터 엔지니어링 그룹의 험프리입니다.
데이터 엔지니어링 그룹은 데이터 플랫폼 팀, 데이터 웨어하우스팀으로 나누어 쏘카의 구성원들 누구나 쏘카의 데이터를 쉽고 빠르게 조회할수록 최적의 방안을 마련하고 지원하는 일을 수행하고 있습니다. 그중 데이터 플랫폼 팀은 데이터 엔지니어링 그룹 내뿐만 아니라 데이터 비즈니스 본부 내의 엔지니어링 파트에서 서포트에서 필요한 인프라, 데이터 파이프라인 개발, 운영, 모니터링, 데이터 애플리케이션 개발, MLOps 등의 업무를 맡고 있습니다.
1. 들어가며
쏘카에서는 데이터 분석가나 모델러, PM 등 여러 이해관계자가 데이터를 의사 결정에 활용하고 있습니다. 쏘카가 다루는 모빌리티 도메인의 데이터는 특히나 러닝 커브가 높습니다. 때문에 다양한 배경의 구성원들이 더 쉽게 쏘카의 데이터를 활용하기 위해 이미 오래전부터 데이터 마트를 운영하고 있습니다.
하지만 여느 소프트웨어가 그렇듯 시간이 지남에 따라 비즈니스가 성장하고 새로운 사업들이 추가되면서, 그로부터 만들어지는 데이터를 반영하여 데이터 마트를 유지 보수하는 비용도 증가했습니다. 이미 복잡하게 얽혀있는 데이터에 새로운 데이터를 쌓아올려 비즈니스 이해관계자들이 쉽게 원하는 데이터를 조회할 수 있도록 유지하는 데는 많은 노력이 필요했습니다.
이 글에서는 쏘카에서 복잡하게 얽혀있던 데이터 마트와 그를 지탱하는 데이터 파이프라인들을 견고하고 재사용 가능하게 만든 유즈케이스를 소개하고, 더 넓은 시각에서 규모를 키워가는 조직에서 데이터와 메타데이터를 관리하는 방법, 그리고 앞으로 나아가야 할 방향에 대해서 이야기하려고 합니다.
예상 독자는 다음과 같습니다
- 모던 DW를 이용해 데이터를 제공하는 데이터 엔지니어
- 데이터 마트 구성과 모델링 등의 고민을 해본 적 있는 데이터 분석가
- 서비스 데이터를 효과적으로 분석하기 좋은 형태로 만드는 방법을 고민하는 백엔드 엔지니어
- 데이터를 이용해 업무를 하는 모든 직군
1.1. 쏘카의 데이터 인프라

다양한 원천(Raw) 데이터를 빅쿼리로 모으고, 빅쿼리 내의 SQL로 테이블을 생성하는 기능을 활용해 가공한 테이블들을 만들고, 가공한 데이터들을 모아 집계된 테이블들을 만들어 활용합니다.
1.2. 양 날의 검
빅쿼리를 중심으로 만들어진 데이터 인프라 구조는 장단점이 명확했습니다.
- 장점
- 스토리지 비용이 비교적 저렴합니다.
- SQL을 통해서 프로그래밍 지식이 없어도 쉽게 데이터를 조회하고, 변형할 수 있습니다.
- 다양한 소스의 데이터를 쉽게 저장하고, 조회할 수 있습니다.
초기 빅쿼리 중심으로 데이터 인프라를 만들면서 쏘카는 기존 시장에서 우위를 점하고 있던 Hadoop과 Spark 기반의 인프라에 비해 빠르게 발전할 수 있었습니다. 많은 선수 지식이 필요하고 데이터 조직을 중심으로 중앙 집중적으로 만들어지고 관리되는 기존 데이터 인프라와 달리, 빅쿼리를 중심으로 한 데이터 인프라는 민주적으로(!) 데이터를 만들어내고 관리할 수 있어 관련 지식이 없더라도 쉽게 데이터에 접근하고 활용할 수 있습니다.
- 단점
- 쉽게 넣을 수 있다 보니, 데이터 검증에 대한 고려를 하지 않는 경우가 많습니다.
- 데이터(데이터셋, 테이블) 히스토리와 오너쉽 등을 파악하기 어렵습니다.
- 데이터 간 의존성, 삭제 영향도 또한 파악하기 어렵습니다.
사내 빅쿼리 사용 유저만 해도 전체 300여 명 중 100명이 훨씬 넘는 분들이 빅쿼리를 통해 쏘카의 데이터에 접근하게 되었습니다. 시간이 지나면서 정말 많은 데이터가 빅쿼리에 쌓이게 되었고, 이를 모두 제어하려 하는 일은 여러 조직의 속도를 늦추는 일이 될 수도 있었습니다.
같은 데이터를 다루는 테이블도 만드는 사람에 따라 로직이 다를 수 있고 그에 따라 데이터 사용자가 “알아서” 검증을 해야 했고, 이를 개선하기 위한 데이터 마트를 만드는 데이터 엔지니어가 그 검증에 대한 책임을 도맡아야 했습니다. 또한 해당 데이터에 대한 히스토리 파악은 기존 테이블 생성자로부터 직접 전달받거나, 테이블을 생성하는 수 백 줄의 쿼리나 파이썬 코드를 보면서 직접 파악을 해야 했습니다. 때문에 데이터 마트를 추가하는 작업의 난이도가 시간이 갈수록 높아져 갔습니다.
테이블을 지우는 일도 신경을 써야 했습니다. 지우려는 테이블이 어떤 곳에 얽혀있는 지도 모르는 채, 테이블을 삭제하면 어떤 사이드 이펙트를 불러올지 몰랐습니다. 혹여나 매우 중요한 데이터 마트 테이블에 엮여있는 테이블들을 삭제한다면, 매출과 같은 중요한 데이터에 이슈가 생길 수도 있습니다.
위와 같은 단점들은 시간이 지나면 지날수록 발목을 잡았고, 문제들을 해결하기 위한 비용도 급속도로 커져만 갔습니다. 마치 소프트웨어 엔지니어링에서 이야기하는 “A big ball of mud”처럼요.
 출처:
출처: 1.3. Analytics Engineer의 등장
위와 같은 문제점들은 저희만 겪고 있는 문제는 아니었습니다.
Snowflake, Delta Lake 등 최근 부상하고 있는 모던 데이터 웨어하우스를 운영하고 있는 팀들은 비슷한 문제들을 겪고 있었고 각자에 상황에 맞는 방법으로 해결하고 있습니다.
그러는 와중 저희의 눈에 띈 하나의 큰 흐름은, 데이터를 사용해서 비즈니스적인 의사결정을 도와주는 데이터 분석가와 데이터 파이프라인들을 만드는 데이터 엔지니어 사이에 중간자 적인 역할을 해주는 Analytics Engineer라는 직군이 등장하게 된 것입니다.
Analytics Engineer의 대표적인 role은 아래와 같습니다.
- Data Modeling: 데이터 모델링을 통해 유즈케이스에 맞게 데이터를 관리할 수 있도록 모델링 합니다.
- Data Warehouse Management: 데이터 웨어하우스를 관리해서 사용자들이 쉽게 데이터를 조회하고 히스토리 등을 확인할 수 있게 합니다.
- Data Orchestration: 스케줄링 도구 등을 사용해서 데이터가 정상적으로 업데이트 되도록 관리합니다.
- Setting Best Practices: 모델링과 데이터를 관리하는 사내의 Best Practice를 정의하고 구현하도록 돕습니다.
