목차
1. 개요
안녕하세요 쏘카 개발자 아놀드입니다.
이 글은 쏘카 디자인 시스템 2.0 개발기 2편으로, 컴포넌트 아키텍처/패키지 전략/LLM(Large Language Model) 활용에 대해 작성하였습니다.
1편에서는 시스템 설계, 운영 프로세스, Figma 연동 를 다뤘고, 이번 글에서는 기술적 선택과 구현 경험을 중심으로 정리했습니다. 2편은 “디자인 시스템을 코드로 구현했다”를 넘어, 서비스 환경(Next.js 13~15 혼재, SSR/CSR, 번들러 차이, 팀별 커스텀 요구)에서도 무너지지 않게 만들기 위해 노력한 구조적 선택의 기록을 다뤄보았습니다.
- 컴포넌트는 UI 결합도에 따라 Hook / 객체로 분리했고
- 패키지는 소비 환경의 트리쉐이킹을 기준으로 번들 구조를 설계했으며
- LLM 활용은 ‘프롬프트’가 아니라 지시(Instructions) 고정으로 접근했습니다.
2. 컴포넌트 아키텍처
2.1 설계 목적
컴포넌트 설계에서 가장 중요하게 본 건 재사용성과 독립성이었습니다.
과거의 경험을 바탕으로 UI는 계속 바뀌는데 그때마다 내부 로직까지 흔들리면 유지보수 비용이 너무 커지기 때문에, 최대한 UI와 로직을 분리하는 구조를 고민했습니다.
이 과정에서 오픈소스 라이브러리들의 설계를 많이 참고하며 실제 서비스 운영과 유지보수에 유리한 구조를 기준으로 선택했습니다.
2.2 Hook과 객체
구체적인 방향은 UI와 상태가 강하게 얽히는 컴포넌트와 그렇지 않은 컴포넌트를 나누는 것이었습니다.
기존 컴포넌트들이 재활용되기 어려웠던 가장 큰 이유가, UI 정책과 비즈니스 로직이 섞여 있던 경험이었기 때문입니다.
UI/UX 정책과 비즈니스 로직을 분리하지 않으면, 동일 정책의 UI를 서비스별로 다시 만들게 됩니다. 과거에 그런 경험이 있었기 때문에 구조를 먼저 정리하려 했습니다.
그래서 “UI가 꼭 가져야 하는 상태인가, 아니면 정책 로직으로 분리 가능한가”를 기준으로 구조를 나눴습니다.
결정 규칙
- 상태 전이가 곧 애니메이션/제스처 제어라면 →
Hook 중심 - 정책 로직이 UI보다 복잡하고 테스트가 중요하다면 →
객체(core) + Hook Adapter
강결합되는 컴포넌트는 Hook 중심으로 설계했고, 그렇지 않은 컴포넌트는 로직을 객체로 분리한 뒤 Hook을 어댑터로 두는 방식으로 UI를 분리했습니다.
UI와 상태가 강하게 엮이는 대표 사례가 BottomSheet와 Accordion입니다.

BottomSheet는 드래그/스냅 포인트/바운드/스크롤 잠금 같은 상호작용이 UI와 분리되기 어렵고, 상태 전이가 곧 UI 애니메이션이라 Hook 중심 구조가 자연스럽다고 봤습니다.
따라서, 설계 단계에서 디자이너/네이티브와 충분히 논의한 끝에 상태(hidden, tip, half, max)를 정의했습니다.
아래 일부 발췌된 코드를 참고하면 상태가 UI에 강하게 얽혀있다는 것이 어떤 의미인지 파악할 수 있습니다.
// BottomSheet의 상태에 해당하는 case가 innerHeight와 얽혀있는 모습
export const resolveTargetY = ({
half,
max,
state,
tip,
}: {
half: number;
max: number;
state: BottomSheetState;
tip: number;
}) => {
switch (state) {
case "max":
return window.innerHeight - max;
case "tip":
return window.innerHeight - tip;
case "half":
return window.innerHeight - half;
case "hidden":
default:
return window.innerHeight;
}
};
// 생략..
//이 상태를 활용하여 animate를 시키는 메서드
const animateToState = (state: BottomSheetState) => {
const normalized = normalizeState(state);
const targetY = resolveTargetY({
half,
max,
state: normalized,
tip,
});
animate(bottomSheetY, targetY, SPRING_TRANSITION);
};
// 생략..
// 기타 복잡한 제어들이 상태에 연결될 수 밖에 없는 형태
const setState = (next: BottomSheetState) => {
const normalizedNext = normalizeState(next);
const current = activeStateRef.current;
if (current === normalizedNext) {
animateToState(normalizedNext);
return;
}
activeStateRef.current = normalizedNext;
if (!isControlled) {
setInternalState(normalizedNext);
}
animateToState(normalizedNext);
onStateChange?.(normalizedNext);
};
더 많은 요구사항이 있을 경우 상태머신이나 아래 다른 예제와 같이 별도 객체로 분리하는 것을 고려해볼 수 있었으나, 현재 단계에서는 Hook으로 충분하다고 보았고 이미 서비스들에서 요구하는 많은 케이스들을 감당할 만한 정책이라고 결론냈습니다.
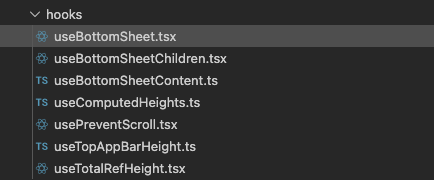
전체 구조는 사진과 같이 useBottomSheet.tsx에서 다양한 Hook을 orchestration하여 활용하였습니다.
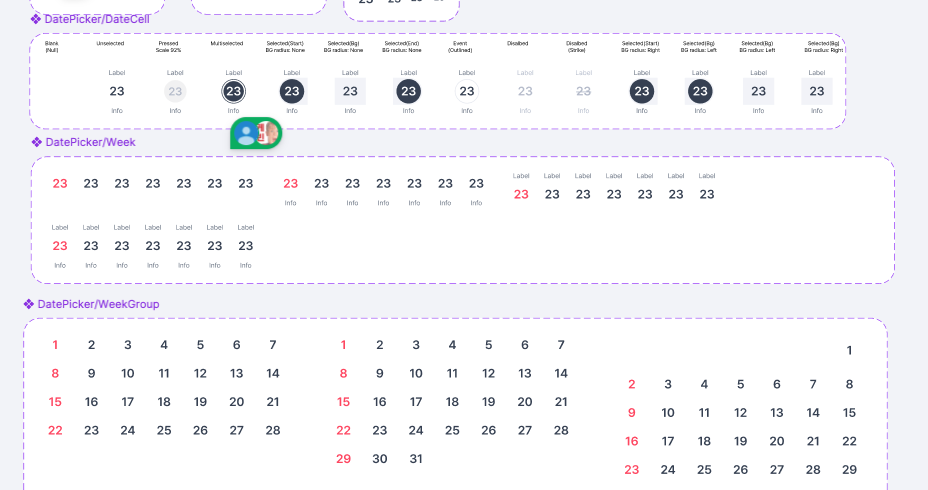
반대로 DatePicker나 Pattern(Carousel)은 UI보다 정책 로직이 훨씬 복잡하다고 봤습니다.

예를 들어 DatePicker는 사용자에게는 start/end 선택 UI만 보입니다. 하지만 내부적으로는 날짜 계산, 라벨 처리, 비활성 정책 등 UI와 직접 연결되지 않는 로직이 많았습니다.
그래서 이런 로직은 아래와 같이 객체로 분리하였습니다.
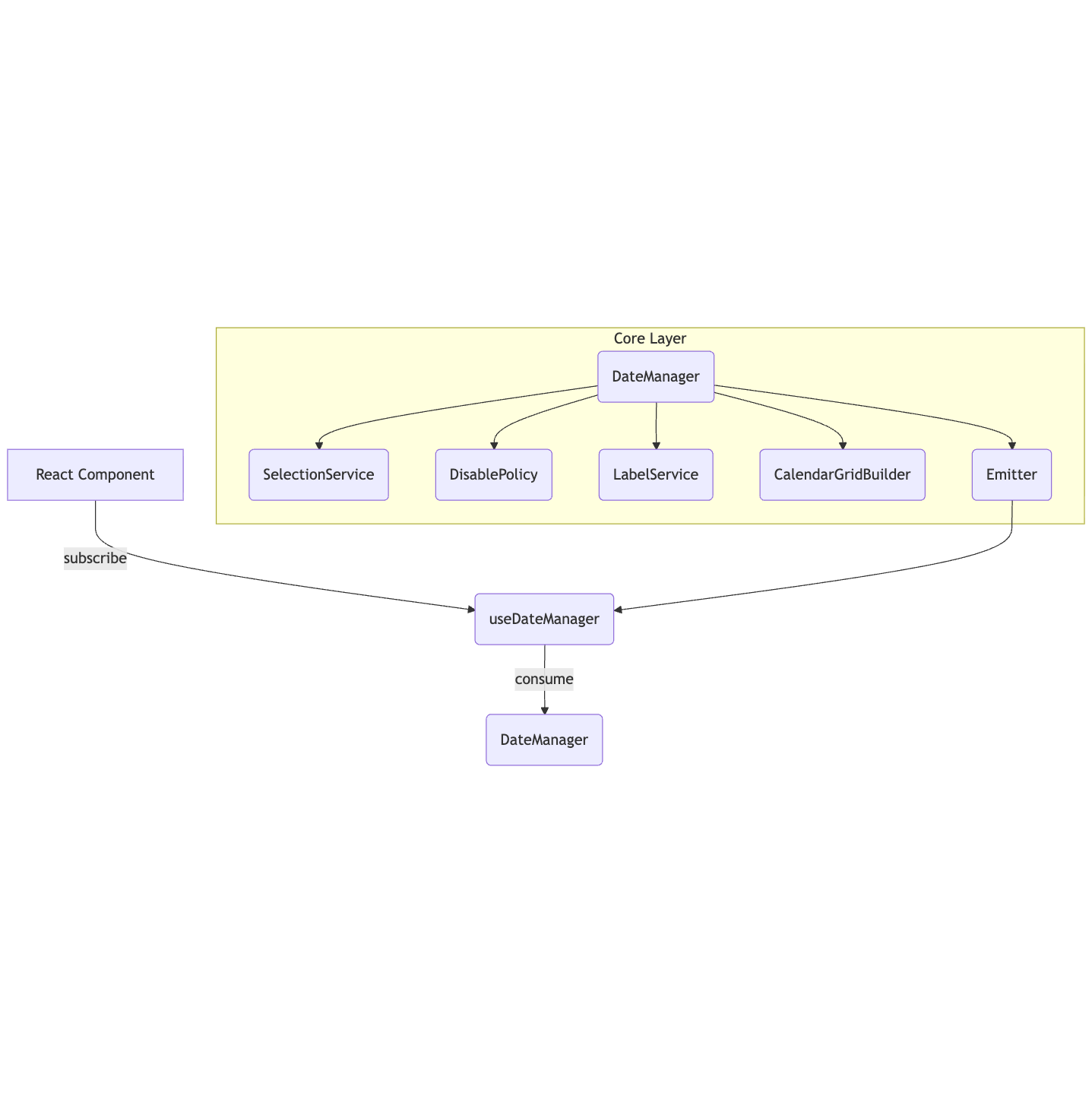
// core/DateManager.ts
export class DateManager {
constructor(today = new Date(), options: DateManagerOptions = {}) {
this.labelService = new LabelService({
generateId: (date) => this.generateId(date),
getHolidays: () => this.holidays,
getToday: () => this.today,
isSameDate: (a, b) => this.isSameDate(a, b),
});
this.disablePolicy = new DisablePolicy({