- Cross-collaboration: 분석가나 엔지니어와 소통하며 비즈니스 요구 사항을 수집하고, 성공적인 분석 결과를 만들어 내고, 모델링에 다른 조직의 요구 사항을 반영합니다. 또한 소프트웨어 엔지니어링의 실천 방법을 분석에서도 유용하게 사용할 수 있도록 돕습니다 (Version Control, Testing, … )
해외의 다양한 회사에서 Analytics Engineer를 채용하고 있습니다.
https://about.gitlab.com/job-families/finance/analytics-engineer/ https://www.glassdoor.com/Job/analytics-engineer-jobs-SRCH_KO0,18.htm https://www.glassdoor.com/Job/analytics-engineer-jobs-SRCH_KO0,18.htm
Analytics Engineering의 등장에서 얻을 수 있는 교훈은 1) “중요한” 데이터들을 오너십을 갖고 관리하고 발전시켜 나가는 시스템의 필요성, 2) 일반적인 조회뿐만 아니라 재사용 가능하게 만드는 노력, 그리고 3) 데이터 간의 의존성 및 메타데이터 관리의 중요성이었습니다.
| Data Engineer | Analytics Engineer | Data Analyst |
|---|---|---|
| 커스텀 데이터 통합 기능을 만듭니다. | 클린하고, 정제되고, 분석 가능한 데이터를 제공합니다. | 데이터 인사이트 관련 (e.g., 왜 유저 이탈이 지난 달에 높았을까?) |
| 전반적인 파이프라인 오케스트레이션을 관리합니다. | 소프트웨어 엔지니어링의 베스트 프랙티스를 분석 코드에 적용합니다. (e.g., version control, testing, CI 등) | 비즈니스 이해 관계자와 협업하여 요구 사항을 파악합니다 |
| 데이터 플랫폼을 만들고 유지보수 합니다. | 데이터 문서와 정의 등을 유지보수 합니다. | 중요한 대시보드를 만들고 유지보수 합니다. |
| 데이터 웨어하우스의 성능 문제를 최적화합니다. | 비즈니스 데이터 유저가 시각화 툴을 사용할 수 있도록 교육합니다. | 데이터를 통해 예측 합니다. |
직군별 비교 (Data Engineer vs Analytics Engineer vs Data Analyst)
하지만 어떤 기술이던 그러하듯, 다른 회사에서 작동했던 개념과 기술들이 우리 조직에서도 잘 도입되고 활용되려면 많은 노력과 고려가 필요하다고 생각했습니다. 큰 회사에서처럼 당장 Analytics Engineering만 담당하는 인원을 채용해서 발전시키는 게 현실적으로 어렵기도 하고, 또한 이러한 분야의 발전이 조직에서 필요하다는 컨센서스를 만드는 과정도 시간이 많이 들 수 있는 일이었습니다.
2. data build tool(dbt)
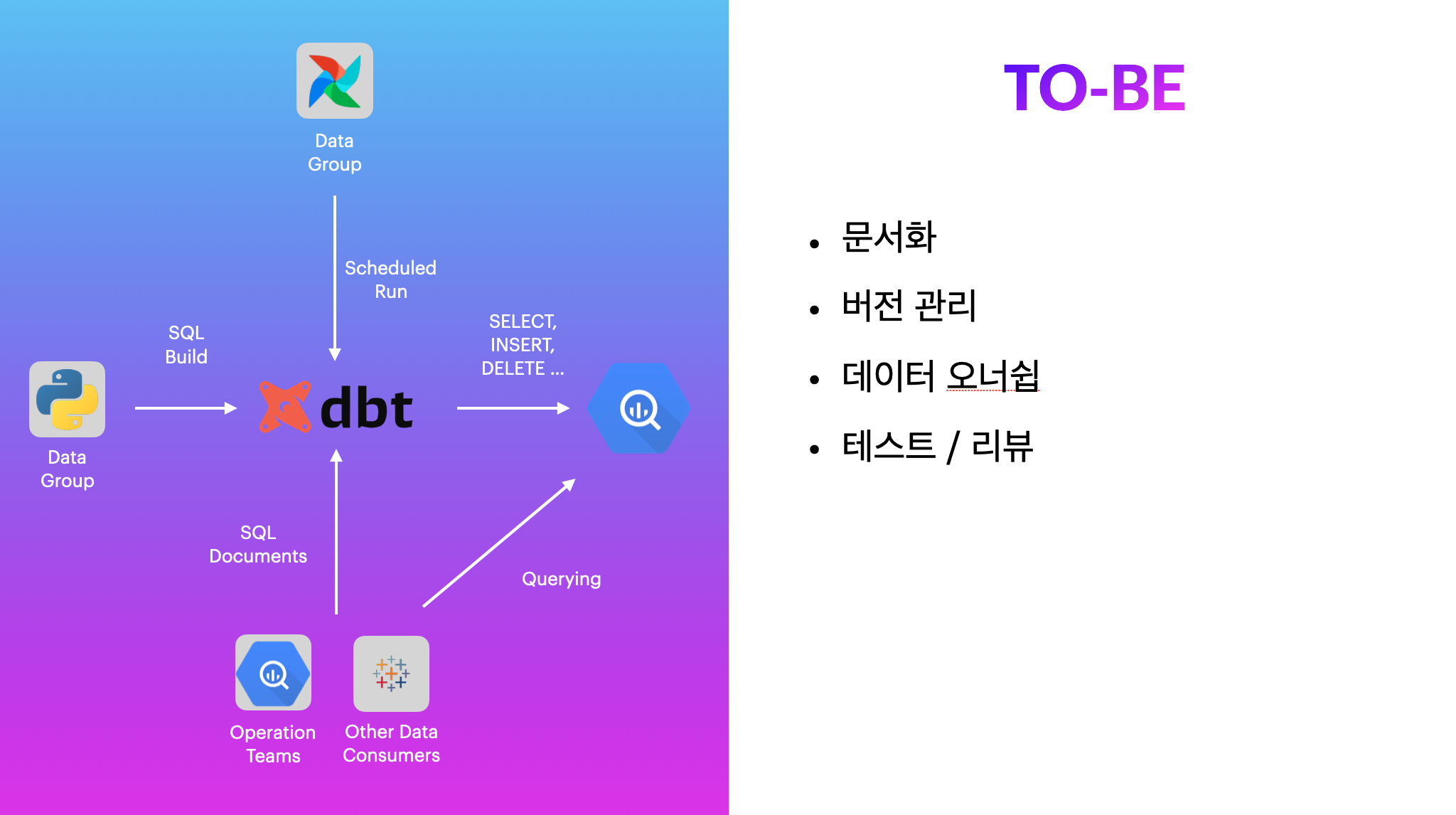
dbt는 데이터 엔지니어링의 큰 요소 중 하나인 ETL or ELT (Extract, Transform, Load) 중 변형(Transform)에 집중합니다. 어디서 데이터를 추출해 내고 적재하는지에 대한 관심보다는 “어떻게” 존재하는 데이터를 변형해서, 재사용할지에 대해 고민합니다.
](/img/analytics-engineering-with-dbt/dbt4.png)
dbt를 통해 데이터를 검증, 변형한 후 자동화된 문서와 데이터 리니지(계보)를 제공해서 데이터 사용자가 쉽게 원하는 데이터를 찾아서 쓸 수 있게 만들어 줍니다. 쏘카에서 사용하는 빅쿼리뿐만 아니라, Snowflake, Postgres, Redshift, Delta Lake와 같은 다른 데이터 웨어하우스 기술들과도 쉽게 연결해서 사용할 수 있는 integration을 제공합니다.
가장 매력적인 부분은 대부분의 기능들을 SQL만 알아도 이용할 수 있고, Yaml만 조작해도 수백 GB의 큰 테이블에 대한 테스트, 문서 화 등의 일련의 작업들을 쉽게 할 수 있다는 점이었습니다. 쏘카는 위에서 언급한 것과 같이 조직 내 많은 인원들이 SQL을 사용하고 있어서 더욱 적합하다고 판단했습니다.
또한 데이터 관련 작업들에서 부가적으로 얻을 수 있는 이점들이 꽤 있다고 생각했습니다.
- 쿼리의 버전 관리: SQL을 사용하는 많은 분들이 별도의 버전 관리를 하지 않고 있습니다. dbt를 사용하면 SQL 기반 데이터 파이프라인의 배포를 Git의 라이프사이클 안에서 만들어나갈 수 있고, 쿼리에 대한 리뷰 그리고 나아가 데이터에 대한 정보가 흐를 수 있는 문화를 만들어 갈 수 있는 발판이라고 생각했습니다.
- 오너십: ‘주인 없는 데이터’는 분석을 하기에 생각보다 큰 허들입니다. 가져다가 사용하기도, 그렇다고 없애기도 애매하죠. 어떤 로직으로 동작하는지 확인을 하기 위해 SQL을 확인하는 것도 한계가 있을 수 있습니다. dbt를 사용하며 쿼리에 대한 문서화와 히스토리를 작성하는 문화를 만들어가면서 ‘SQL 드리븐 데이터’에서 좀 더 ‘사람 드리븐 데이터’로 옮겨갈 수 있을 거라고 생각했습니다.
사실 dbt 말고도 비슷한 문제를 해결하는 기술들이 아시다시피 꽤 많습니다.
dbt의 대안으로 생각되는 기술들로는 다음과 같은 기술들이 있습니다.
⚠️ 아래 다른 기술과의 비교는 지극히 개인적인 저의 판단입니다.
| 이름 | 장점 | 단점 | 비고 |
|---|---|---|---|
| Dataform | BigQuery에 집중. SQL 기반. SaaS 기반 웹 IDE 무료 제공. Looker 연동 |
Self Hosting 불가 (as opposed to dbt), 비싼 가격 (당시 월간 유저 당 $95), Typescript 기반 |
|
| Soda SQL | 오픈 소스, 직관적인 Yaml 활용법 (Sql In Yaml), Python 기반 |
유저풀이 적음. Yaml 관련 오퍼레이션이 많아서 더 복잡함. |
최근에는 Yaml + SQL 기반에서 자체적인 DSL(SodaCL)을 만들어 사용 |
| Great Expectation | 데이터 테스팅 및 분포 UI, 테스팅 Preset | 무겁다. 어렵다. |
dbt는 다른 툴들이 각자 가지고 있는 장점들을 (그만큼 뾰족하지는 않더라도) 전반적으로 시도해 볼 수 있는 툴이고 Analytics Engineering을 빠르게 도입하고 구현하는 데 저희 조직에 가장 알맞은 툴이라고 생각했습니다.
dbt는 두 가지 방법으로 서비스를 제공하고 있습니다. dbt Cloud와 dbt CLI입니다. 전자는 Team Plan 기준 월간 인당 50불(…)의 비용을 내면서 쓸 수 있고, Airflow와 같은 workflow와 Git Integration, Alerting 등의 다양한 기능들을 제공해 줍니다. 후자는 무료로 dbt의 많은 기능들을 전부 이용할 수 있었지만, 자유도가 높은 만큼 러닝 커브와 세팅을 위한 인프라 및 애플리케이션 배포 작업이 필요합니다.
저희 조직은 분석가 대비 엔지니어가 꽤 많은 (당시 8명) 상황이었고, 세팅을 위한 역량도 충분히 갖춰져 있는 상황이었고 오히려 분석가들 및 SQL 사용자가 모두가 dbt Cloud를 사용한다면 지불해야 하는 Cost가 더 크다고 생각했습니다. 그래서 dbt CLI를 기반으로 여러 가지 시도를 해보기 시작했습니다.
⚠️ dbt에 대한 기본적인 사용법은 이 글에서 다루지 않습니다.
더 자세한 dbt에 대한 정보는 dbt 공식 문서와 제 개인 블로그를 참고해 주세요.
dbt - Transform data in your warehouse
dbt로 ELT 파이프라인 효율적으로 관리하기
3. 유즈 케이스 - SODA Store v2
SODA Store는 2020년 부터 유지되어왔던 쏘카의 비즈니스와 맞닿아 있는 지표들을 모아놓은 데이터셋을 부르는 별칭입니다. (SOCAR + Data Store = SODA)
소다스토어에는 사고 집계 데이터, 예약 당시 차량 상태, 분석을 위한 일간 차량 데이터, 예약 누적 데이터 등 쏘카 내의 여러 개의 MSA에 걸쳐서 나눠져 있는 데이터를 집계해 관리하고 있습니다.
이 파트에는 조금 더 저 수준에서 어떻게 프로젝트를 만들어 나갔고, 어떤 의사 결정과 문제를 해결했는지에 대해서 자세히 이야기해보려고 합니다.
3.1. 프로젝트 시작 전
분석
기존 소다스토어는 에어플로우를 통해 빅쿼리로부터 오직 SQL만을 통해서 데이터 전처리를 진행하고, 전처리 및 변형 과정이 끝난 데이터를 모두 빅쿼리에 적재하는 방식으로 테이블을 적재했습니다.
이 방법은 매우 편하고 관리 포인트도 적었지만 다음과 같은 한계점이 존재했습니다.
- 로직을 담은 SQL이 매우 비대했습니다. (≥ 500 Lines)
- 테스트의 부재 및 실패 시 이유를 찾기 어려움
- 흐르지 않는 도메인 지식 및 이슈 트래킹
- 위의 이유들 때문에 새로운 데이터를 추가하거나 기존 데이터 관련 이슈를 트러블 슈팅하기 어려움
위와 같은 한계점이 존재함에도 불구하고, 소다 스토어는 총 66만 회 이상의 쿼리에서 참조 되고, 데이터 관련 직군 외의 사업, 운영, 마케팅, 전략 등 다양한 부서에서 고르게 사용되며 비즈니스 의사 결정에 기여하고 있습니다.
해당 이슈를 해결해야 빠르게 성장하는 쏘카의 비즈니스의 데이터와 관련한 의사 결정에 기여할 수 있도록 할 수 있다고 생각했습니다.
목표 설정
위와 같은 문제를 해결하기 위해서 Analytics Engineering이 필요하다는 생각을 하게 되었습니다.
SODA Store에 Analytics Engineering을 적용하며 가진 목표는 다음과 같았습니다.
SODA Store v2 주요 목표
- 기존 테이블의 사용성 검토 및 정비
- 신규 서비스 및 요구사항에 따른 마트 테이블 추가 작성
- 외부에 분산된 마트 테이블들의 통합 검토
- 지표 데이터 정리
Analytics Engineering 주요 목표
- 테이블 테스트 추가 및 정합성 검증
- 테이블 모델링 (정규화, 컬럼 필터링 등)
- 데이터 의존 관계 시각화 (데이터 리니지)
- 데이터 문서화
계획
위 목표를 달성하기 위해 넘어야 했던 가장 큰 허들은 1) dbt라는 툴에 대한 이해, 2) 복잡한 도메인 지식에 대한 심리적 안정감 높이기였습니다.
때문에 다음과 같이 단계를 나누어서 진행을 하도록 계획했습니다.
- 프로젝트 구성
- 테이블 모델링 & 테이블 테스트 추가
- 검증
- 배포
3.2. 프로젝트 구성
소다 스토어의 쿼리는 이미 Airflow를 통해 적재 중인 DAG에 정의가 되어 있습니다.
프로젝트를 구성할 때는 해당 SQL 파일을 그대로 옮겨와 빠르게 작업을 할 수 있습니다.
dbt 레포 셋업
소다 스토어 v2를 위한 레포 구성은 일반적인 dbt init 을 통한 구조와는 살짝 달랐습니다.
.../socar-data-soda-store
├── .github # Github action 관련
├── cli # 커스텀 CLI 툴
├── scripts # 배포를 위한 스크립트
└── soda_store # dbt 프로젝트 구성에 필요한 모듈
이렇게 커스터마이징을 했던 이유는 소다 스토어의 특성이 있습니다.
소다 스토어는 데이터 마트로서의 역할도 하지만, SQL 및 로직 자체가 다른 쿼리 사용자가 참고를 많이 하고 있습니다.
때문에 SQL 문 자체를 다양한 환경에서 사용할 가능성이 있습니다. 예를 들어 BigQuery에서 직접 해당 SQL을 사용하는 것도, 또는 애플리케이션 또는 Airflow 등의 전반적인 Python 환경에서 SQL 문을 import 해서 사용하거나, 아니면 CLI로 사용하는 경우도 생길 수 있을 거라고 생각했습니다.