compareDates: (d1, d2) => this.compareDates(d1, d2),
getDisablePast: () => this.disablePast,
getHolidays: () => this.holidays,
getManualDisabledDates: () => this.manualDisabledDates,
getSelectableEnd: () => this.selectableEnd,
getSelectableStart: () => this.selectableStart,
getToday: () => this.today,
isSameDate: (a, b) => this.isSameDate(a, b),
});
this.gridBuilder = new CalendarGridBuilder({
compareDates: (d1, d2) => this.compareDates(d1, d2),
disablePolicy: this.disablePolicy,
labelService: this.labelService,
todayProvider: () => this.today,
});
this.selectionService = new SelectionService({
applyMaxRangeDays: (target) => this.applyMaxRangeDays(target),
compareDates: (d1, d2) => this.compareDates(d1, d2),
disablePolicy: this.disablePolicy,
emitChange: () => this.emitChange(),
generateId: (date) => this.generateId(date),
getDateMap: () => this.dateMap,
getNodeById: (id) => this.dateMap.get(id),
isFlushApply: () => this.isFlushApply,
labelService: this.labelService,
resetAllSelections: () => this.resetAllSelections(),
setFlushApply: (value) => {
this.isFlushApply = value;
},
updateDateObject: (id, updates) => this.updateDateObject(id, updates),
withDuplicate: options.withDuplicate ?? false,
});
}
// 생략...
select(date: Date) {
this.selectionService?.select(date);
}
}
중간에 Hook으로 Adapter를 두어 React의 라이프사이클을 안정적으로 따르게 하였습니다.