때문에 dbt 파일 구조를 공식 문서에서 가이드 하는 대로 하지 않고 일반적인 Python 라이브러리 구조와 같이 가져간다면 패키징과 빌드에 적합한 형태로 만들어갈 수 있고, 쏘카 사내 Pypi 레포 등을 통해서 소다 스토어에서 빅쿼리에 있는 데이터와 로직을 그대로 사용해서 데이터를 추가적으로 정제할 필요 없이 그대로 사용할 수 있다는 이점이 있습니다.
또한 Profile에 대한 설정(profiles.yml)을 변경했습니다. dbt에서 profile은 데이터웨어하우스 (e.g., BigQuery, Snowflake, Delta Lake 등)에 대한 설정부터,
개발 및 운영 환경에 대한 정보를 다루는 가장 중요한 설정에 대한 정보가 담겨있는 파일이라고 할 수 있습니다. 때문에 dbt init을 통해 프로젝트를 생성하면 기본적으로 유저의 ~/.dbt 디렉토리에
profiles를 생성하고 dbt CLI가 해당 디렉터리를 바라보도록 설정이 되어있습니다.
소다 스토어를 구성하면서는 profiles.yml 을 soda_store 즉, dbt 디렉토리 안으로 가져왔습니다. 그 이유는 재사용성을 위함이었습니다.
jaffle_shop:
target: dev
outputs:
dev:
type: postgres
host: localhost
user: alice
password: <password>
port: 5432
dbname: jaffle_shop
schema: dbt_alice
threads: 4
위는 profiles.yml 파일의 예제입니다. 파일을 보시면 직접 host, user, pw 등 데이터웨어하우스에 대한 credential 정보를 직접 입력할 수 있게 됩니다. 작업자가 혼자라면, 위와 같이 관리해도 되지만 공동으로 작업을 하고 빠르게 CI/CD 파이프라인을 통해서 배포하게 되려면 인프라 레벨에서 환경 변수를 통해서 오버라이딩하기 쉽게 만들어주는 과정이 필요하다고 생각했습니다.
soda_store:
target: dev
outputs:
dev:
type: bigquery
method: service-account
project: ...
dataset: ...
threads: 1
timeout_seconds: 300
priority: interactive
maximum_bytes_billed: 1000000000000 # 1TB
keyfile: "{{ env_var('GOOGLE_APPLICATION_CREDENTIALS', '') }}"
ci:
type: bigquery
method: service-account
project: ...
dataset: ...
threads: 10
timeout_seconds: 3000
priority: interactive
maximum_bytes_billed: 1000000000000 # 1TB
keyfile: "{{ env_var('GOOGLE_APPLICATION_CREDENTIALS', '') }}"
live:
type: bigquery
method: service-account
project: ...
dataset: ...
threads: 5
timeout_seconds: 300
priority: interactive
keyfile: "{{ env_var('GOOGLE_APPLICATION_CREDENTIALS', '') }}"
dbt에서는 {{ env_var('ENV_VAR', 'default') }} 와 같이 Yaml 상에 환경 변수를 런타임에서 치환할 수 있게 하는 편의 기능을 제공할 수 있어, 쿠버네티스 환경에서 Configmap과 Secret을 활용해서 Volume Mount 및 Env를 애플리케이션에 적용해 각기 다른 환경에도 쉽게 배포를 할 수 있도록 만들 수 있습니다.
환경별 셋업 (dbt Profile + Infra)
CI(PR Check)
CI 환경에서는 PR 단계에서 만든 유저의 변경 사항들을 적용해서 dbt test 및 run 커맨드를 실행합니다. 해당 변경 사항이 기존의 데이터 validation 테스트를 깨뜨리지는 않는지 확인하고, 테스트가 통과하면 머지 할 수 있도록 Branch Protection Rule을 적용했습니다.
이 부분에서 사실 퍼포먼스를 극적으로 올려줄 수 있는 부분이 있는데 이는 뒷부분 배포에서 다루겠습니다.
개발 환경 (dev)
개발 환경은 개발 데이터 웨어하우스에 연결해서 운영에 적용하기 전 전체 테이블들을 테스트하고 재구성 해보기 위해 만들었습니다.
작업 코드 베이스에서 main에 머지 되면 CI/CD (Github Action) 파이프라인을 통해서 자동 실행되고, 실패 시 운영 배포를 할 수 없습니다.
모든 과정이 에러 없이 통과된다면, 개발 Docker Image를 도커 레지스트리에 푸쉬합니다. 해당 이미지는 Airflow 등의 환경에서 테스트를 하기 위해 사용됩니다.
운영 환경 (live)
운영 환경에서는 여러 가지 시행착오가 있었습니다. 운영을 위한 dbt 이미지를 만드는 과정은 개발 환경과 다르지 않지만, 해당 이미지를 사용하기 위한 런타임 환경을 만드는 과정이 다양했습니다.
고려 및 테스트했던 환경은 1) 일반 도커 이미지 실행 2) dbt RPC, 3) Python 웹서버 4) 도커 이미지 실행 + Object Storage 등이 있습니다. 이에 대한 시행착오와 문제 상황은 아래 3.4 검증을 참고 부탁드립니다.
다음은 기존의 쿼리를 재사용하기 좋은 방법으로 모델링하고, 테스트 가능하게 만드는 과정이 필요했습니다. 기존의 쿼리가 100개 이상의 테이블들을 조인해서 데이터 마트를 만들어내야 했기에 “적절하게” 쿼리를 리팩토링하고 나누는 과정은 매우 어려웠는데요.
dbt 공식 문서에서는 이 문제를 해결하기 위해 fishtown analytics(dbt labs의 전신)의 모델링 패턴을 소개합니다. (최근엔 공식 문서로 들어갔으며, 다음 링크에서 확인할 수 있습니다)
How we structure our dbt projects
How we structure our dbt projects - dbt Docs
- Source: 원천 테이블 또는 서드파티 데이터. 소스 테이블 스키마를 따릅니다.
- Staging Models: 데이터 모델링의 가장 작은 단위. 각 모델은 소스 테이블과 1:1 관계를 갖습니다.
-
Staging Model 규칙
Staging Models는 아래와 같은 규칙을 가집니다.
stg_접두사로 구분한다. (e.g., stg_member__chat)- 컬럼 네이밍, 타입을 일관적인 방법으로 정리되어 있어야 한다.
- 데이터 클렌징이 완료되어 있어야 한다.
- PK가 유니크하고 Non-null 이어야 한다.
-
Staging Model 예제
├── dbt_project.yml └── models ├── marts └── staging ├── braintree └── stripestg_<source>__<object>-
보통 View로 Materialize 된다 (↔ Table)
├── dbt_project.yml └── models ├── marts └── staging └── braintree ├── src_braintree.yml ├── stg_braintree.yml ├── stg_braintree__customers.sql └── stg_braintree__payments.sql -
1 Staging Model, 1 Source Definition
├── dbt_project.yml └── models ├── marts └── staging └── braintree ├── base | ├── base.yml | ├── base_braintree__failed_payments.sql | └── base_braintree__successful_payments.sql ├── src_braintree.yml ├── stg_braintree.yml ├── stg_braintree__customers.sql └── stg_braintree__payments.sql - Staging Base 모델로 공통 로직 모듈화 시키기도 합니다.
-
- Mart Models: 비즈니스와 맞닿아 있는 데이터들을 다루는 모델
-
Mart Model 예제
├── dbt_project.yml └── models ├── marts | ├── core | ├── finance | ├── marketing | └── product └── staging기본적인 Mart 모델은 위와 같이 비즈니스 또는 조직의 구조와 닮아있습니다.
Mart 모델은 Fact와 Dimension 모델로 구성됩니다.
- fct_<verb>: 길고 좁은 테이블 (컬럼이 적고, 로우가 많은), 현실의 프로세스들을 나타내 줘야함. e.g., Sessions, Transactions, Orders, Stories, votes
- dim_<noun>: 짧고 넓은 테이블 (컬럼이 많고, 로우가 적은), 각 Row가 사람, 장소, 사물 등. 변경가능하지만 변경 주기가 긴 것들이 온다. e.g., 고객, 상품, 빌딩, 직원 등
Mart 모델에서 유용한 패턴
- 쿼리 퍼포먼스를 위해 Fact와 Dimension 테이블들은 Table로 Materialize 합니다.
- 중간 변환 과정의 테이블들을 Mart 모델 안에서 남겨둡니다.
- 각 모델의 테스트 Yaml을 추가합니다.
- MD(Markdown) 파일로 문서화합니다.
├── dbt_project.yml └── models ├── marts │ ├── core │ │ ├── core.md │ │ ├── core.yml │ │ ├── dim_customers.sql │ │ ├── fct_orders.sql │ │ └── intermediate │ │ ├── customer_orders__grouped.sql │ │ ├── customer_payments__grouped.sql │ │ ├── intermediate.yml │ │ └── order_payments__joined.sql │ ├── finance │ ├── marketing │ └── product └── staging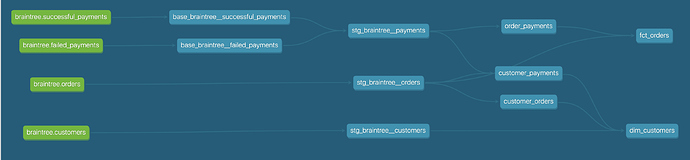
-
Gitlab에서는 위와 같은 Fishtown Analytics의 모델링 패턴을 참고해서 팀 고유의 모델링 패턴들을 만들어 나가고 있습니다. (참고 링크 : dbt Guide, 놀랍게도 SQL을 포함한 모든 소스 코드가 Public입니다)
쏘카에서도 위 패턴을 좀 더 활용해 독자적인 모델링 패턴을 사용했습니다.
models/
|- mart
|- ods # NEW!
|- staging
ODS는 엔터프라이즈 데이터웨어하우스(EDW)에서 사용되는 개념으로, 임시로 운영계 데이터를 보관하는 장소입니다. Mart에 레이어에 본격적으로 마트 테이블들을 생성하기 전에, ODS에 메인 로직들을 저장해 두고 Mart에서는 해당 ODS 레이어의 모델을 레퍼런스 해서 사용합니다.
ODS 레이어를 추가하게 된 가장 큰 이유 중 하나는, 소다 스토어의 경우에는 기존에 존재하는 데이터(v1)와 값을 비교를 하기 위해서입니다. ODS에서는 메인 로직들을 담아두고, (대부분의 케이스에서) View로 모델을 생성합니다. 그 덕분에 Mart에서는 ODS 모델을 레퍼런스 해서 Table로 Materialize를 시키면, 해당 작업이 시작한 시점 기준으로 테이블들을 만들 수 있어 기존에 존재하는 v1 데이터와 적재 시점을 동일하게 만들어 데이터를 비교할 수 있습니다.
또한 가독성을 위해서도 필요했습니다. Staging에서는 원천 테이블에 대한 가공, Mart에서는 Staging에 있는 모델들을 조합해서 비즈니스 지표에 가까운 테이블을 만들어 낸다면, Mart에 로직이 대부분 집약되어서 부수 테이블이 많이 만들어져서 결국 Mart 테이블들의 데이터들을 이해하기 어려워졌습니다. ODS에 메인 로직들을 분산해서 저장해 두고, Mart는 최대한 SELECT ... FROM ... WHERE
로 표현해서 비즈니스 지표들을 찍어낼 수 있다고 판단했습니다.
해당 부분은 모든 dbt 프로젝트에 적용하기보다는 기존 쿼리 및 데이터 비교를 위한 작업이라면 참고해 볼 수 있을 패턴이라고 생각합니다.
3.3. 검증
소다 스토어에서 검증해야 하는 것은 명확했습니다.
- 기존 데이터와 “정확히” 일치해야 한다.
- 기존 데이터에서 논리적 및 통계적인 오류가 없어야 한다.
위 요구 사항은 모두 dbt의 테스트 기능을 활용해서 해결했습니다.
기존 데이터와 “정확히” 일치해야 한다.
기존 데이터를 dbt 코드 베이스에 Source 테이블로 만들어서 검증하는 방법도 있었지만, 매번 기존 테이블을 가져와서 새로운 테이블로 만드는 건 비효율적이라고 생각했습니다. 때문에 dbt 코드에 포함하지 않고 Macro를 통해서 쿼리를 이용해서 아래와 같이 검증하도록 만들었습니다.
{% test compare_v1_and_v2(model, model_name) %}
{% set v1_soda_store_dataset_ref = 'v1_table' %}
(
(select * from {{ v1_soda_store_dataset_ref }}.{{ model_name }})
except distinct
(select * from {{ target.project }}.{{ target.dataset }}_ods.ods_{{ model_name }})
)
union all
(
(select * from {{ target.project }}.{{ target.dataset }}_ods.ods_{{ model_name }})
except distinct
(select * from {{ v1_soda_store_dataset_ref }}.{{ model_name }})
)
{% endtest %}
version: 2
models:
- name: mart_model
tests:
compare_v1_and_v2:
model_name: "table_from_v1"
columns:
- name: column1
description: 컬럼1
기존 데이터에서 논리적 및 통계적인 오류가 없어야 한다
이 부분은 dbt에서 기본으로 제공하는 Generic Tests (unique, not_null, accepted_values, relationships) 뿐만 아니라 여러 dbt 패키지들을 사용했습니다.
- dbt-labs/dbt-utils: dbt 공식으로 제공하는 여러 가지 매크로들이 내장되어 있습니다. 매크로를 위한 쿼리를 추가적으로 작성할 필요 없이 테이블에 대한 검증 (e.g.,
unique_combination_of_columns)과 select 문에서 사용할 Column Renaming 매크로 또한 제공합니다. - calogica/dbt_expectations: 위에서 언급했던 Great Expectation에서 제공하는 다양한 검증 preset들을 매크로로 구현해둔 패키지입니다. 테이블 row 또는 column 별 통계 값에 대한 검증이나 String Matching, Distribution Function 등 GE 대비 dbt의 단점들을 보완해 줄 수 있을 만큼 많은 매크로들이 존재합니다.
예를 들어 다음과 같은 테스트를 추가해 보겠습니다.
version : 2
sources:
- name: <your-database>
database: <your-schema>
tables:
- name: <your-table>
description: 'your table'
tests:
- dbt_expectations.expect_compound_columns_to_be_unique:
column_list: [ "col1", "col2", "col3" ]
dbt run을 통해서 아래와 같은 SQL로 변환됩니다.
with validation_errors as (
select col1,
col2,
col3
from `your-database`.`your-schema`.`your-table`
where 1 = 1
group by col1, col2, col3
having count(*) > 1
)
select *
from validation_errors # HERE
dbt로 만들어진 테스트들은 마지막 SELECT 문에서 0개 이상의 로우가 리턴되면 Fail, 아닌 경우에는 Pass 하도록 기본 설정되어 있습니다. 자세한 설명은 dbt test 공식 문서를 참고해 주세요.
위와 같은 패키지를 통해 쉽게 테스트를 Yaml만 수정해서 추가할 수 있었고, 덕분에 기존 파이프라인에 안정성을 더할 수 있습니다.
3.4. 배포
데이터 엔지니어링 그룹의 대부분의 애플리케이션들을 GitOps Principle에 따라서 배포가 됩니다. 따라서 dbt 기반 레포도 마찬가지의 절차를 따라서 구성했습니다. 다만 일반 파이썬 애플리케이션과 달리 배포 전 고려해야 하는 사항들이 꽤 존재합니다.
배포는 다음과 같은 절차로 이루어집니다.