// hooks/useDateManager.ts
export const useDateManager = (
manager: DateManager,
initialSetting?: () => void,
) => {
const [calendarMap, setCalendarMap] = useState<CalendarMap | null>(null);
useEffect(() => {
setCalendarMap(
new Map(manager.getDateGridFromMap(manager.dateMap, manager.dateRecords)),
);
const unsubscribe = manager.subscribe(() => {
setCalendarMap(
new Map(
manager.getDateGridFromMap(manager.dateMap, manager.dateRecords),
),
);
});
initialSetting?.();
return () => unsubscribe();
}, [manager]);
const handleSelect = (date: Date) => manager.select(date);
return { calendarMap, handleSelect };
};
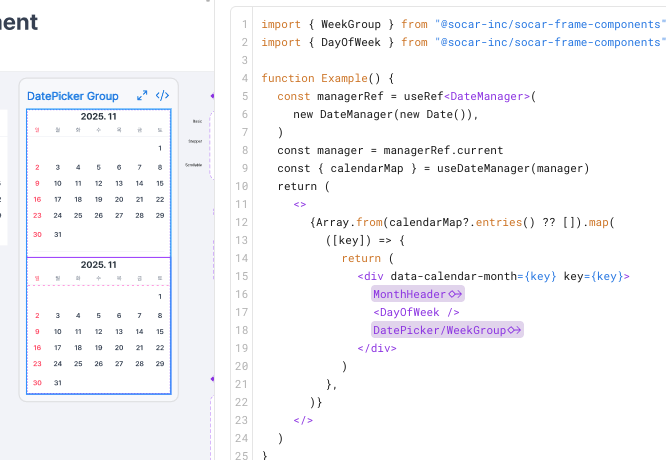
그리고 그 결과를 UI로 emit하는 역할만 하도록 구성했습니다.
// DatePicker 사용부 (stories 예시)
const managerRef = useRef(new DateManager(undefined, { withDuplicate: true }));
const { calendarMap, handleSelect } = useDateManager(managerRef.current, () => {
managerRef.current.setMonthCount(0, 2);
managerRef.current.setCustomLabel([
{ date: new Date("2025-12-25"), labelConfig: { label: "christmas" } },
]);
});
return (
<>
{Array.from(calendarMap?.entries() ?? []).map(([key, weeks]) => (
<WeekGroup key={key} weeks={weeks} handleSelect={handleSelect} />
))}
</>
);
물론 이런 구조는 러닝커브와 복잡도를 높이는 단점이 있습니다.
하지만 테스트 가능성과 정책 재사용성 측면에서는 그 비용을 상쇄할 수 있다고 봤고, 실제로 유지보수 관점에서도 더 안정적인 구조가 된다고 느꼈습니다.
2.3 합성 컴포넌트와 명령형 API
합성형 컴포넌트
많은 UI 라이브러리에서 사용하는 JSX 합성 패턴을 그대로 가져가면서, 최대한 자율적으로 조합할 수 있게 했습니다. 특히 data attribute를 적절히 배치해 pseudo class로 커스텀 스타일링이 가능하도록 설계했습니다.
<Tab
className="
[&_[data-slot=tab-container]]:tw-bg-gray-50
[&_[data-slot=tab-indicator]]:tw-bg-red-500
[&_[data-slot=tabs-content-slide]]:tw-rounded-radius-300
"
>
<Tab.Header>
<Tab.HeaderItem>택시</Tab.HeaderItem>
<Tab.HeaderItem>카페</Tab.HeaderItem>
</Tab.Header>
<Tab.Indicator />
<Tab.Content>
<Tab.ContentItem>콘텐츠 A</Tab.ContentItem>
<Tab.ContentItem>콘텐츠 B</Tab.ContentItem>
</Tab.Content>
</Tab>
라이브러리 1차 개발이 끝나기도 전에 몇몇 서비스에서 선반영이 진행됐기 때문에, 중간중간 패치로 대응하기보다는 개발자가 스스로 조정할 수 있는 여지를 넓혀주는 쪽이 더 적합하다고 봤습니다.서비스팀이 안전하게 커스텀할 수 있도록 확장 지점을 data-attribute로 지원하며 스타일링 접근을 권장했습니다
명령형 API
Alert는 상태나 단계에 따라 다른 UI/로직이 필요한 경우가 많았습니다. 단계가 늘어날수록 상태 분기와 콜백 흐름이 꼬이고, 코드만 봐서는 전체 흐름을 파악하기 어려워지는 문제가 있었기 때문입니다.