- PR 생성
- CI Test
- 메인 브랜치 머지
- dev 환경 Update
- Release / 운영(live) 환경 Update
소다 스토어 dbt 레포에 테이블을 추가하기 위해 PR을 생성하면 Github Action을 통해 PR의 변경 사항을 감지하고, 정상적으로 SQL 파싱 되고 테스트를 통과하는지 테스트합니다. 아래와 같은 Github Action Workflow를 구성했습니다.
name: Check PR
on:
pull_request:
branches: [ main ]
jobs:
check_pr:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
...
- name: Incremental CI
run: |
bash scripts/ci.sh incremental
env:
GCLOUD_SERVICE_KEY: <SERVICE_ACCOUNT_JSON_PATH>
특별한 부분은 없고, Incremental CI라는 파트가 궁금하실 텐데요. 이 부분은 Slim CI를 다루는 아래 파트에서 이야기하겠습니다. Incremental CI를 통해서 변경이 된 부분만 감지해서, 필요한 부분만 생성할 수 있습니다.
CI 테스트가 통과된 PR만 main 브랜치로 머지 할 수 있도록 Branch Brotection Rule을 설정해서 main을 언제나 배포가 가능한 형태로 유지하고 있습니다.
이렇게 PR 테스트를 하고 main 브랜치로 머지되고 나면, 개발 환경에 배포를 하기 위해 dbt의 개발 Target에 모든 파이프라인을 run 합니다. (Full CI)
name: Dev Publish
on:
push:
branches: [ main ]
jobs:
dev_publish:
runs-on: ubuntu-latest
if: "!startsWith(github.ref, 'refs/tags/v') && !startsWith(github.event.head_commit.message, 'bump:')"
steps:
- uses: actions/checkout@v2
...
- name: Full CI
run: |
bash scripts/ci.sh full
...
- name: GitOps Update Dev
id: gitops-update-dev
continue-on-error: true
run: |
git clone https://github.com/baloise/gitopscli.git
pip3 install gitopscli/
gitopscli deploy --git-provider-url "https://github.com" \
--username $GITHUB_USERNAME \
--password $GITHUB_PASSWORD \
--organisation $GITHUB_ORGANIZATION \
--repository-name $GITHUB_REPOSITORY_NAME \
--file $VALUES_FILE \
--values "{app.container.image.tag: v${GITHUB_SHA::7}" \
--git-user "<your-git-user>" \
--git-email "<your-git-user-email>" \
--commit-message "<your-commit-message>" \
--create-pr \
--auto-merge \
--merge-method="squash"
env:
GITHUB_USERNAME: ${{ secrets.GH_USERNAME }}
GITHUB_PASSWORD: ${{ secrets.GH_PASSWORD }}
GITHUB_ORGANIZATION: ${{ secrets.GH_ORGANIZATION }}
GITHUB_REPOSITORY_NAME: ${{ secrets.GH_REPOSITORY_NAME }}
VALUES_FILE: "<your-values.yaml>"
이 단계가 통과되면, 개발 환경 데이터웨어하우스에 dbt로 메인 로직을 전부 테스트한 상황이 되고, 운영 배포로 Airflow를 통해서 주기적으로 배포할 수 있는 환경이 됩니다.
또한, dbt에서 제공하는 Lineage 웹페이지를 Helm Chart로 구성해 운영하고 있기 때문에 변경 사항을 helm chart 레포에도 전달해 줘야 합니다. 때문에 GitOps CLI라는 라이브러리를 사용해서 해당 레포에 values.yaml에 정의되어 있는 개발 Container Image Tag를 변경해 줍니다.
마지막으로 운영 환경을 위해 Release를 하는 단계만 남았습니다. 운영은 개발 환경 업데이트 보다 쉽습니다. Full CI를 통해서 전체 파이프라인을 재실행할 필요가 없기 때문입니다. 운영에서는 전체 재실행을 하지 않는 이유는 Airflow를 통해서 실행되는 운영 dbt 도커 이미지의 결과와 충돌할 수 있기 때문입니다. 같은 로직을 개발 환경에서는 실행하고 통과했다는 전제하에 운영 이미지를 Release하는 파이프라인에서는 Docker Build, Push, Config Repo Update, Github Release 생성 정도만 하고 있습니다.
Slim CI
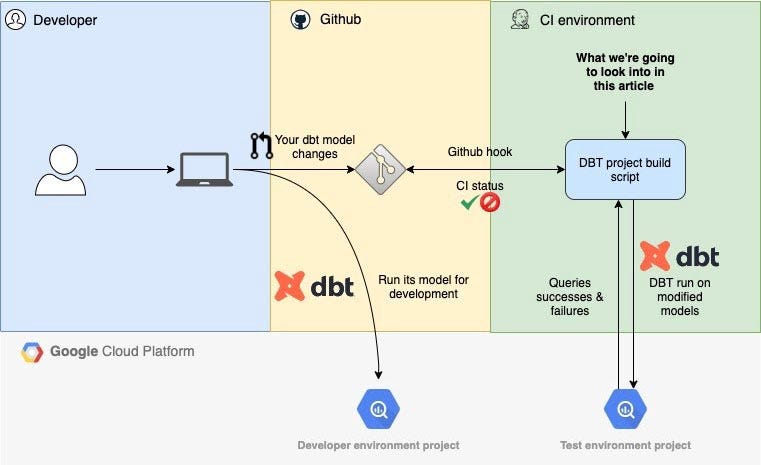 출처: Setup a Slim CI for dbt with BigQuery and Docker
출처: Setup a Slim CI for dbt with BigQuery and Docker
Slim CI는 쉽게 말해서 dbt의 실행 결과를 캐싱해서 필요한 부분만 재실행할 수 있도록 하는 테크닉입니다. dbt Cloud에서는 쉽게 사용할 수 있도록 설정이 되어있지만, dbt CLI 유저라면 직접 구현을 해줘야하는 부분입니다.
간단한 원리를 설명하자면, dbt run을 했을 때 dbt는 Local State를 manifest.json에 저장을 해둡니다. 이 manifest.json이 정상적으로 저장된 정보를 불러올 수 있으면 Graph Selector(state:modified+)로 변경된 사항들만 run을 할 수 있습니다.
하지만 어려운 부분은 저희 조직의 데이터 파이프라인의 대부분은 Docker를 통해서 로직을 실행하고, 따로 볼륨을 관리하고 있지 않아서 dbt 런타임에서 실행하고 컨테이너 내부에 저장된 manifest.json을 다시 불러오기 힘든 환경이라는 점이었습니다.
처음에는 Kubernetes Persistent Volume을 사용해서 영속하는 걸 생각했지만, 그렇게 됐을 때는 dbt 런타임을 계속해서 띄워두고 여러 소스에서 해당 dbt Pod에 요청을 하는 형태가 되어야 했습니다. 해당 Pod 관리 코스트 측면에서 안 좋을 거라고 생각을 했습니다.
다른 방법은 dbt rpc를 이용하는 방법이었습니다. Remote Procedure Call (RPC) 방식으로 dbt 서버에 요청을 보내서 작업을 수행하게 하는 인터페이스를 dbt CLI에서는 제공을 하고 있습니다 (Github Repo). 하지만 이 방식은 현재 Deprecated된 상태로, dbt Server라는 기능으로 대체되어 2022년 이후에 완전히 지원을 중단할 예정입니다. 때문에 지속 가능하지 않은 방법이라고 생각해서 이 방법도 (시도는 했으나) 선택하지 않았습니다.
최종적으로 선택한 방법은 CI/CD 파이프라인을 최대한 이용해서 도커 이미지에 manifest.json을 포함시키는 방법이었습니다.
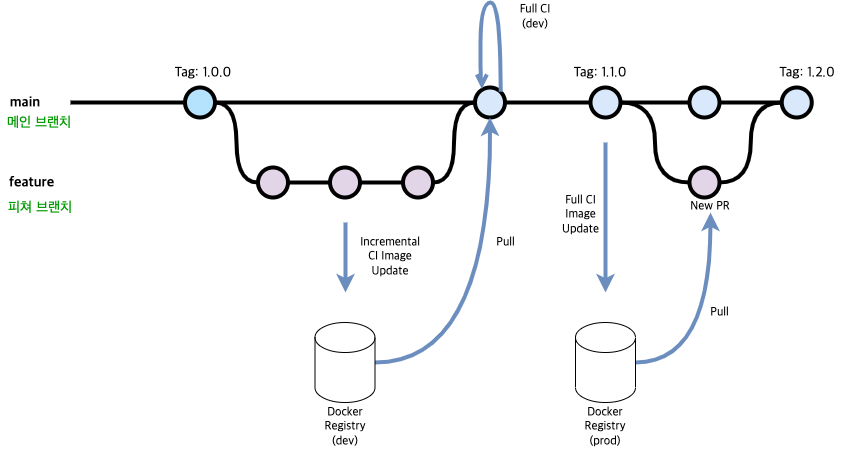
동작시키기 위해서는 두 개의 Dockerfile이 필요합니다.
1) Dockerfile.full.ci
2) Dockerfile.incremental.ci
과정은 다음과 같습니다.
-
(on PR create) → Incremental CI에서 Full CI 이미지 기반으로 도커 이미지를 빌드하고 레지스트리에 저장합니다.
1-1. Full CI 이미지의manifest.json파일이 있으면, 아래와 같은 코드로 현재 코드의 변경 사항만 dbt run을 적용할 수 있습니다.```bash #!/bin/bash ... dbt run --target=ci -s "state:modified+1 1+exposure:*,+state:modified+" --defer --state <your-state-directory> -x --full-refresh dbt test --target=ci -s "state:modified+1 1+exposure:*,+state:modified+" --defer --state <your-state-directory> -x ```1-2. 이 시점에 빌드를 하고 있는 컨테이너 안에는 이전 Full CI가 실행될 때의 코드 + 현재 PR에서의 변경 사항이 합쳐진
manifest.json이 저장됩니다.
1-3. 해당 이미지를 빌드 완료 후 Push 합니다. - (on main branch merge) → Full CI에서 개발(dev) 환경으로 전체 dbt 모델들을 실행하고, 도커 이미지를 만든 뒤 결과물을 레지스트리에 저장합니다. (실패 시, 운영 배포할 수 없습니다.)
- (on release) → 운영(live) 환경으로 dbt 모델들을 실행하지 않고, 이미지만 빌드하고 푸시 합니다.
위와 같은 방식으로 최대 12분 정도 걸리던 PR Check 파이프라인을 1분 내외로 단축시켰습니다. 저희 유즈케이스처럼 테이블이 많은 경우 (100+) 퍼포먼스를 크게 향상시킬 수 있는 예제 같습니다.
굳이 도커 기반으로 푸는 것 말고도 다양한 방법으로도 이런 문제를 해결해볼 수 있을 거라고 생각합니다.
3.5. 결과
Seamless Change

v1 데이터와 v2 데이터가 정확하게 일치하는 것을 확인하고, v1 로직을 v2로 100% 교체해 데이터 사용자분들이 어떤 쿼리 수정이 없이도, 더 신뢰할 수 있고 더 많은 마트 테이블들을 사용하실 수 있게 매끄럽게 교체 작업이 이루어졌습니다.
Data Lineage Graph
 소다 스토어 v2 Data Lineage
소다 스토어 v2 Data Lineage (흐린 눈)
dbt로 이관 후, 소다 스토어를 구성하기 위해 필요한 수많은 테이블들, 그리고 의존관계가 어떻게 흐르는지를 확인할 수 있는 방법이 생겼습니다. 이로 인해 유사시에 어떤 테이블의 오류가 다른 마트 테이블들에 영향을 주는지 시각적으로 알 수 있습니다.
New SODA Store DAG
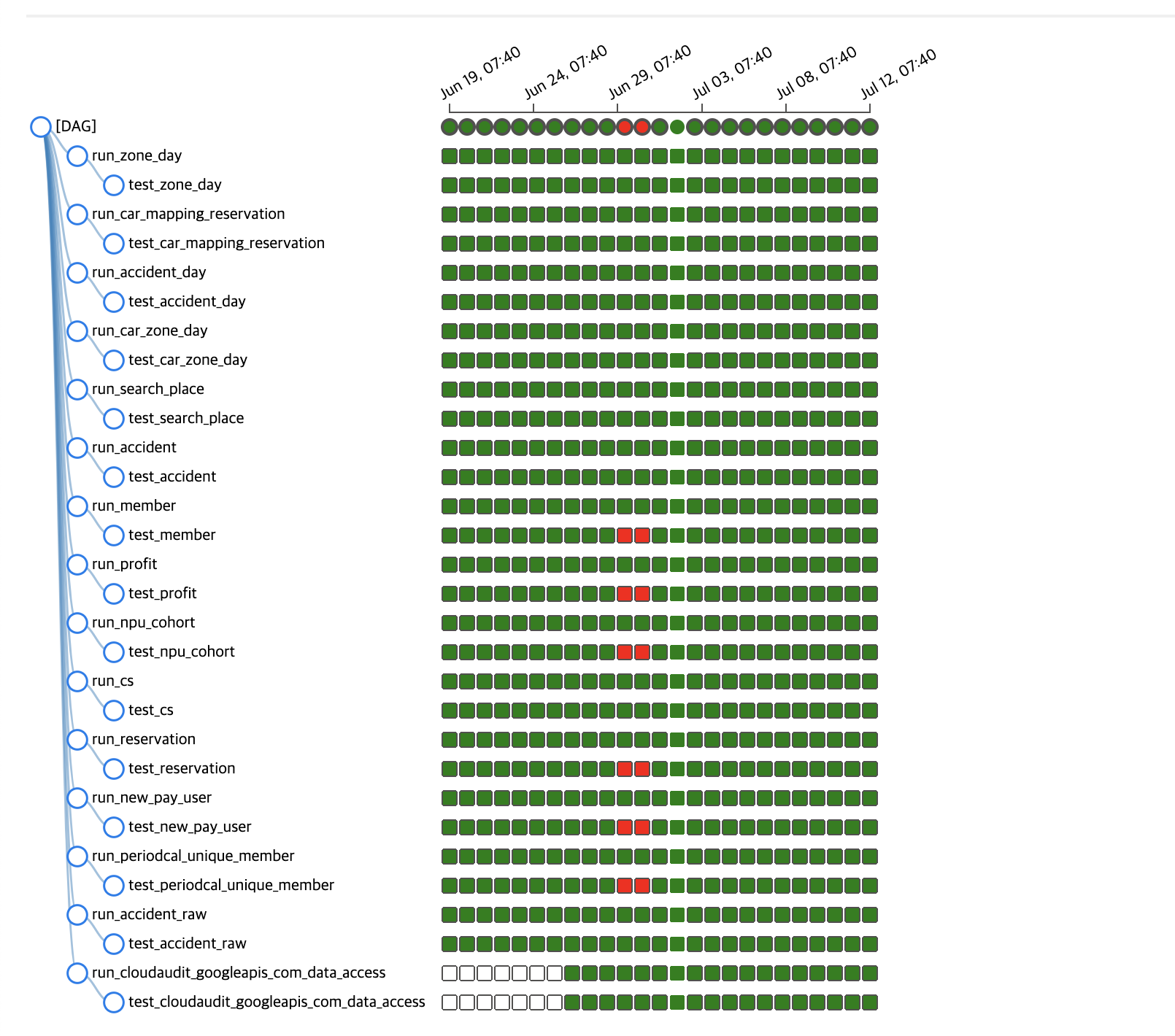
 Airflow DAG (부제: 일했다 dbt)
Airflow DAG (부제: 일했다 dbt)
소다 스토어 v2가 2022년 4월 마무리되고 3개월 뒤인 7월까지 에러를 한 번도 낸 적이 없어 아쉬웠습니다. 다행히(?) 이 글을 쓰고 있는 와중에 해당 테이블에 새로운 서비스 관련 데이터가 추가 되어 한 컬럼에 기존에 정의되지 않았던 값이 들어오자 dbt가 제 역할을 해주었습니다.