그래서 Alert.open을 통해 Alert를 열고, 버튼 클릭 결과를 Promise로 받는 패턴을 제공했습니다. 이렇게 하면 UI 내부에서 상태를 계속 갱신하기보다, 호출부에서 결과에 따라 분기하는 흐름을 만들 수 있습니다.
import {
ActionButton,
Alert,
IconExclamationCircleFill,
type OnAction,
} from "@socar-inc/socar-frame-components";
const BasicAlert = ({ onAction }: { onAction: OnAction }) => {
return (
<Alert withDim>
<Alert.GraphicSlot graphicHeight={120}>
<IconExclamationCircleFill
className="tw-fill-status-caution-regular"
size={48}
/>
</Alert.GraphicSlot>
<Alert.Title>알럿 타이틀</Alert.Title>
<Alert.Body>상세 설명이 들어갑니다.</Alert.Body>
<Alert.LinkButton
label="버튼명"
onClick={() => onAction("link")}
size="small"
type="button"
underline
variant="primary"
/>
<Alert.ButtonSlot>
<ActionButton
className="tw-w-full"
label="확인"
onClick={() => onAction("confirm")}
size="medium"
type="button"
variant="primary"
/>
<ActionButton
className="tw-w-full"
label="취소"
onClick={() => onAction("cancel")}
size="medium"
type="button"
variant="secondary"
/>
</Alert.ButtonSlot>
</Alert>
);
};
const handleConfirm = async () => {
console.log("확인 클릭됨");
};
const handleCancel = async () => {
console.log("취소 클릭됨");
};
const handleLink = async () => {
console.log("링크 클릭됨");
};
export const DefaultAlertExample = () => {
const handleClick = async () => {
const result = await Alert.open((onAction) => (
<BasicAlert onAction={onAction} />
));
if (result === "confirm") await handleConfirm();
if (result === "cancel") await handleCancel();
if (result === "link") await handleLink();
};
return (
<>
<ActionButton
label="Default Alert 열기"
onClick={handleClick}
size="medium"
type="button"
variant="primary"
/>
</>
);
};
물론 단계가 많아지면 여전히 콜백/분기 코드가 길어질 수 있습니다.
하지만 상태를 계속 바꾸면서 UI를 조작하는 방식보다, UI를 열고 결과에 따라 처리하는 흐름이 더 명확하다고 느꼈습니다.
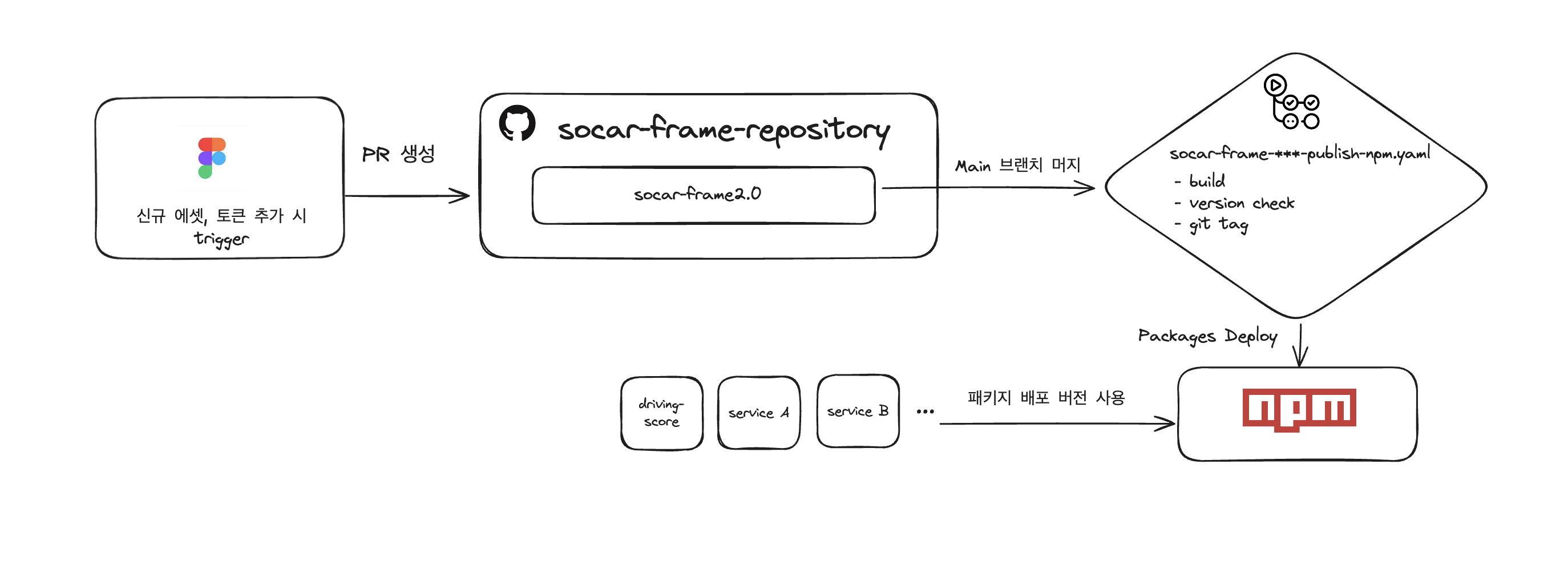
3. 패키지 전략
3.1 트리쉐이킹
다른 UI 라이브러리들과 유사하게 데드 코드를 제거할 수 있는 환경을 제공하였습니다.