4. 그 밖에 시도했던 것들
- Sqlfluff Linting: 초반에 SQLFluff를 이용해서 사용자들의 쿼리 스타일을 모두 통일하려고 했습니다. 하지만 아직 dbt Integration이 생긴지 얼마 지나지 않아서인지 CI 단계에서 설정해둔 파이프라인이 깨지는 일이 많았습니다. 현재에는 Github Action에서 빼놓은 상태입니다.
- dbt Custom Cli Tool: dbt CLI도 많은 기능을 제공하지만, 저희의 유즈케이스에서는 기존에 있는 테이블 dbt 코드 베이스로 이관을 해야 하고, 써줘야 하는 코드가 매우 많았습니다 (e.g. schema.yaml, source.yaml의 테이블과 column, description 등). 때문에 dbt CLI를 래핑 해서 빅쿼리에 저장되어 있는 메타데이터 정보를 dbt에서 사용하는 Yaml로 만들어주는 툴이나, 기존 쓰인 SQL을 dbt에서 사용하는 Jinja SQL로 변환하는 기능 등 저희의 입맛에 맞게 커스텀 툴을 만들어서 사용했습니다. (혹시나 궁금해하시는 분들이 있다면 추후에 오픈소스화하겠습니다)
- Airflow Task Dependency Tree: Astronomer의 이 글처럼 dbt model을 run → test 하는 과정 하나하나를 전부 Airflow Task로 만들려는 시도를 했습니다. dbt Lineage 그래프처럼 Airflow를 통해서도 시각적으로 볼 수 있을 거라고 기대했지만, 아마 다들 예상하시다시피, Task가 너무 많아서 다양한 문제들이 발생했습니다. 때문에 현재와 같이 하나의 Mart를 생성하는 Task들로 구성하게 되었습니다.
5. 알면 좋았던 것들
- 모델링보다 테스트를 먼저
모델링 보다 Source - Staging - ODS - Mart에 이르는 레이어에 대한 테스트가 선행되었다면 뒤에 있었을 안 맞는 데이터들을 맞추는 시간이 덜 들지 않았을까… 코드처럼 TDD를 했으면 더 시간이 덜 들었을 거 같습니다. - 공동 작업을 위한 환경 및 배포 파이프라인 구성
일반적인 애플리케이션들이 그러하듯, dbt 기반 Data Pipeline 또한 배포 파이프라인을 먼저 구성해두고 즉각적으로 변경 사항들이 피드백 루프를 만들도록 구성했으면 커뮤니케이션 코스트가 덜 들 수 있지 않았을까 싶습니다.
6. 개선해야 하는 점들
- 현재 특정 유즈케이스에서만 동작하도록 설정을 해뒀습니다. 더 범용적으로 dbt를 사용할 수 있도록 확장성 있게 레포를 구성하는 게 필요합니다.
- 지속적으로 Analytics Engineering과 관련 기술을 습득하기 위해서는 많은 노력이 필요합니다. 앞으로 어떻게 이 구조를 유지할지 고민이 더 필요할 듯합니다.
7. 나아가서
-
Metric Store
dbt를 활용한 Analytics Engineering이 시작되자, 최신 트렌드인 Metric Store도 도입을 하려고 하는 움직임들이 생겨났습니다.
dbt도 메트릭 스토어로서의 기능도 제공을 하고 있지만, 아직 초기 단계이다 보니 적극적으로 도입하고 있지 않은 상황입니다. 반복적인 업무를 해야 하는 데이터 분석가 또는 사이언티스트 분들의 작업을 간소화할 수 있고 나아가 자동화할 수 있는 부분이라고 생각합니다.
관련해서 dbt-core의 이슈에서 창업 멤버인 Drew Banin이 해당 기능을 제안한 이슈 문서가 매우 인상적이었습니다. 한번 살펴보시는 걸 추천드립니다. -
Data Service (In House)
이 모든 걸 아우르는 반복적 업무들을 개선하기 위한 자체 인하우스 데이터 서비스를 개발하고 불필요한 일련의 과정들을 내재화 시키는 것이 필요하다고 생각합니다.
dbt 기반 SQL 작성과 테이블 의존관계 확인, 간단한 구성으로 Metric으로 만들어서 재사용할 수 있는 기능 등을 생각하고 있습니다.
8. 마치며
dbt와 Analytics Engineering에 대한 제 의견을 종합하자면,
이런 장점이 있어요
- 분석가들의 업무를 개발자 처럼: 일회성 또는 요청 기반의 분석가들의 업무가 Git 중심, CI 파이프라인을 활용한 지속적 테스팅, 지속적 배포 등의 도구를 사용해 더욱 생산성을 높힐 수 있습니다.
- 높아지는 데이터의 재사용성: dbt라는 기술을 통해 데이터 웨어하우스의 기능을 극대화 시킬 수 있습니다. 단순 테이블만 적재하고 쿼리하던 구조에서 벗어나 팩트/디멘션 테이블을 고민하고, View, Materialized View 등의 데이터 웨어하우스 기능들을 활용하거나, 데이터 리니지 그래프를 보며 기존 데이터를 어떻게 더 활용할 지, 또한 데이터 웨어하우스의 모델링에 대한 고민을 시작하게 되었습니다.
- 견고해지는 데이터 파이프라인: 데이터 테스팅, 문서화, 오너십 등의 기능들 그리고 위에 언급한 이점들 덕분에 기존 SQL 기반 데이터 파이프라인을 더욱 견고하게 만들 수 있습니다.
이런 어려움들이 있어요
- 배포 및 버저닝: 분석가로만 구성된 팀에서는 시작하기 어려울 거 같습니다. 지속적인 배포와 버저닝 전략 등 전통적인 소프트웨어 엔지니어 팀에서 할 고민들과 팀의 해법이 정리되어야 제대로 사용하실 수 있다는 생각입니다. 개발 조직의 도움을 받거나 시간을 좀 더 들여서 팀의 입맛에 맞게 사용하는 기간을 더 두시길 추천합니다.
- 러닝 커브: 초기 러닝 커브가 꽤 높은 툴이라고 생각합니다. 기본 기능만 사용하게 되신다면 문제가 없을 수 있으나, 운영 환경에서 중요한 데이터를 다뤄야할 때 난관에 봉착할 수 있습니다. 국내 사용자가 (아직은) 많지 않으므로 공식 문서와 dbt slack 커뮤니티 등을 이용해서 답을 찾아 나가야 합니다.
- 개발 문화: 결국 dbt에서 가장 중요한 건 Analytics Engineering이 조직의 문화와 현재 상황에 잘 맞는 가? 라는 질문이라고 생각합니다. 분석가와 데이터를 다루는 누구나 반복되는 업무와 밀려들어오는 요청으로 인해 재사용성과 테스트 등의 우선순위가 떨어질 수 있습니다. dbt를 도입하는 것은 많은 문제를 해결할 수 있으나, 은총알은 아니기에 많은 고민이 필요한 영역이라고 생각합니다.
dbt라는 기술이 최근 데이터 엔지니어링 트렌드가 되어가고 있는 거 같습니다. 하지만 (어떤 기술이 그러하듯,) 이 기술을 실제로 적용하고 규모가 있는 조직에서 사용하기 위해서는 생각보다 정말 많은 고려를 해야 하고 노력이 필요하다는 점을 다시 한번 느끼게 되었습니다. 물론 비용을 지불해서 dbt Cloud를 통해서 이런 과정들을 간소화할 수 있지만, 기술들을 도입하기 전에 마일스톤들을 잘 만들어 두는 것이 필요하다고 생각합니다.
특정 기술을 도입한다고 해서 Analytics Engineering이 해결하려고 하는 모던 데이터 인프라의 문제점들을 해소시켜주지는 않는다고 생각합니다. 하지만 이러한 움직임들이 모여서 큰 흐름을 만들어 내리라고 믿습니다.
이 글을 있게 해준 소다 스토어 파티 플래시, 녹스, 디니, 토마스, 그리고 모든 데이터 비즈니스 본부 분들 감사드립니다.
긴 글 읽어주셔서 감사합니다.