초기에는 tsup 기반 번들링으로 개발했는데, 모듈 구조가 유지되지 않아 트리쉐이킹에 불리한 점이 있었습니다.
그래서 components 패키지는 rollup으로 전환했고, preserveModules / preserveModulesRoot를 통해 서비스 번들러가 트리쉐이킹을 위한 폴더 Graph 생성에 유리한 구조로 변경하였습니다.
rollup으로 변경한 또 다른 이유는 SSR(Server-Side Rendering)에 대한 대응이 있었습니다.
쏘카는 현재 Next.js 13~15 버전들이 혼재되어 서비스에서 활용되고 있었고, 13버전의 기본 CSR(Client-Side Rendering) 지원 형태와 다르게 14~15로 변경되며 use client의 상단부 선언에 대한 니즈가 발생하였습니다.
이 부분을 tsup으로 처리하는 것보다 rollup의 banner 옵션으로 각 출력 모듈 파일 상단에 ‘use client’를 주입하는 방식이 훨씬 단순하다고 봤습니다.
...
const outputBase = {
dir: 'dist/src',
preserveModules: true,
preserveModulesRoot: 'src',
}
...
export default defineConfig([
{
external,
input,
output: [
{
...outputBase,
banner: useClientBanner,
entryFileNames: '[name].js',
format: 'esm',
},
{
...outputBase,
banner: useClientBanner,
entryFileNames: '[name].cjs',
exports: 'named',
format: 'cjs',
},
],
plugins: [
esbuild({
jsx: 'automatic',
minify: false,
target: 'es2018',
tsconfig: 'tsconfig.json',
}),
json(),
],
treeshake: true,
},
...
)]
이렇게 useClientBanner와 preserveModules를 적용한 뒤, 특정 서비스 기준으로 번들 전후 비교를 진행했습니다.
여기서 external은 rollup 번들 단계에서 공통 의존성을 분리해 서비스 번들러의 중복 청크 생성을 줄이기 위한 설정입니다.
결과는 아래와 같이 유의미한 성과를 가져왔습니다.

- 공통 static/chunk의 용량을 1.45mb → 567.07kb 로 약 61%의 감소
- first load js는 373kb → 248kb로 33%의 청크 번들 감소
- external의 효과로 pages_app-xxx.js로 생기는 큰 청크 제거
- preserveModules를 통해 트리쉐이킹 친화적 구조 생성
- 실제 pages와 연결되어 있는 chunk 파일 확인 시 필요한 컴포넌트만 node_modules 안에 빌드된 것 확인
4. AI 활용
4.1 Instructions
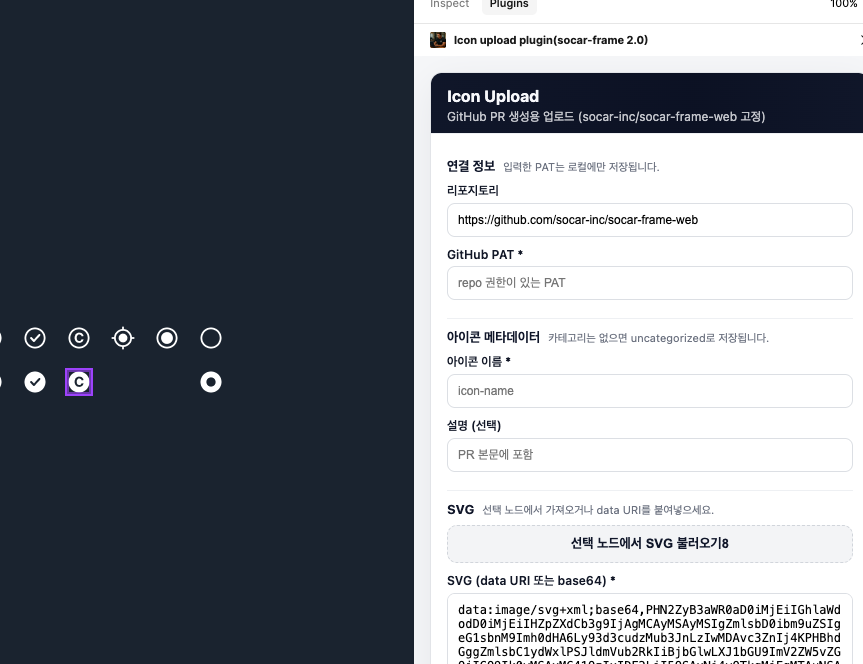
LLM을 잘 활용하려면 사전에 정리된 내용을 명확히 전달하는 것이 중요하다고 생각했습니다. 이 글에서 말하는 Instructions는 LLM에 제공되는 지시 문서입니다. 의도된 결과의 정확도를 높이기 위한 사전 정의 문서로 이해하면 됩니다. 이 Instructions에는 AGENTS.md와 llms.txt의 개념을 활용했습니다. AI를 실무에 쓰려면 “문서가 있다” 수준을 넘어 UI 라이브러리 사용법, Figma 설계 규칙, 예외 처리 기준까지 한 번에 전달돼야 한다고 봤습니다.
그래서 내부 공식 문서 사이트를 통해 정적인 가이드를 제공했고, LLM이 빠르게 맥락을 잡을 수 있도록 llms.txt를 운영했습니다.
llms.txt는 전체 덤프(llms-full.txt), 컴포넌트 인덱스(index.txt)로 연결되어 있어, LLM이 필요한 정보를 단계적으로 찾을 수 있게 구성됩니다.
즉, 문서를 “사람이 읽기 쉬운 형태”로만 두지 않고, LLM이 바로 소비할 수 있는 구조로 별도 정리해 둔 셈입니다.
AGENTS.md에 이 모든 것을 기재할 수도 있으나 각 파일 별 영역을 나누기 위해 이 개념을 나눠 진행하였습니다.
그리하여 실제 서비스 레포에서는 AGENTS.md를 참고 해 라이브러리 사용 규칙과 원칙을 명확히 전달했습니다.
이 작업은 1편에서 언급한 말한 디자이너 → 개발자(라이브러리) → 개발자(서비스) 흐름에서 중간 커뮤니케이션 비용을 줄이기 위한 핵심 축이라고 봤습니다.

디자이너 의도 파악 비용, 개발자 간 UI 정책 확인 비용, PM의 정책 검증 비용을 줄이려면 사전에 합의된 규칙이 문서로 고정되어야 했습니다.
합의된 UI/UX규칙을 명세로 정리해 활용한 뒤, AI로 테스트 코드를 작성하는 과정이 훨씬 수월해지는 걸 경험했습니다. 그 과정에서 규칙의 중요성을 한층 더 체감했습니다.

그래서 UI 라이브러리를 “단순 라이브러리”가 아니라 시스템으로 작동하게 만들기 위한 기반 문서로 llms.txt와 AGENTS.md를 함께 운영하게 되었습니다.
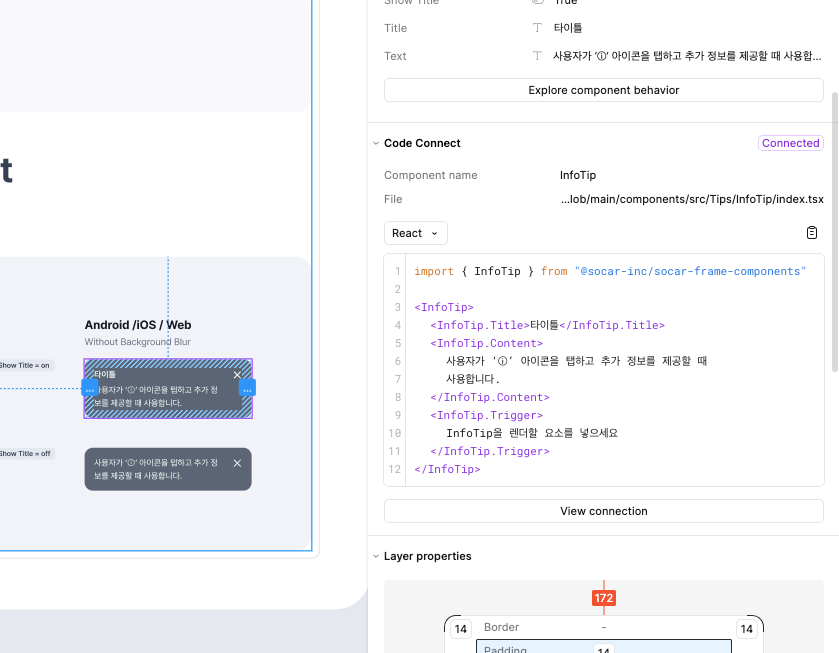
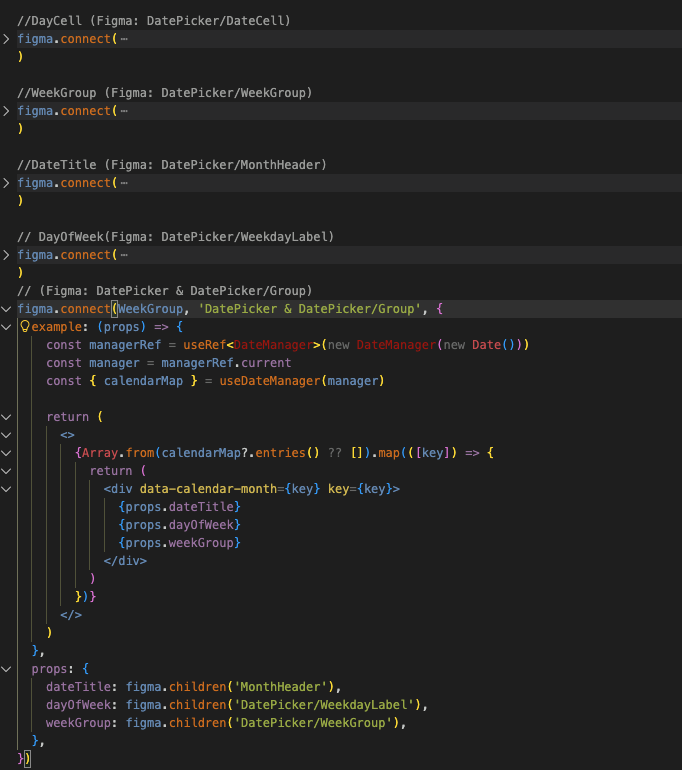
4.2 Figma MCP with LLM
사내 LLM 서비스에 Figma MCP(Model Context Protocol, 공식 사이트)를 접목하면, 에디터 내에서 특정 노드 ID를 기준으로 디자이너 → 개발자(서비스) 흐름을 더 직접적으로 만들 수 있습니다.
즉, 디자이너가 그린 결과물을 개발자가 에디터 안에서 바로 코드로 확인하거나 수정하는 방식으로 연결될 수 있습니다. 다만 이 과정에서 결과 품질은 Instructions와 Figma 설계 방식에 매우 민감하다는 걸 확인했습니다. 같은 디자인이라도 Instructions에 어떤 지시가 들어가 있는지, Figma 안에서 슬롯/상태가 어떻게 정의되어 있는지, hidden 노드가 어떤 방식으로 처리되어 있는지에 따라 결과가 크게 달라졌습니다.
| Instructions 개선 전 결과 | Instructions 개선 후 결과 |
|---|---|
 |
 |
Instructions를 개선한 뒤, 리뷰에서 반복되던 결점(토큰/슬롯/예외 처리)이 크게 줄고 일관성을 갖게 됐습니다. 그래서 이 부분은 단발성으로 끝나는 작업이 아니라, 사례를 계속 쌓고 Instructions와 Figma 설계 규칙을 지속적으로 보완해 나가야 하는 영역이라고 봤습니다.
또한 개발자의 세세한 리뷰를 반영하거나 비즈니스 로직 반영 기준을 정책화하는 것을 추후 개선점으로 가져갈 예정입니다.
5. 후기
개인적으로 가장 큰 수확은 컴포넌트 설계 방식과 번들 구조에 대해 깊게 고민해 본 경험이었습니다.
BottomSheet처럼 UI와 상태가 강결합된 컴포넌트와, DatePicker처럼 로직을 분리해야 하는 컴포넌트를 나누어 설계하면서 재사용성과 테스트 가능성에 대한 관점을 다시 정리할 수 있었습니다.
LLM 친화적인 환경을 만들기 위한 고민은 AI 시대에 의미 있는 경험이었습니다. AGENTS.md와 llms.txt 같은 instruction 체계를 어떻게 구성해야 “문서가 아닌 실질적인 가이드”가 되는지, 그리고 Figma 설계 규칙과 어떻게 맞물려야 하는지 시행착오를 겪었습니다. 이 과정에서 “기술보다 먼저 합의되어야 하는 규칙”이 얼마나 중요한지도 체감했습니다.
아직 쏘카프레임 2.0에는 상위 버전 대응을 위한 의존 패키지 업그레이드, AI·Figma 플러그인 보강 등 남은 과제가 있습니다.
그럼에도 1차 UI 개발과 시스템 기반을 마련한 것은 큰 진전이었고, 쏘카의 클라이언트 개발이 어떤 방향으로 디자인 시스템을 고민했는지 공유할 수 있어 의미 있는 기록이라고 생각합니다.
6 공식 문서
관심 있으신 분들의 참고를 위해 디자인시스템 공식문서를 공유드립니다.
라이브러리 패키지는 private이지만, 설계 원칙/사용 규칙/문서 구조는 외부 공개 가능한 범위에서 공유합니다. (보안/내부 의존성이 있는 세부 구현은 비공개 처리 되었습니다.)
]]>